Clear Sky Science · sv
Djupinlärning för molekyler vid gränsen för kemiskt rum
Varför smartare läkemedelsprognoser spelar roll
Modern läkemedelsupptäckt förlitar sig i allt högre grad på artificiell intelligens för att sålla i enorma kemiska bibliotek och peka ut lovande läkemedelskandidater. Men det finns en knorr: många maskininlärningsmodeller fungerar bara bra på molekyler som liknar dem de redan sett. När de ombeds bedöma mer ovanliga föreningar — de som potentiellt kan bli först-i-sitt-slag-läkemedel — kan modellerna bli överdrivet självsäkra och felaktiga. Denna studie presenterar ett nytt sätt att avgöra när en modell står på hal is, vilket hjälper forskare att säkert söka sig in i outforskade delar av det kemiska rummet.
När kartan tar slut
I tidiga skeden av läkemedelsupptäckt letar forskare efter så kallade ”hits”: små molekyler som påverkar ett biologiskt mål, till exempel ett protein kopplat till sjukdom. Eftersom det är omöjligt att genomföra laboratorieexperiment på miljarder möjliga molekyler tränas maskininlärningsmodeller på några hundra eller tusen kända föreningar och används sedan för att förutsäga vilka nya som är värda att testa. Dessa modeller tenderar dock att haverera på molekyler som skiljer sig från deras träningsdata — ett problem som kallas distribution shift. Befintliga skyddsåtgärder antingen drar en hård gräns runt det kända området, vilket blockerar mer äventyrliga molekyler, eller uppskattar förutsägelseosäkerhet på sätt som fortfarande kan vara vilseledande när modellen möter något verkligen nytt.
En ny känsla för främmande karaktär
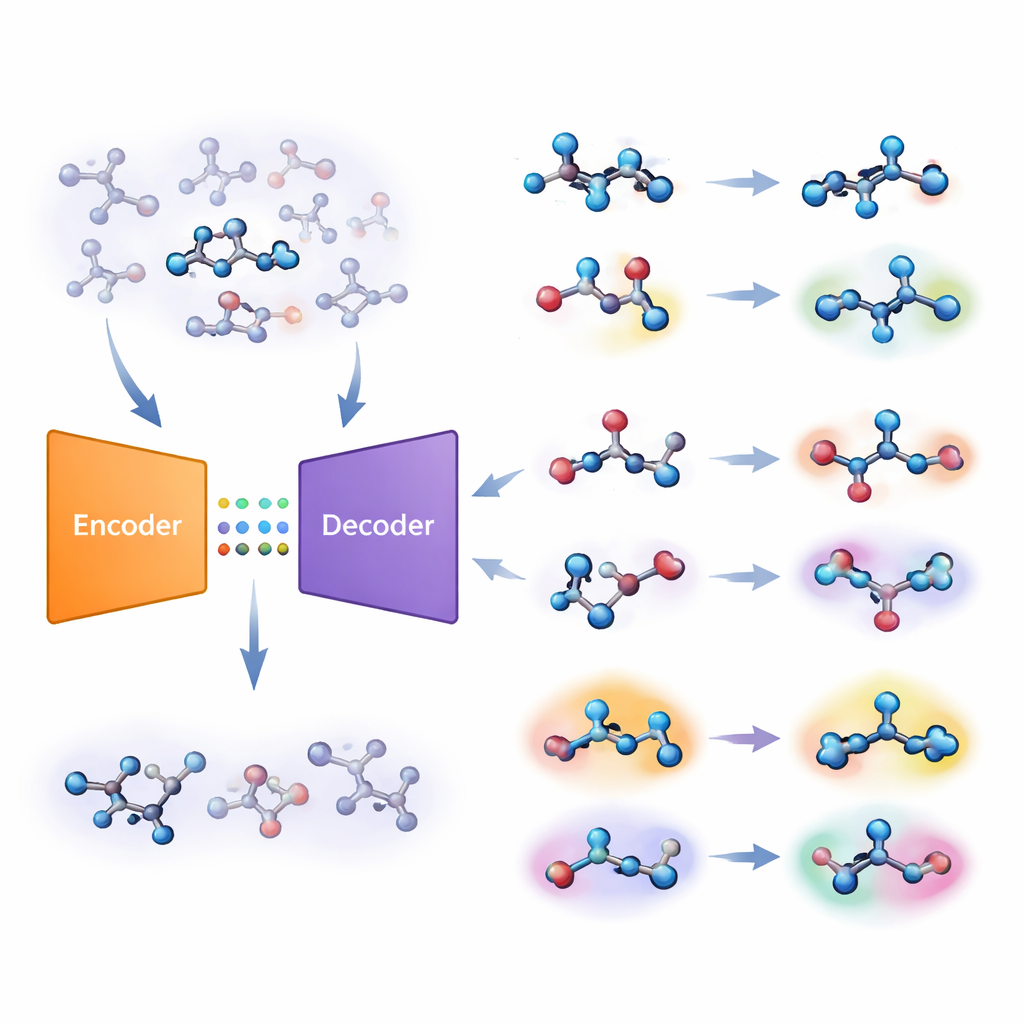
Författarna föreslår en annan strategi baserad på en typ av djupinlärningssystem som kallas autoencoder. Deras ”gemensamma molekylmodell” lär sig två uppgifter samtidigt: att förutsäga om en molekyl är aktiv mot ett mål, och att rekonstruera molekylen från en komprimerad intern kod. Om modellen har svårt att återskapa en viss molekyl på ett korrekt sätt betraktas den som ”främmande”. Teamet omvandlar denna rekonstruktionsfel till en numerisk poäng, kallad unfamiliarity (”främlingskap”), som speglar hur långt en molekyl ligger från de kemiska mönster modellen faktiskt lärt sig. Avgörande är att denna poäng drivs av modellens egen förståelse av kemi snarare än av enkla, handkonstruerade likhetsmått.
