Clear Sky Science · nl
Adaptief regressiemodel voor de diagnose van de ziekte van Parkinson uit spraaksignalen met Box-Cox-gebaseerde clustering en uiterst randomisatie
Waarom naar stemmen luisteren kan helpen Parkinson eerder te ontdekken
De ziekte van Parkinson staat het meest bekend om tremoren en stijfheid, maar lang voordat die symptomen duidelijk worden, verandert de stem vaak op subtiele manieren. Omdat bijna iedereen een microfoon in zijn zak draagt, zouden deze veranderingen thuis bewaakt kunnen worden en gewone spraak in een vroegtijdig waarschuwingssysteem kunnen veranderen. Dit artikel onderzoekt hoe je een slimme, betrouwbare "luister"-tool bouwt die geavanceerde computermethoden gebruikt om uit iemands stem de ernst van Parkinson-symptomen te schatten.
Huismetingen omzetten in betekenisvolle gezondheidsaanwijzingen
De onderzoekers werkten met een rijk spraakbestand verzameld van 42 mensen met Parkinson in een vroeg stadium, die elk korte klinkergeluiden thuis opnamen over ongeveer zes maanden. Uit elke opname mat het systeem tientallen eigenschappen van het geluid, zoals hoe stabiel de toonhoogte is van de ene trilling van de stembanden naar de volgende (jitter), hoezeer het volume schommelt (shimmer) en hoe ruisig of ademend de stem klinkt. Deze metingen zijn gekoppeld aan de manier waarop Parkinson de spieren die spraak aansturen beïnvloedt. Het doel was niet alleen vast te stellen of iemand Parkinson heeft, maar twee gedetailleerde medische scores te voorspellen, genaamd Motor-UPDRS en Total-UPDRS, die artsen gebruiken om de ernst van de symptomen te beoordelen.
Rommelige data opschonen zodat computers ze begrijpen
Ruwe spraakmetingen kunnen rommelig zijn: sommige waarden zijn sterk scheef, andere bevatten extreme uitschieters en veel variabelen overlappen sterk qua betekenis. Als je die direct in een model stopt, kan die rommel het leerproces verwarren en de resultaten fragiel maken. Om dit aan te pakken pasten de onderzoekers eerst een wiskundige herschikking toe, de Box–Cox-transformatie. Simpel gezegd rekent dit de data zo om dat extreme waarden worden getemperd en de spreiding meer op een soepele klokvorm lijkt, wat veel leeralgoritmes beter aankunnen. Ze zorgden er ook voor dat de data per persoon werden gesplitst in plaats van per opname, zodat de computer nooit dezelfde patiënt in zowel training als test zag, en zo de illusie van hoge nauwkeurigheid door het 'onthouden' van individuele stemmen vermijdt.
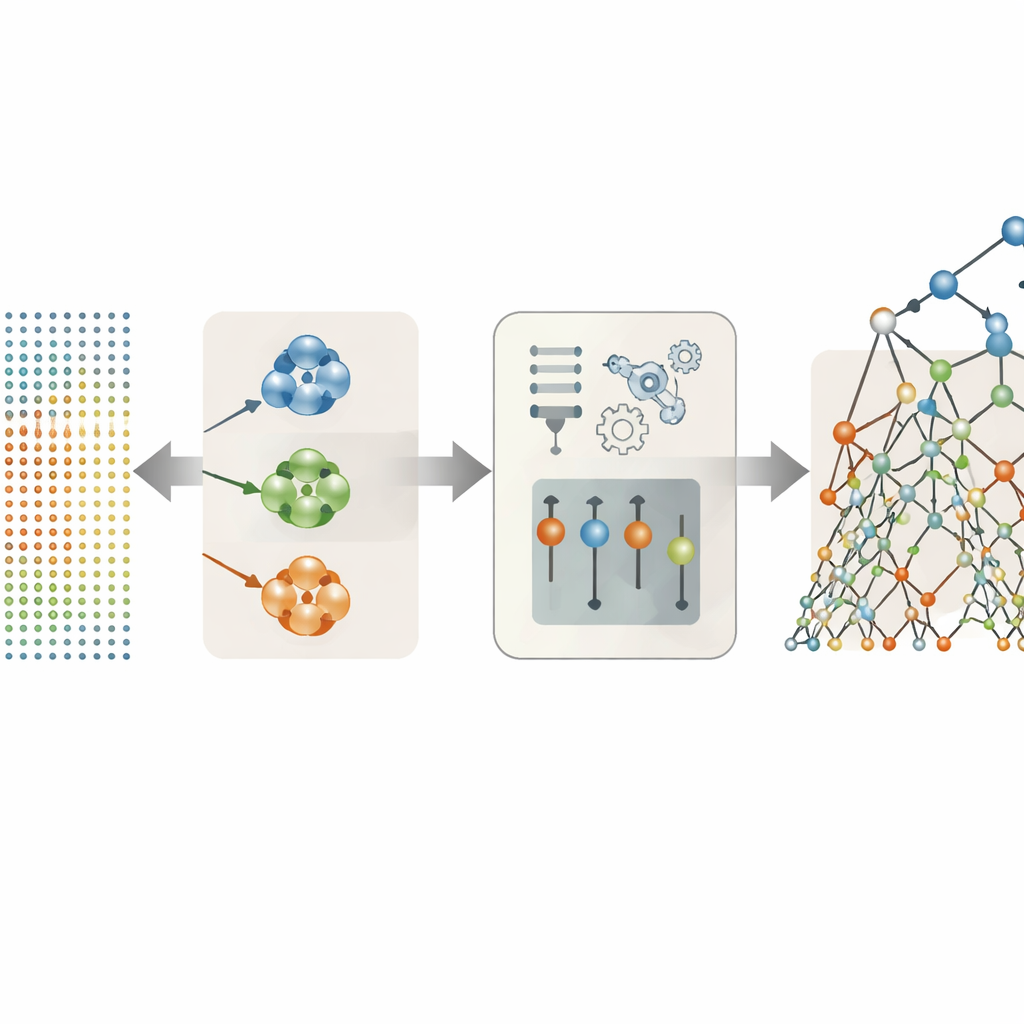
De data laten bepalen welke spraakkenmerken echt belangrijk zijn
