Clear Sky Science · it
Un ampio dataset europeo su una coorte di pazienti con cancro colorettale
Perché è importante una banca dati condivisa sul cancro
Il cancro colorettale è uno dei tumori più letali al mondo, eppure i medici faticano ancora a prevedere quali pazienti avranno un buon decorso e chi necessita di terapie aggiuntive. Questo articolo descrive un grande sforzo europeo volto a raccogliere informazioni dettagliate provenienti da oltre diecimila pazienti in un’unica risorsa accuratamente controllata. Armonizzando cartelle cliniche, campioni tissutali, immagini al microscopio e dati sul DNA provenienti da molti Paesi, il progetto crea una base potente per diagnosi più precoci, terapie più mirate e nuovi strumenti assistiti dal computer per la cura del cancro.
Un impegno paneuropeo contro un tumore comune
Il cancro colorettale si sviluppa lentamente, spesso nell’arco di anni, perciò è un obiettivo ideale per screening e prevenzione. I test attuali vanno da semplici controlli su campioni fecali a procedure più invasive come l’endoscopia, e i medici valutano anche alterazioni genetiche e altri “biomarcatori” per orientare le cure. Tuttavia, pochi biomarcatori sono consolidati in clinica e restano molte questioni aperte, per esempio sul trattamento migliore per pazienti con stadi intermedi della malattia. Per colmare queste lacune, la Biobanking and Biomolecular Resources Research Infrastructure (BBMRI-ERIC) ha coordinato 26 biobanche in 12 Paesi europei per costruire una coorte condivisa sul cancro colorettale comprendente 10.780 pazienti, tutti con informazioni di base standardizzate e campioni biologici collegati.
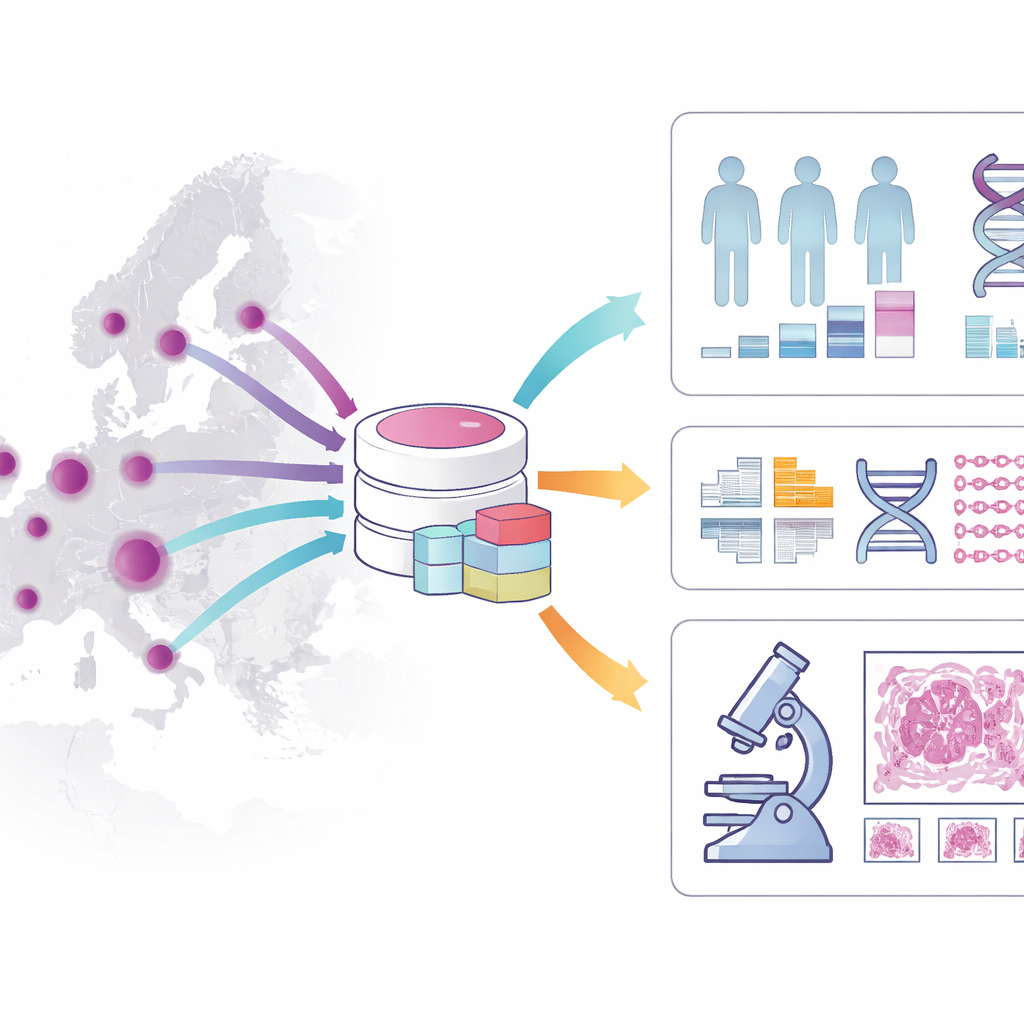
Che cosa contiene esattamente la coorte?