Testa gränsen för det kemiska rummet
För att undersöka hur väl unfamiliarity upptäcker när en modell är utanför sin kompetens samlade forskarna 33 dataset som täcker olika biologiska mål och egenskaper. De använde klustringsmetoder för att dela varje dataset i typiska exempel och mer strukturellt ovanliga sådana, vilket efterliknar skillnaden mellan välstuderade och nya molekyler. Över dessa riktmärken hade molekyler markerade som utanför fördelningen konsekvent högre unfamiliarity-poäng. Denna effekt kunde inte förklaras bort av triviala egenskaper som molekylstorlek eller komplexitet. Istället spårade unfamiliarity nära hur långt en molekyls strukturella kärna låg från träningsföreningarnas, vilket bekräftar att modellen effektivt kände av hur ”utanför kartan” en molekyl var.
Vad osäkerhet ensam kan missa
Teamet jämförde därefter unfamiliarity med flera vanliga sätt att bedöma förutsägbarhet, inklusive modellytterlighet (uncertainty) och olika mått på kemisk likhet. Både unfamiliarity och uncertainty var kopplade till hur väl klassificeraren presterade: när någon av metrikerna var hög tenderade förutsägelser att vara mindre precisa. De två signalerna var dock till stor del oberoende. Unfamiliarity fångade både strukturellt avstånd och prestanda, medan osäkerhet ensam inte reflekterade struktur särskilt väl, särskilt när molekyler kom från en mycket annorlunda fördelning. I enorma virtuella screeningar av mer än en miljon kommersiella molekyler skiljde unfamiliarity tydligt rutinmolekyler från verkligt nya, medan osäkerhet föreslog liten skillnad mellan grupperna.
Från datorskärm till våtlaboratorium
För att visa praktisk effekt genomförde forskarna en prospektiv screening av cirka 180 000 köpbara molekyler och sökte efter hämmare av två sjukdomsrelevanta enzymer, PIM1 och CDK1. De tränade sin gemensamma modell på måttliga befintliga dataset och rankade sedan nya föreningar med tre ingredienser samtidigt: förutsagd aktivitet, modellytterlighet och unfamiliarity. Efter att ha köpt och testat endast 60 molekyler i biokemiska assay upptäckte de sju med låg mikromolär potens, alla strukturellt skilda från träningsföreningarna och typiska kinasehämmare. Strategier som favoriserade låg unfamiliarity — samtidigt som de tillät osäkerhet — tenderade att ge de starkaste träffarna, vilket tyder på att uppmärksamhet på unfamiliarity kan styra utforskning mot lovande men inte helt främmande kemi.
Vad detta betyder för framtida mediciner
I vardagliga termer ger unfamiliarity-poängen maskininlärningsmodeller för kemi en inbyggd känsla för när de extrapolerar för långt från det de känner till. Genom att knyta denna känsla till modellens förmåga att rekonstruera molekyler speglar tillvägagångssättet samtidigt kemisk likhet och förutsägelsers pålitlighet. Studien visar att denna metrik kan avslöja distribution shifts som standardmetoder missar, förbättra prioritering i virtuella screeningar och hjälpa till att upptäcka ny kemisk materia i verkliga experiment. När läkemedelsjägare i allt högre grad ger sig ut i det stora, till stora delar ocharted, kemiska rummet erbjuder unfamiliarity en principfast kompass för att avgöra vilka djärva förutsägelser som är värda att tro på — och testa i labbet.
Citering: van Tilborg, D., Rossen, L. & Grisoni, F. Molecular deep learning at the edge of chemical space. Nat Mach Intell 8, 575–587 (2026). https://doi.org/10.1038/s42256-026-01216-w
Nyckelord: molekylär maskininlärning, läkemedelsupptäckt, kemiskt rum, utanför fördelning, virtuell screening