Clear Sky Science · sv
Anpassningsbar regressionsmodell för diagnos av Parkinsons sjukdom från tal-signaler med Box-Cox-baserad klustring och extremt randomisering
Varför att lyssna på röster kan hjälpa upptäcka Parkinson tidigare
Parkinsons sjukdom är mest känd för skakningar och stelhet, men länge innan de symptomen blir tydliga börjar rösten ofta ändras på subtila sätt. Eftersom nästan alla bär en mikrofon i fickan kan dessa förändringar övervakas hemma och göra vanligt tal till ett tidigt varningssystem. Denna artikel undersöker hur man bygger ett smart och pålitligt ”lyssnande” verktyg som använder avancerade datortekniker för att uppskatta hur svåra en persons Parkinsonsymptom är, enbart utifrån rösten.
Förvandla heminspelningar till meningsfulla hälsoklues
Forskarna arbetade med en rik röstdatabas insamlad från 42 personer med tidig Parkinsons sjukdom, som var och en spelade in korta vokalljud hemma under cirka sex månader. Från varje inspelning mätte systemet dussintals egenskaper hos ljudet, såsom hur stabil tonen är från en stämton till nästa (jitter), hur mycket ljudstyrkan svajar (shimmer) och hur brusig eller andningsaktig rösten är. Dessa mätningar har kopplats till hur Parkinson påverkar de muskler som styr talet. Målet var inte bara att avgöra om någon har Parkinson, utan att förutsäga två detaljerade medicinska poäng, kallade Motor-UPDRS och Total-UPDRS, som läkare använder för att bedöma den övergripande symtomsvårigheten.
Rensa upp röriga data så datorer kan förstå dem
Råa röstmätningar kan vara röriga: vissa värden är kraftigt snedfördelade, andra har extrema avvikare, och många är starkt överlappande varianter av samma idé. Om de matas direkt in i en modell kan detta brus förvirra inlärningen och göra resultaten sköra. För att hantera detta använde teamet först ett matematiskt omformningssteg kallat Box–Cox-transformation. Enkelt uttryckt drar detta ut och trycker ihop data så att extrema värden dämpas och den övergripande spridningen liknar en jämn klockform, vilket många inlärningsalgoritmer hanterar bättre. De såg också till att dela upp datan per person snarare än per inspelning, så att datorn aldrig såg samma patient i både träning och testning, vilket undviker illusionen av hög noggrannhet orsakad av att ”komma ihåg” individuella röster.
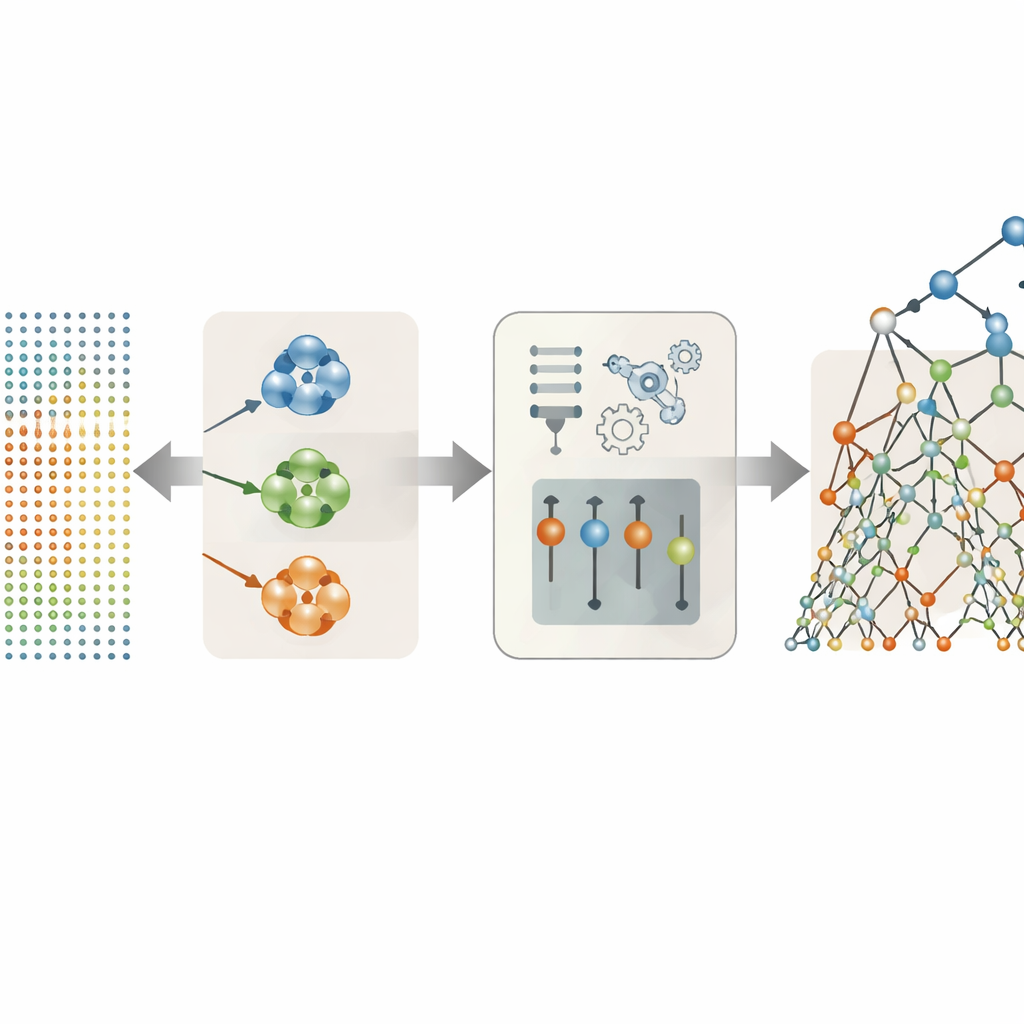
Låta datan avgöra vilka röstegenskaper som verkligen spelar roll
