Clear Sky Science · pl
Adaptacyjny model regresji do diagnozy choroby Parkinsona na podstawie sygnałów mowy z użyciem grupowania opartego na transformacji Box–Cox i bardzo losowych drzew
Dlaczego słuchanie głosów może pomóc wykryć Parkinsona wcześniej
Choroba Parkinsona jest najbardziej znana z drżeń i sztywności, ale na długo zanim te objawy staną się oczywiste, głos często zaczyna zmieniać się w subtelny sposób. Ponieważ niemal każdy nosi przy sobie mikrofon — w telefonie — te zmiany można monitorować w domu, przekształcając zwykłą mowę w system wczesnego ostrzegania. Artykuł opisuje, jak zbudować inteligentne, wiarygodne narzędzie „nasłuchujące”, które za pomocą zaawansowanych technik komputerowych potrafi oszacować nasilenie objawów Parkinsona u danej osoby wyłącznie na podstawie jej głosu.
Przekształcanie domowych nagrań w użyteczne wskaźniki zdrowotne
Badacze pracowali na bogatym zbiorze nagrań głosu zebranym od 42 osób z wczesnym stadium choroby Parkinsona, które przez około sześć miesięcy w domu rejestrowały krótkie dźwięki samogłosek. Z każdego nagrania system mierzył dziesiątki właściwości dźwięku, takie jak stabilność wysokości tonu między kolejnymi drganiami strun głosowych (jitter), wahania głośności (shimmer) oraz stopień zaszumienia lub sapania w głosie. Te miary są powiązane ze sposobem, w jaki Parkinson wpływa na mięśnie kontrolujące mowę. Celem nie było tylko stwierdzenie obecności choroby, lecz przewidzenie dwóch szczegółowych ocen medycznych — Motor‑UPDRS i Total‑UPDRS — których lekarze używają do oceny ogólnego nasilenia objawów.
Oczyszczanie chaotycznych danych, by komputer mógł je zrozumieć
Surowe pomiary głosu mogą być chaotyczne: niektóre wartości są silnie skośne, inne zawierają ekstremalne odstające obserwacje, a wiele cech to silnie pokrywające się warianty tej samej informacji. Jeśli podać je bezpośrednio modelowi, taki bałagan może utrudnić uczenie i uczynić wyniki kruche. Aby temu zaradzić, zespół najpierw zastosował matematyczny krok przekształcający zwany transformacją Box–Cox. W uproszczeniu polega to na rozciąganiu i ściskaniu rozkładu danych tak, by wartości ekstremalne zostały złagodzone, a rozkład bliższy był gładkiej krzywej dzwonowej — formie lepiej obsługiwanej przez wiele algorytmów uczenia. Zadbał też o podział danych według osób, a nie nagrań, tak aby komputer nigdy nie widział tego samego pacjenta zarówno w zbiorze uczącym, jak i testowym, co zapobiega złudzeniu wysokiej dokładności wynikającemu z „zapamiętania” indywidualnych głosów.
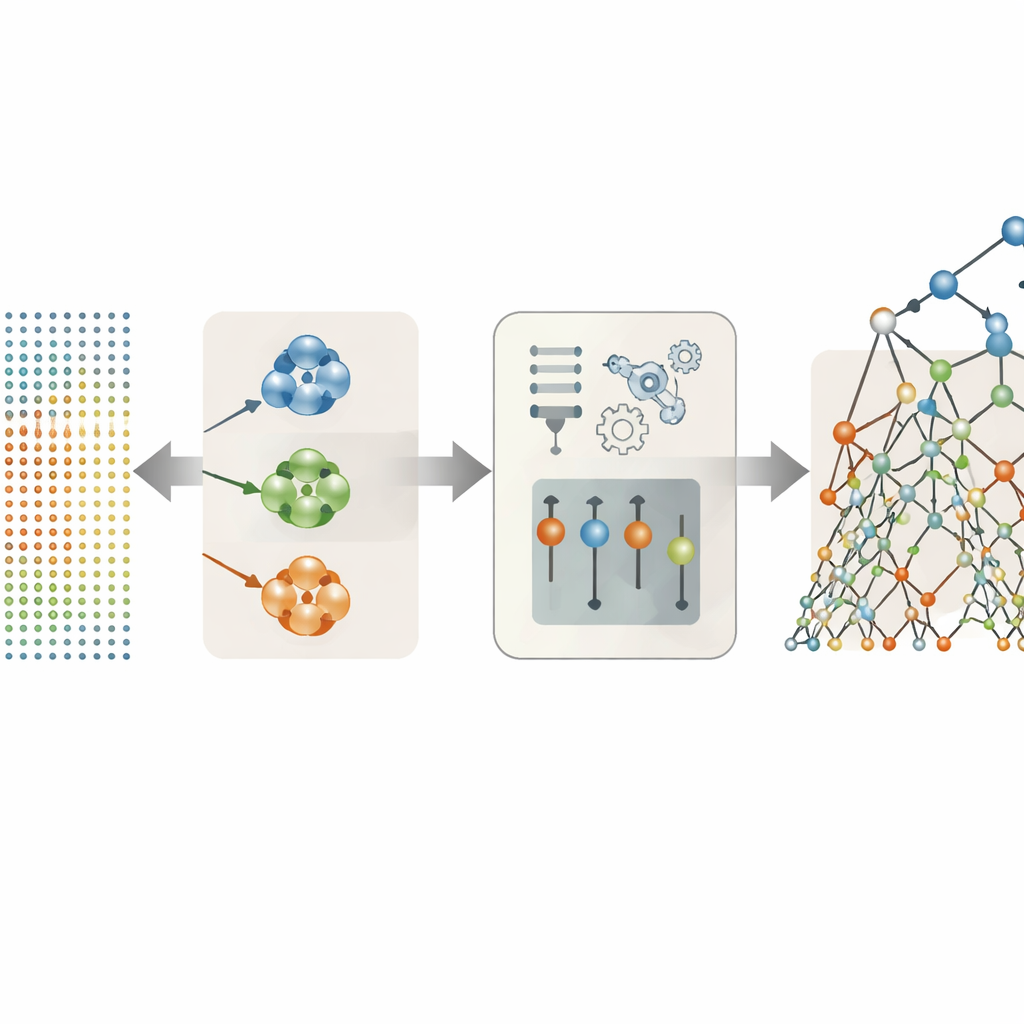
Pozwolić danym zdecydować, które cechy głosu naprawdę mają znaczenie
