Clear Sky Science · tr
Moleküler derin öğrenme: kimyasal uzayın sınırında
Neden daha akıllı ilaç tahminleri önemli?
Modern ilaç keşfi, devasa kimyasal kütüphaneleri eleyip umut vaat eden adayları işaretlemek için giderek daha çok yapay zekâya dayanıyor. Ancak bir sorun var: birçok makine öğrenimi modeli yalnızca daha önce gördüklerine çok benzeyen moleküllerde iyi çalışıyor. Çok farklı bileşiklere—ilk sınıf ilaç olma potansiyeli taşıyanlara—yöneltildiğinde, bu modeller aşırı özgüvenli olabilir ve yanlış tahminler yapabilir. Bu çalışma, bir modelin güvensiz olduğu durumları tespit etmenin yeni bir yolunu tanıtıyor; bu sayede araştırmacılar kimyasal uzayın keşfedilmemiş bölgelerine güvenli biçimde ilerleyebiliyor.
Harita tükendiğinde
Erken aşama ilaç keşfinde bilim insanları, hastalıkla ilişkili bir protein gibi biyolojik hedefleri etkileyen küçük moleküller olan “hit”leri ararlar. Milyarlarca olası molekül üzerinde laboratuvar deneyleri yürütmek imkânsız olduğundan, makine öğrenimi modelleri yüzlerce veya binlerce bilinen bileşikten eğitilir ve hangi yeni bileşiklerin test edilmeye değeceğini tahmin etmek için kullanılır. Ancak bu modeller, eğitim verilerindeki