Clear Sky Science · en
Adaptive regression model for Parkinson’s disease diagnosis from speech signals using Box-Cox-based clustering and extremely randomization
Why listening to voices can help spot Parkinson’s earlier
Parkinson’s disease is best known for tremors and stiffness, but long before those symptoms become obvious, the voice often starts to change in subtle ways. Because almost everyone carries a microphone in their pocket, these changes could be monitored at home, turning ordinary speech into an early warning system. This paper explores how to build a smart, reliable “listening” tool that uses advanced computer techniques to estimate how severe a person’s Parkinson’s symptoms are, just from their voice.
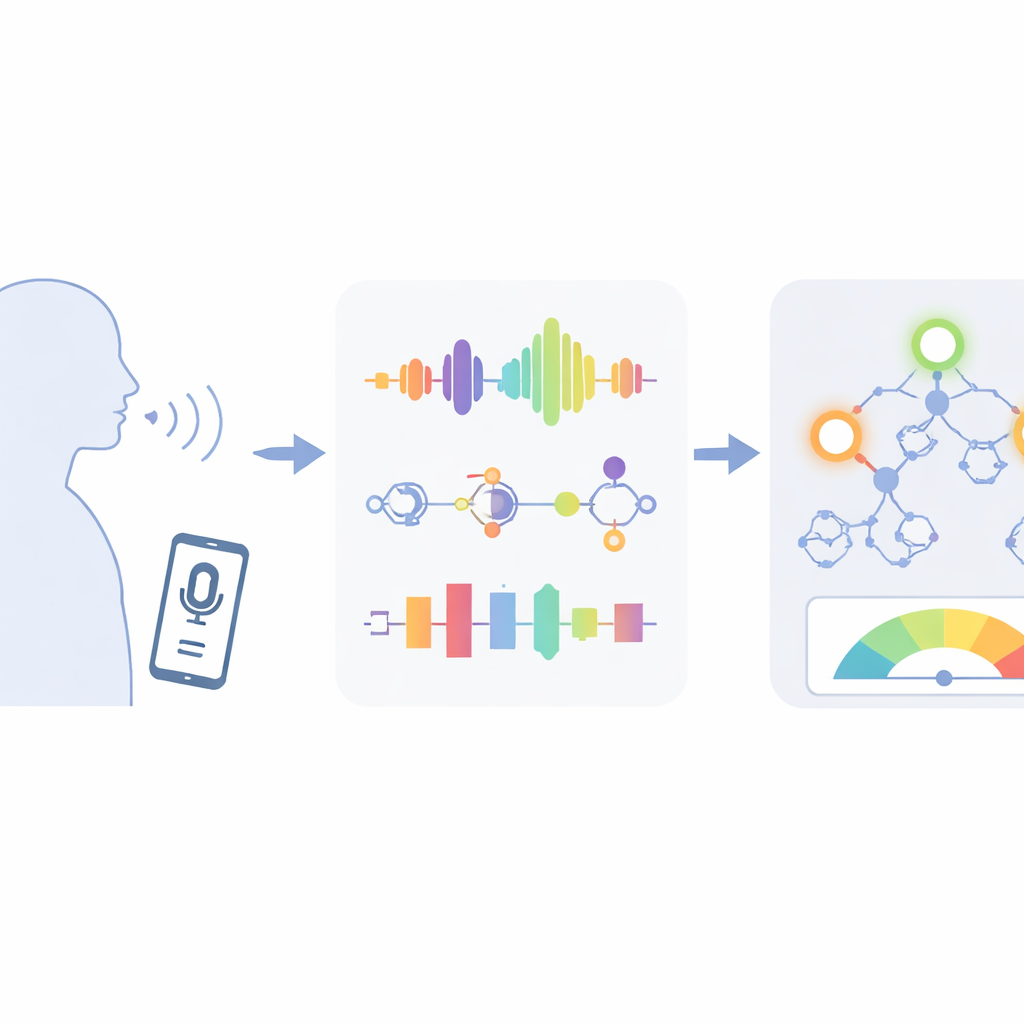
Turning home recordings into meaningful health clues
The researchers worked with a rich voice dataset collected from 42 people with early-stage Parkinson’s disease, who each recorded short vowel sounds at home over about six months. From every recording, the system measured dozens of properties of the sound, such as how steady the pitch is from one vibration of the vocal cords to the next (jitter), how much the loudness wobbles (shimmer), and how noisy or breathy the voice is. These measurements have been linked to the way Parkinson’s affects the muscles that control speech. The goal was not just to say whether someone has Parkinson’s, but to predict two detailed medical scores, called Motor-UPDRS and Total-UPDRS, that doctors use to rate overall symptom severity.
Cleaning up messy data so computers can understand it
Raw voice measurements can be messy: some values are highly skewed, others have extreme outliers, and many are strongly overlapping versions of the same idea. If fed directly into a model, this clutter can confuse learning and make results fragile. To address this, the team first applied a mathematical reshaping step called a Box–Cox transformation. In simple terms, this stretches and compresses the data so that extreme values are tamed and the overall spread looks more like a smooth bell curve, which many learning algorithms handle better. They also took care to split the data by person rather than by recording, so that the computer never saw the same patient in both training and testing, avoiding the illusion of high accuracy caused by “remembering” individual voices.
