Clear Sky Science · ru
Адаптивная регрессионная модель для диагностики болезни Паркинсона по речевым сигналам с использованием кластеризации на базе преобразования Бокса — Кокса и экстремальной рандомизации
Почему прослушивание голосов помогает обнаружить Паркинсона раньше
Болезнь Паркинсона наиболее известна по тремору и скованности, но задолго до явных моторных симптомов голос часто начинает меняться тонкими, едва заметными способами. Поскольку почти у каждого в кармане есть микрофон, эти изменения можно отслеживать дома, превращая обычную речь в систему раннего предупреждения. В этой статье исследуется, как построить умный и надёжный «слушающий» инструмент, который с помощью современных вычислительных методов оценивает степень выраженности симптомов Паркинсона только по голосу.
Преобразование домашних записей в значимые признаки здоровья
Исследователи работали с богатым набором голосовых данных, собранных у 42 человек с ранней стадией болезни Паркинсона, которые записывали короткие гласные звуки дома на протяжении примерно шести месяцев. Из каждой записи система измеряла десятки характеристик звука, такие как стабильность высоты тона от одного колебания голосовых складок к следующему (jitter), насколько колеблется громкость (shimmer) и насколько голос шумный или дыхательный. Эти измерения связывают с тем, как Паркинсон влияет на мышцы, управляющие речью. Цель заключалась не просто в том, чтобы определить наличие болезни, а в том, чтобы предсказать две медицинские шкалы — Motor-UPDRS и Total-UPDRS, которыми врачи оценивают общую тяжесть симптомов.
Очистка неупорядоченных данных, чтобы компьютер мог их понять
Сырые голосовые измерения могут быть шумными: некоторые значения сильно асимметричны, в данных встречаются экстремальные выбросы, а многие признаки сильно перекрываются по смыслу. Если подавать их напрямую в модель, этот беспорядок может запутать обучение и сделать результаты нестабильными. Чтобы справиться с этим, команда сначала применила математическую процедуру преобразования Бокса—Кокса. Проще говоря, это растягивает и сжимает данные так, чтобы крайние значения были укрощены, а распределение в целом стало ближе к гладкой колоколообразной форме, с которой многие алгоритмы обучаются лучше. Также позаботились о разбиении данных по людям, а не по записям, чтобы компьютер никогда не видел одного и того же пациента и в обучающей, и в тестовой выборке — это предотвращает иллюзию высокой точности, возникающую при «запоминании» отдельных голосов.
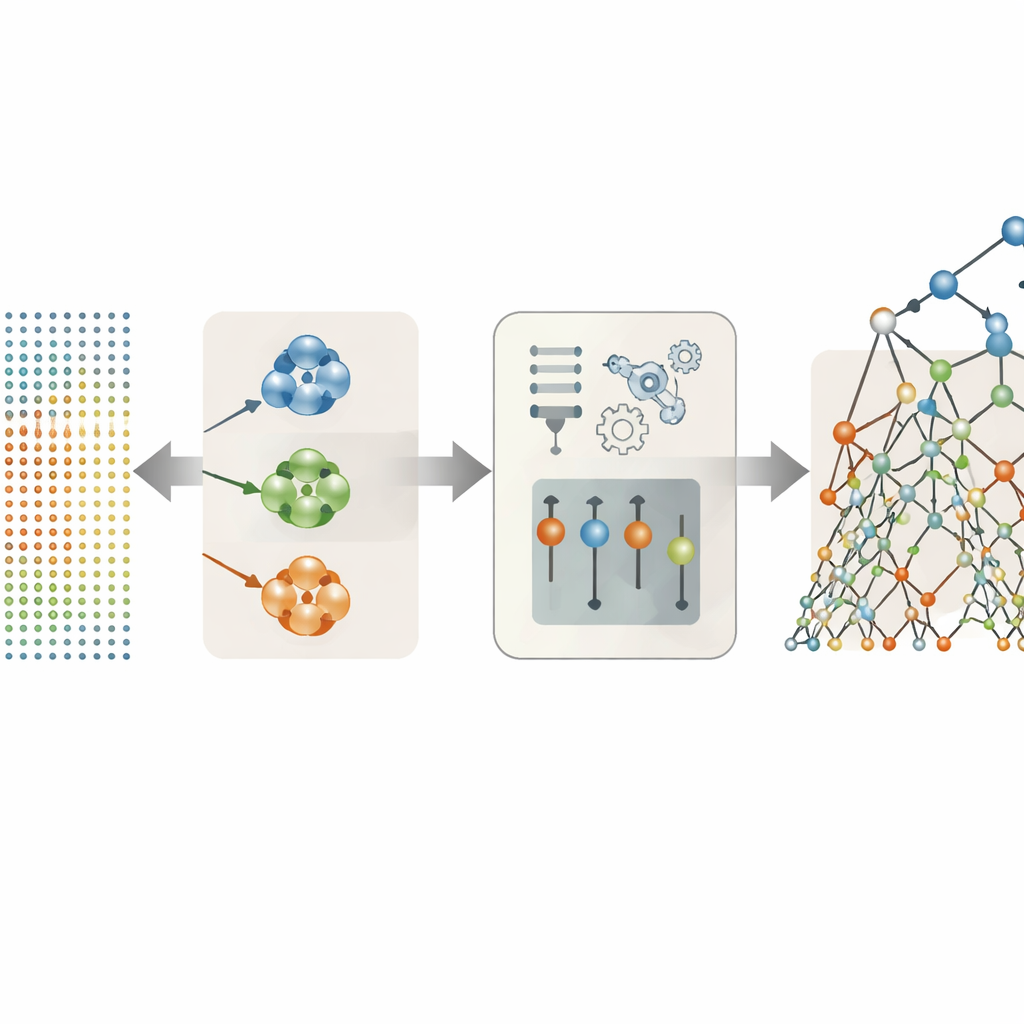
Дать данным самим решить, какие голосовые признаки важны