moleküllere benzemeyen bileşiklerde bozulma eğilimindedir—buna dağılım kayması denir. Mevcut güvenlik yaklaşımları ya bilinen bölgenin etrafına katı bir sınır çizip daha maceracı molekülleri engelliyor ya da model gerçekten yeni bir şeyle karşılaştığında yanıltıcı olabilen belirsizlik tahminleri kullanıyor.
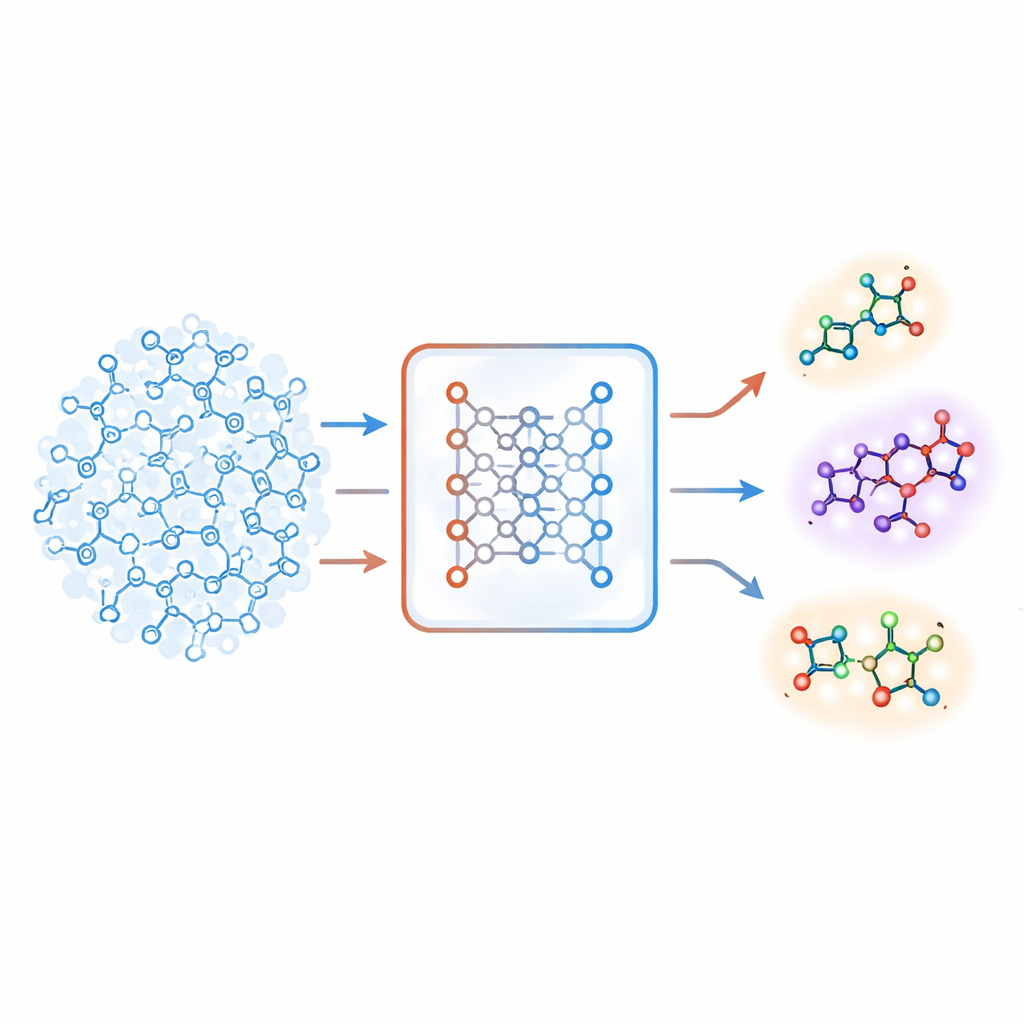
Yabancılığı hissetmenin yeni yolu
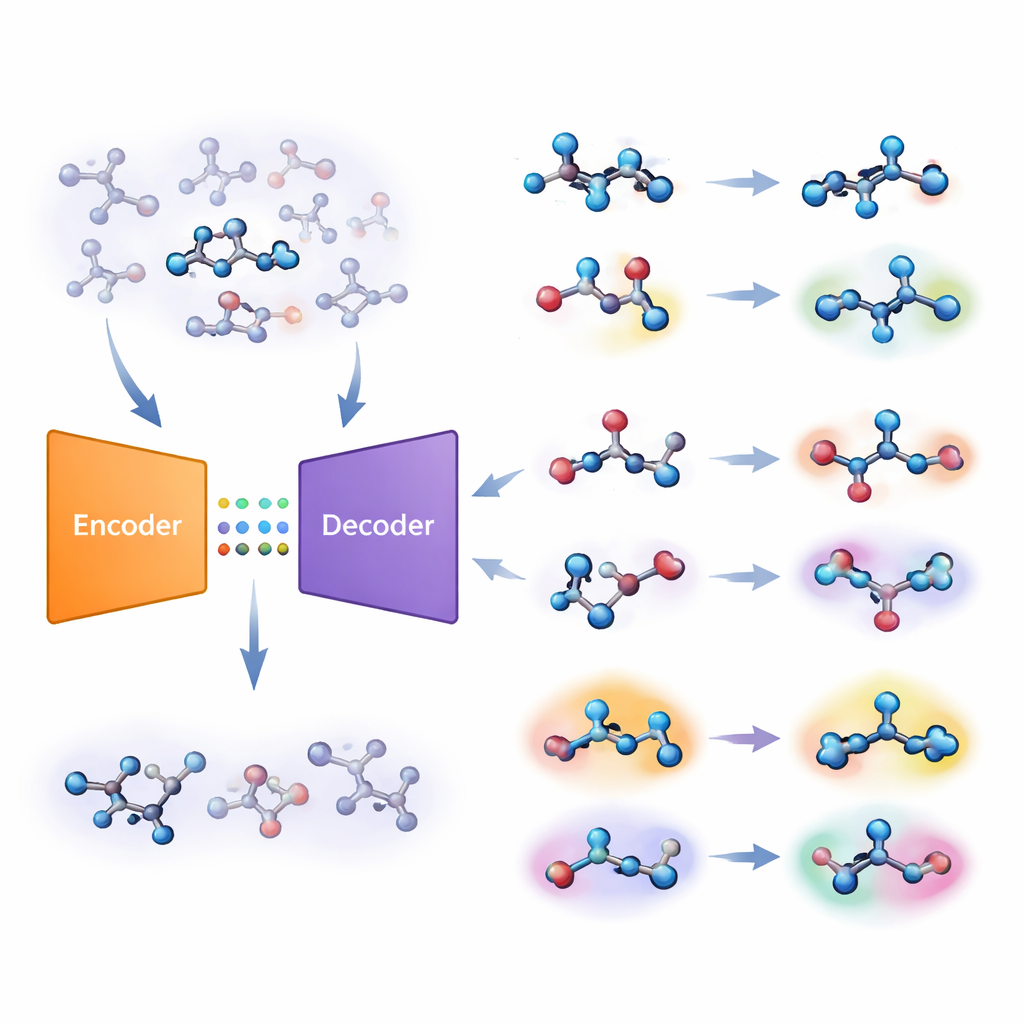
Yazarlar, otoenkoder (autoencoder) adı verilen bir derin öğrenme sistemi türüne dayanan farklı bir strateji öneriyor. Onların “birleşik moleküler modeli” aynı anda iki görevi öğreniyor: bir molekülün bir hedef üzerinde aktif olup olmadığını tahmin etmek ve molekülü sıkıştırılmış iç kodundan yeniden inşa etmek. Model belirli bir molekülü doğru şekilde yeniden kurmakta zorlanırsa, o molekül “yabancı” olarak değerlendirilir. Ekip, bu yeniden yapılandırma hatasını, molekülün modelin gerçekten öğrendiği kimyasal kalıplardan ne kadar uzak olduğunu yansıtan sayısal bir puana, yani yabancılık skoruna dönüştürüyor. Kritik olan nokta, bu skorun basit el yapımı benzerlik ölçülerinden ziyade modelin kendi kimya anlayışı tarafından yönlendirilmesi.