Veel van de 26 spraakkenmerken in de dataset zijn variaties op een thema—for example verschillende manieren om toonhoogte- of volumeschommelingen te meten. In plaats van ze allemaal in het model te gooien, probeerden de auteurs verschillende strategieën om alleen de meest nuttige te behouden. Hun meest succesvolle aanpak was om kenmerken die zich vergelijkbaar gedragen te clusteren en vervolgens per cluster één representant te kiezen op basis van hoe sterk die samenhangt met de symptoomscores. Deze cluster-gebaseerde selectie reduceerde de oorspronkelijke set tot slechts drie opvallende indicatoren: één jitter-maat, één shimmer-maat en één maat voor de algehele stemruis. Ondanks deze ingrijpende vereenvoudiging vingen deze drie zorgvuldig geselecteerde kenmerken het grootste deel van de medische informatie in de opnames.
Gedistribueerde beslisbomen gebruiken om de stemsignalen te lezen
Met de gestroomlijnde spraakkenmerken vergeleek het team verschillende predictiemethoden, van eenvoudige lineaire formules tot flexibele boom-gebaseerde modellen en auto-encoder-achtige neurale netwerken. De duidelijke winnaar was een aanpak genaamd Extra Trees, een ensemble van vele beslisbomen die elk de data op sterk gerandomiseerde manieren splitsen. Deze willekeur, gecombineerd met de gereduceerde en minder redundante kenmerken, hielp het model overfitting te vermijden—het uit het hoofd leren van eigenaardigheden in de trainingsdata in plaats van het vinden van algemene patronen. Bij patiënten die buiten de training vielen, voorspelde de combinatie van clustering en Extra Trees zowel de Motor- als Total-UPDRS-scores met opvallende precisie; de verschillen met de gemeten scores lagen doorgaans ruim onder één punt op schalen die zich over meer dan honderd punten uitstrekken.
Wat dit betekent voor mensen met Parkinson
Voor een niet-specialistische lezer is de kernboodschap dat een klein aantal zorgvuldig gekozen stemmetingen, verwerkt met een doordachte leerpijplijn, de ernst van Parkinson bijna klinisch nauwkeurig kan volgen—met opnames gemaakt thuis. Hoewel de studie nog steunt op één dataset en in grotere, gevarieerdere patiëntengroepen getest moet worden, toont het een veelbelovende weg naar praktische telezorg: een toekomst waarin een korte stemopname patiënten en artsen kan helpen de ziekteprogressie te volgen, medicatie af te stemmen en mogelijk verslechtering eerder te signaleren, allemaal zonder bezoek aan de kliniek.
Bronvermelding: Essam, M., Balat, M., Zaky, A.B. et al. Adaptive regression model for Parkinson’s disease diagnosis from speech signals using Box-Cox-based clustering and extremely randomization. Sci Rep 16, 14044 (2026). https://doi.org/10.1038/s41598-026-49065-2
Trefwoorden: Ziekte van Parkinson, stemanalyse, machine learning, remote monitoring, kenmerkselectie