Wielu z 26 cech głosowych w zbiorze to warianty tej samej idei — na przykład różne sposoby mierzenia chwiejności tonu czy zmienności głośności. Zamiast wrzucać je wszystkie do modelu, autorzy przetestowali kilka strategii selekcji najbardziej użytecznych cech. Najskuteczniejszym podejściem okazało się grupowanie cech o podobnym zachowaniu w klastry, a następnie wybór pojedynczego reprezentanta z każdego klastra na podstawie siły powiązania z ocenami objawów. Selekcja oparta na grupowaniu zredukowała pierwotny zestaw do zaledwie trzech wyróżniających się wskaźników: jednej miary jitter, jednej miary shimmer i jednej miary ogólnego zaszumienia głosu. Pomimo tak drastycznego upraszczania, te trzy starannie dobrane cechy uchwyciły większość informacji medycznej ukrytej w nagraniach.
Wykorzystanie zrandomizowanych drzew decyzyjnych do odczytywania sygnałów głosowych
Z uproszczonym zbiorem cech głosowych zespół porównał gamę metod predykcyjnych — od prostych modeli liniowych po bardziej elastyczne modele drzewiaste i autoenkodery w stylu sieci neuronowych. Najlepiej wypadło podejście zwane Extra Trees, czyli zespół wielu drzew decyzyjnych, z których każde dzieli dane w wysoko zrandomizowany sposób. Ta losowość, w połączeniu z zredukowanym i mniej redundantnym zbiorem cech, pomogła modelowi uniknąć nadmiernego dopasowania — zapamiętywania osobliwości zbioru uczącego zamiast uczenia ogólnych wzorców. Na pacjentach pozostawionych do testu kombinacja grupowania i Extra Trees przewidywała zarówno wyniki Motor, jak i Total UPDRS z uderzającą precyzją, dopasowując prognozy do rzeczywistych ocen tak blisko, że różnice zwykle były znacznie mniejsze niż jedna jednostka na skalach obejmujących ponad sto punktów.
Co to oznacza dla osób żyjących z Parkinsonem
Dla czytelnika nieprofesjonalnego kluczowa wiadomość jest taka, że niewielka liczba starannie dobranych miar głosu, przetworzona przez przemyślany pipeline uczenia, może śledzić nasilenie Parkinsona z niemal kliniczną dokładnością — używając nagrań wykonanych w domu. Choć badanie opiera się wciąż na jednym zbiorze danych i będzie wymagać weryfikacji na większych, bardziej zróżnicowanych grupach pacjentów, pokazuje obiecującą drogę ku praktycznej telemedycynie: przyszłość, w której krótkie nagranie głosu może pomóc pacjentom i lekarzom śledzić postęp choroby, dostrajać leki i być może wcześniej wykrywać pogorszenie stanu, wszystko to bez wizyty w klinice.
Cytowanie: Essam, M., Balat, M., Zaky, A.B. et al. Adaptive regression model for Parkinson’s disease diagnosis from speech signals using Box-Cox-based clustering and extremely randomization. Sci Rep 16, 14044 (2026). https://doi.org/10.1038/s41598-026-49065-2
Słowa kluczowe: choroba Parkinsona, analiza głosu, uczenie maszynowe, monitorowanie zdalne, selekcja cech