Kimyasal uzayın sınırını test etmek
Yabancılığın bir modelin yetenek sınırını ne kadar iyi saptadığını sınamak için araştırmacılar farklı biyolojik hedefleri ve özellikleri kapsayan 33 veri seti topladı. Her veri setini iyi bilinen örnekler ile yapısal olarak daha olağandışı olanlar halinde ayırmak için kümeleme yöntemleri kullandılar; bu, iyi çalışılmış ve yeni moleküller arasındaki farkı taklit ediyor. Bu kıyaslamalarda, dağılım dışı olarak etiketlenen moleküller tutarlı biçimde daha yüksek yabancılık puanlarına sahipti. Bu etki, molekül boyutu veya karmaşıklığı gibi basit özelliklerle açıklanamadı. Bunun yerine yabancılık, bir molekülün yapısal çekirdeğinin eğitim bileşiklerininkinden ne kadar uzak olduğuyla yakından ilişkiliydi; bu da modelin gerçekten ne kadar “tablonun dışında” olduğunu algıladığını doğruladı.
Belirsizliğin tek başına kaçırabileceklerini görmek
Araştırmacılar daha sonra yabancılığı, model belirsizliği ve çeşitli kimyasal benzerlik ölçümleri de dahil olmak üzere tahmin güvenilirliğini değerlendirmede yaygın kullanılan birkaç yöntemle karşılaştırdı. Hem yabancılık hem de belirsizlik sınıflayıcının performansıyla ilişkiliydi: bu metriklerden herhangi biri yüksek olduğunda tahminler genelde daha az doğruydu. Ancak iki sinyal büyük ölçüde bağımsızdı. Yabancılık hem yapısal uzaklığı hem de performansı yakalarken, yalnızca belirsizlik yapı üzerinde çok iyi bir yansıma sunmuyordu; özellikle moleküller çok farklı bir dağılımdan geldiğinde. Bir milyondan fazla ticari molekülü içeren büyük sanal taramalarda yabancılık, rutin bileşikleri gerçekten yeni olanlardan keskin şekilde ayırdı; oysa belirsizlik iki grup arasında çok az fark gösterdi.
Bilgisayar ekranından ıslak labora
Pratik etkisini göstermek için araştırmacılar, satın alınabilir yaklaşık 180.000 molekül üzerinde öngörücü bir tarama gerçekleştirdi; amaç, PIM1 ve CDK1 adlı iki hastalıkla ilişkili enzimin inhibitörlerini aramaktı. Birleşik modellerini makul büyüklükteki mevcut veri kümeleriyle eğittiler ve sonra yeni bileşikleri üç bileşeni aynı anda kullanarak sıraladılar: tahmin edilen aktivite, model belirsizliği ve yabancılık. Sadece 60 molekülü biyokimyasal testlerde satın alıp test ettikten sonra, eğitim bileşiklerinden ve tipik kinaz inhibitörlerinden yapısal olarak farklı olan yedi düşük mikromolar potansiyelli bileşik keşfettiler. Düşük yabancılığı öne çıkaran stratejiler—yine de belirsizliğe izin verirken—genellikle en güçlü hitleri verdi; bu da yabancılığa dikkat etmenin, tamamen yabancı olmayan ama umut vadeden kimya alanlarına doğru keşfi yönlendirebileceğini gösteriyor.
Geleceğin ilaçları için ne anlama geliyor?
Günlük ifadeyle yabancılık skoru, kimya için makine öğrenimi modellerine ne zaman bildiklerinin çok ötesine genelleme yaptıklarını söyleyen yerleşik bir his veriyor. Bu hissi modelin molekülleri yeniden yapılandırma yeteneğine bağlayarak yaklaşım, aynı anda kimyasal benzerliği ve tahminin güvenilirliğini yansıtıyor. Çalışma, bu metriğin standart yöntemlerin kaçırdığı dağılım kaymalarını ortaya çıkarabildiğini, sanal taramalarda önceliklendirmeyi iyileştirdiğini ve gerçek deneylerde taze kimyasal maddeleri keşfetmeye yardımcı olduğunu gösteriyor. İlaç avcıları kimyasal uzayın geniş, büyük ölçüde keşfedilmemiş bölgelerine gittikçe daha fazla yelken açarken, yabancılık cesur tahminlerin hangilerinin inanılmaya ve laboratuvarda test edilmeye değer olduğunu belirlemede ilkeli bir pusula sunuyor.
Atıf: van Tilborg, D., Rossen, L. & Grisoni, F. Molecular deep learning at the edge of chemical space. Nat Mach Intell 8, 575–587 (2026). https://doi.org/10.1038/s42256-026-01216-w
Anahtar kelimeler: moleküler makine öğrenimi, ilaç keşfi, kimyasal uzay, dağılım dışı, sanal tarama