La coorte traccia un quadro ricco del percorso di ogni paziente. Include età, sesso, dettagli della diagnosi, fattori di rischio, terapie ricevute e sopravvivenza a lungo termine, con particolare attenzione ai pazienti seguiti per almeno cinque anni. Conserva informazioni sull’aspetto del tumore al microscopio, sullo stadio della malattia e su caratteristiche molecolari chiave come alcune mutazioni geniche e problemi nella riparazione del DNA. Oltre a questi dati clinici, il dataset è collegato a campioni tissutali conservati nelle biobanche ospedaliere, a oltre tremila vetrini digitali ad alta risoluzione di tumori del colon e a dati di sequenziamento dell’intero genoma per centinaia di pazienti. Insieme, questi livelli permettono di mettere in relazione ciò che i patologi osservano, le informazioni che emergono dal DNA e l’andamento reale dei pazienti nel tempo.
Trasformare registrazioni frammentate in una risorsa coerente
Realizzare una risorsa di questo tipo non è stato affatto semplice. Ogni biobanca conservava inizialmente le informazioni nei propri formati, spesso in fogli di calcolo semplici, e seguiva regole e standard tecnici locali differenti. I team di progetto hanno progettato un modello dati comune attraverso ripetute discussioni tra medici, patologi, esperti IT e personale delle biobanche, concordando quali informazioni fossero essenziali e come dovessero essere definite. Hanno poi creato strumenti software per convertire le diverse tabelle locali in un formato unico e strutturato e per mappare i dati sugli standard sanitari più diffusi. Esprimendo le stesse informazioni in formati come openEHR, OMOP e FHIR, la coorte diventa comprensibile a molti sistemi ospedalieri e piattaforme di ricerca, ampliandone l’utilizzo e il riuso.
Mantenere i dati accurati, privati e utili
Poiché i dati provenivano dalla pratica clinica quotidiana e da molte istituzioni, qualità e privacy sono state preoccupazioni centrali. Ogni record è stato privato di identificatori personali diretti prima del trasferimento, sostituendo ogni paziente con un ID codificato che solo la biobanca d’origine può ricondurre a una persona. Controlli automatizzati verificano che date, età, stadi tumorali e trattamenti siano plausibili e coerenti; voci sospette, come un intervento chirurgico dopo una data di morte segnalata, attivano un feedback alla biobanca contribuente per la correzione. L’articolo descrive anche una procedura strutturata di accesso: ricercatori di tutto il mondo possono richiedere l’uso della coorte, ma un comitato dedicato esamina ogni richiesta per l’approvazione etica, la minimizzazione dei dati e l’aderenza allo scopo della coorte. Le biobanche mantengono il diritto di opporsi se la condivisione confligge con normative locali o regole di consenso.