Många av de 26 röstegenskaperna i datasettet är variationer på ett tema — till exempel flera olika sätt att mäta toninstabilitet eller variation i ljudstyrka. Istället för att kasta in dem alla i modellen prövade författarna flera strategier för att behålla endast de mest användbara. Deras mest framgångsrika strategi var att gruppera funktioner som beter sig likartat i kluster och sedan välja en representant från varje kluster baserat på hur starkt den relaterar till symtompoängen. Detta klusterbaserade urval minskade den ursprungliga uppsättningen till bara tre framstående indikatorer: en jitter-mätning, en shimmer-mätning och en mätning av den övergripande röstbrusigheten. Trots denna drastiska förenkling fångade dessa tre noggrant utvalda funktioner det mesta av den medicinska informationen dold i inspelningarna.
Använda randomiserade beslutsträd för att läsa röstsignalerna
Med de strömlinjeformade röstfunktionerna i hand jämförde teamet en rad prediktionsmetoder, från enkla linjära formler till mer flexibla trädmodeller och neuronnätsliknande autoenkodare. Den tydliga vinnaren var en metod kallad Extra Trees, en ensemble av många beslutsträd som vardera delar upp datan på mycket randomiserade sätt. Denna slumpmässighet, kombinerad med den reducerade och mindre redundanta mängden funktioner, hjälpte modellen att undvika överanpassning — att memorera egenheter i träningsdatan istället för att lära sig generella mönster. På hållna patienter förutsade kombinationen klustring plus Extra Trees både Motor- och Total-UPDRS-poäng med anmärkningsvärt hög precision, och matchade uppmätta poäng så nära att skillnaderna typiskt var långt under en poäng på skalor som sträcker sig över hundra poäng.
Vad detta innebär för personer som lever med Parkinson
För en allmän läsare är huvudbudskapet att ett litet antal noggrant valda röstmätningar, bearbetade med en omtänkt inlärningspipeline, kan följa Parkinsons svårighetsgrad med nästan klinisk noggrannhet — med inspelningar gjorda hemma. Även om studien fortfarande bygger på en enda dataset och behöver testas i större, mer varierade patientgrupper, visar den en lovande väg mot praktisk telemedicin: en framtid där en kort röstinspelning kan hjälpa patienter och läkare att följa sjukdomsutvecklingen, justera medicineringar och möjligen upptäcka förvärrade symtom tidigare, allt utan ett besök på kliniken.
Citering: Essam, M., Balat, M., Zaky, A.B. et al. Adaptive regression model for Parkinson’s disease diagnosis from speech signals using Box-Cox-based clustering and extremely randomization. Sci Rep 16, 14044 (2026). https://doi.org/10.1038/s41598-026-49065-2
Nyckelord: Parkinsons sjukdom, röstanalys, maskininlärning, fjärrövervakning, variabelurval