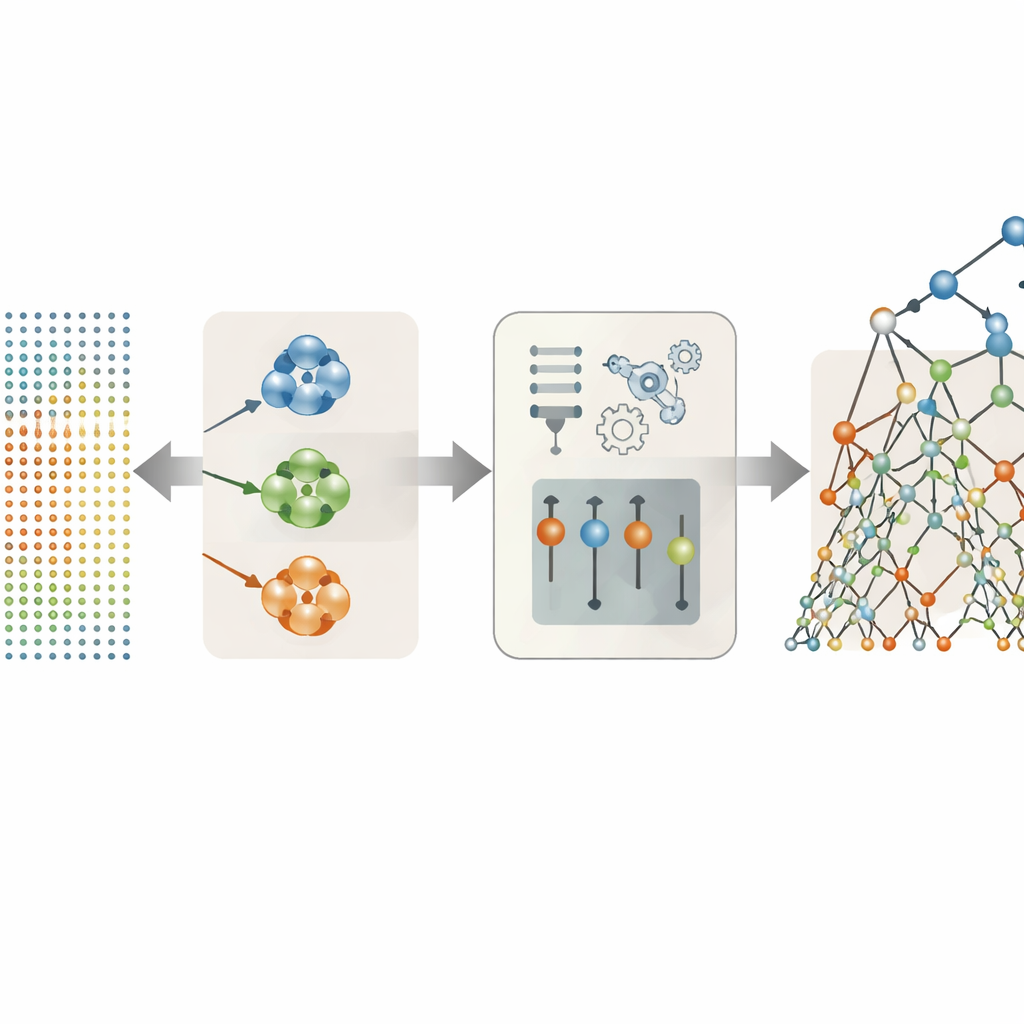
Letting the data decide which voice features really matter
Many of the 26 voice features in the dataset are variations on a theme—for example, several different ways to measure pitch shakiness or loudness variation. Instead of throwing them all into the model, the authors tried several strategies to keep only the most useful ones. Their most successful approach was to group features that behave similarly into clusters and then pick a single representative from each cluster based on how strongly it relates to the symptom scores. This clustering-based selection reduced the original set to just three stand-out indicators: one jitter measure, one shimmer measure, and one measure of overall voice noisiness. Despite this drastic simplification, these three carefully chosen features captured most of the medical information hidden in the recordings.
Using randomized decision trees to read the voice signals
With the streamlined voice features in hand, the team compared a lineup of prediction methods, from simple straight-line formulas to more flexible tree-based models and neural-network style autoencoders. The clear winner was an approach called Extra Trees, an ensemble of many decision trees that each splits the data in highly randomized ways. This randomness, combined with the reduced and less redundant feature set, helped the model avoid overfitting—memorizing quirks of the training data instead of learning general patterns. On held-out patients, the clustering-plus–Extra Trees combination predicted both Motor and Total UPDRS scores with striking precision, matching measured scores so closely that the differences were typically far below one point on scales that span over a hundred points.
What this means for people living with Parkinson’s
For a lay reader, the key message is that a small number of carefully chosen voice measurements, processed with a thoughtfully designed learning pipeline, can track Parkinson’s severity with near-clinical accuracy—using recordings made at home. While the study still relies on a single dataset and will need testing in larger, more varied groups of patients, it demonstrates a promising path toward practical telemedicine: a future in which a short voice recording could help patients and doctors follow disease progression, tune medications, and possibly catch worsening symptoms earlier, all without a trip to the clinic.
Citation: Essam, M., Balat, M., Zaky, A.B. et al. Adaptive regression model for Parkinson’s disease diagnosis from speech signals using Box-Cox-based clustering and extremely randomization. Sci Rep 16, 14044 (2026). https://doi.org/10.1038/s41598-026-49065-2
Keywords: Parkinson’s disease, voice analysis, machine learning, remote monitoring, feature selection