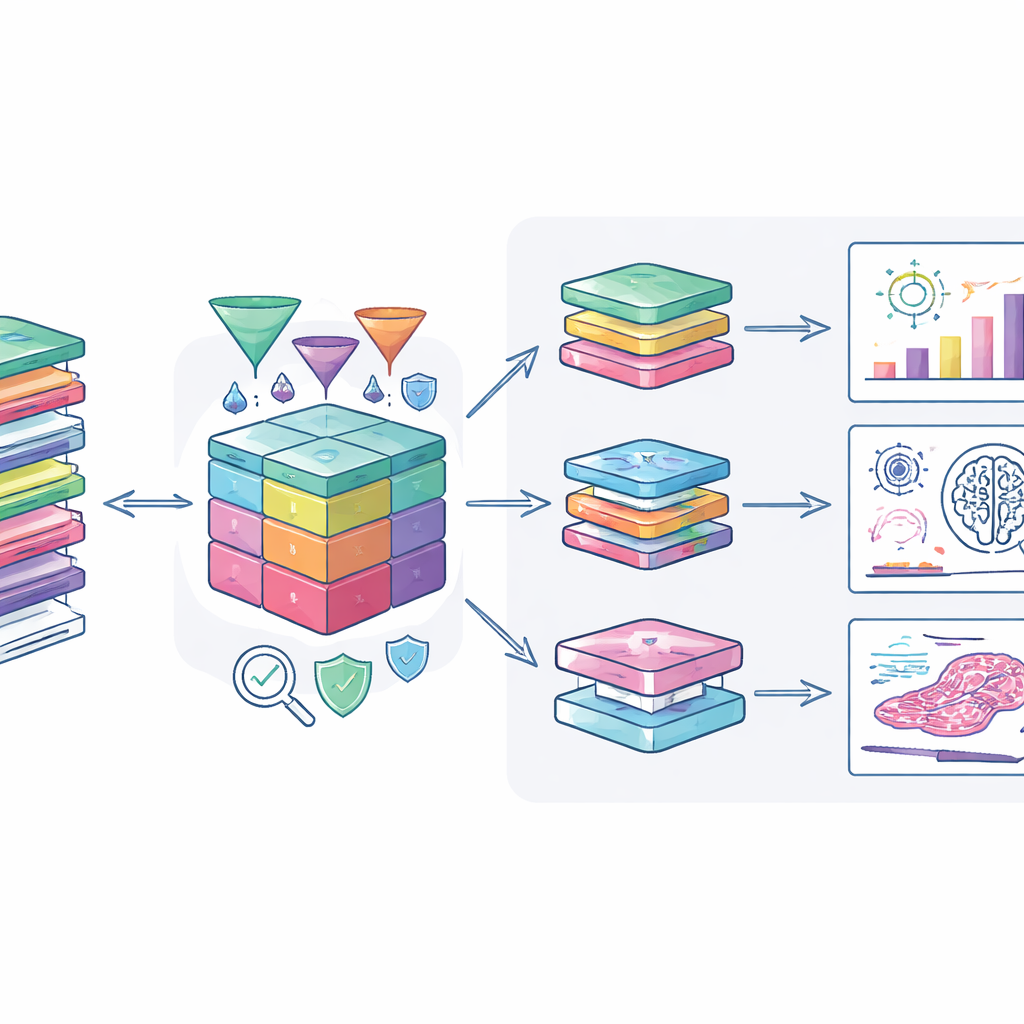
Come i ricercatori possono sfruttarla
Gli autori hanno collegato il dataset a strumenti di analisi moderni in modo che gli utenti autorizzati possano esplorarli in sicurezza. Un portale web specializzato consente la visualizzazione combinata di dati clinici, alterazioni genetiche e immagini di patologia digitale, supportando studi che vanno dalla ricerca di nuovi biomarcatori all’addestramento di sistemi di intelligenza artificiale per riconoscere pattern tumorali. Sistemi di trasferimento sicuro e cifratura proteggono i dati quando vengono spostati negli ambienti di calcolo dei ricercatori. Il team incoraggia inoltre gli investigatori a restituire i risultati derivati, come nuovi punteggi di rischio o metodi di anonimizzazione, in modo che la coorte aumenti continuamente il suo valore.
Cosa significa per i pazienti e per la medicina
Per il pubblico non specialistico, il messaggio chiave è che questo progetto ha creato una «biblioteca di riferimento» condivisa e di alta qualità di casi reali di cancro colorettale in Europa. Invece di ospedali che lavorano con piccoli dataset isolati, gli scienziati possono ora studiare pattern su migliaia di pazienti, confrontare i risultati su popolazioni diverse e testare nuovi strumenti diagnostici in modo robusto. Pur non fornendo di per sé un singolo nuovo test o farmaco, la coorte pone le basi per una diagnosi più precoce, terapie più personalizzate e un uso migliore dell’intelligenza artificiale in patologia. In termini pratici, questo tipo di condivisione di dati governata con attenzione può accelerare scoperte che un giorno potrebbero aiutare i medici a decidere chi ha davvero bisogno di chemioterapia, chi può evitarla in sicurezza e come intercettare tumori pericolosi prima che si diffondano.
Citazione: Holub, P., Törnwall, O., Garcia Alvarez, E. et al. A comprehensive European Colorectal Cancer Cohort dataset. Sci Data 13, 662 (2026). https://doi.org/10.1038/s41597-026-06822-2
Parole chiave: cancro colorettale, dati di biobanca, patologia digitale, coorte genomica, condivisione di dati medici