Многие из 26 голосовых признаков в наборе данных — вариации одной и той же идеи: например, разные способы измерения дрожания тона или вариаций громкости. Вместо того чтобы загружать их все в модель, авторы опробовали несколько стратегий отбора наиболее полезных. Наиболее успешным оказался подход, при котором признаки группировали в кластеры по схожему поведению, а затем выбирали один представитель от каждого кластера на основе того, насколько сильно он связан с оценками симптомов. Такой кластерно-ориентированный отбор сократил исходный набор до всего трёх ключевых индикаторов: одной меры jitter, одной меры shimmer и одной меры общей шумности голоса. Несмотря на радикальное упрощение, эти три тщательно отобранных признака сохранили большую часть медицинской информации, скрытой в записях.
Использование рандомизированных деревьев решений для распознавания голосовых сигналов
Имея упрощённый набор голосовых признаков, команда сравнила несколько методов предсказания — от простых линейных формул до гибких моделей на базе деревьев и автоэнкодеров в стиле нейронных сетей. Явным победителем оказался метод Extra Trees — ансамбль многих деревьев решений, каждое из которых разветвляется с высокой степенью рандомизации. Эта случайность в сочетании с уменьшенным и менее избыточным набором признаков помогла модели избежать переобучения — запоминания особенностей обучающих данных вместо изучения общих закономерностей. На отложенных пациентах связка кластеризации и Extra Trees предсказывала как Motor-, так и Total-UPDRS с впечатляющей точностью: прогнозы совпадали с измеренными значениями настолько близко, что различия обычно были значительно меньше одного балла на шкалах, которые охватывают более ста пунктов.
Что это означает для людей с болезнью Паркинсона
Для широкой аудитории ключевой вывод прост: небольшое число тщательно отобранных голосовых измерений, обработанных продуманным конвейером машинного обучения, может отслеживать тяжесть Паркинсона с почти клинической точностью — используя записи, сделанные дома. Хотя исследование опирается на один набор данных и требует проверки на более крупных и разнообразных группах пациентов, оно демонстрирует многообещающий путь к практической телемедицине: будущее, в котором короткая голосовая запись может помочь пациентам и врачам отслеживать прогресс болезни, корректировать лекарства и, возможно, раньше заметить ухудшение симптомов — всё это без похода в клинику.
Цитирование: Essam, M., Balat, M., Zaky, A.B. et al. Adaptive regression model for Parkinson’s disease diagnosis from speech signals using Box-Cox-based clustering and extremely randomization. Sci Rep 16, 14044 (2026). https://doi.org/10.1038/s41598-026-49065-2
Ключевые слова: Болезнь Паркинсона, анализ голоса, машинное обучение, удалённый мониторинг, отбор признаков