Clear Sky Science · fr
Modèle de régression adaptatif pour le diagnostic de la maladie de Parkinson à partir de signaux vocaux utilisant un regroupement basé sur Box-Cox et l'extrême randomisation
Pourquoi écouter les voix peut aider à repérer la maladie de Parkinson plus tôt
La maladie de Parkinson est surtout connue pour les tremblements et la raideur, mais bien avant que ces symptômes ne deviennent évidents, la voix évolue souvent de manière subtile. Comme presque tout le monde porte un microphone dans sa poche, ces changements pourraient être surveillés à domicile, transformant la parole ordinaire en un système d’alerte précoce. Cet article examine comment construire un outil « d’écoute » intelligent et fiable qui utilise des techniques informatiques avancées pour estimer la sévérité des symptômes de Parkinson d’une personne, uniquement à partir de sa voix.
Transformer des enregistrements domestiques en indices de santé pertinents
Les chercheurs ont travaillé avec un riche jeu de données vocales collectées auprès de 42 personnes atteintes de Parkinson au stade précoce, chacune ayant enregistré des voyelles courtes à domicile sur environ six mois. À partir de chaque enregistrement, le système a mesuré des dizaines de propriétés du son, comme la stabilité du pitch d’une vibration des cordes vocales à la suivante (jitter), l’oscillation du volume (shimmer) et le niveau de bruit ou d’aspiration dans la voix. Ces mesures ont été liées à la manière dont Parkinson affecte les muscles qui contrôlent la parole. L’objectif n’était pas seulement de dire si quelqu’un a la maladie de Parkinson, mais de prédire deux scores médicaux détaillés, appelés Motor-UPDRS et Total-UPDRS, que les médecins utilisent pour évaluer la sévérité globale des symptômes.
Nettoyer des données désordonnées pour que les ordinateurs les comprennent
Les mesures vocales brutes peuvent être désordonnées : certaines valeurs sont fortement asymétriques, d’autres présentent des valeurs extrêmes, et beaucoup sont des versions fortement redondantes d’une même idée. Si elles sont directement introduites dans un modèle, cette confusion peut perturber l’apprentissage et rendre les résultats fragiles. Pour y remédier, l’équipe a d’abord appliqué une étape mathématique de remodelage appelée transformation de Box–Cox. En termes simples, cela étire et compresse les données pour dompter les valeurs extrêmes et rendre la dispersion globale plus proche d’une courbe en cloche, que de nombreux algorithmes d’apprentissage gèrent mieux. Ils ont aussi pris soin de séparer les données par personne plutôt que par enregistrement, de sorte que l’ordinateur ne voie jamais le même patient à la fois dans l’apprentissage et dans le test, évitant l’illusion d’une grande précision due au « souvenir » de voix individuelles.
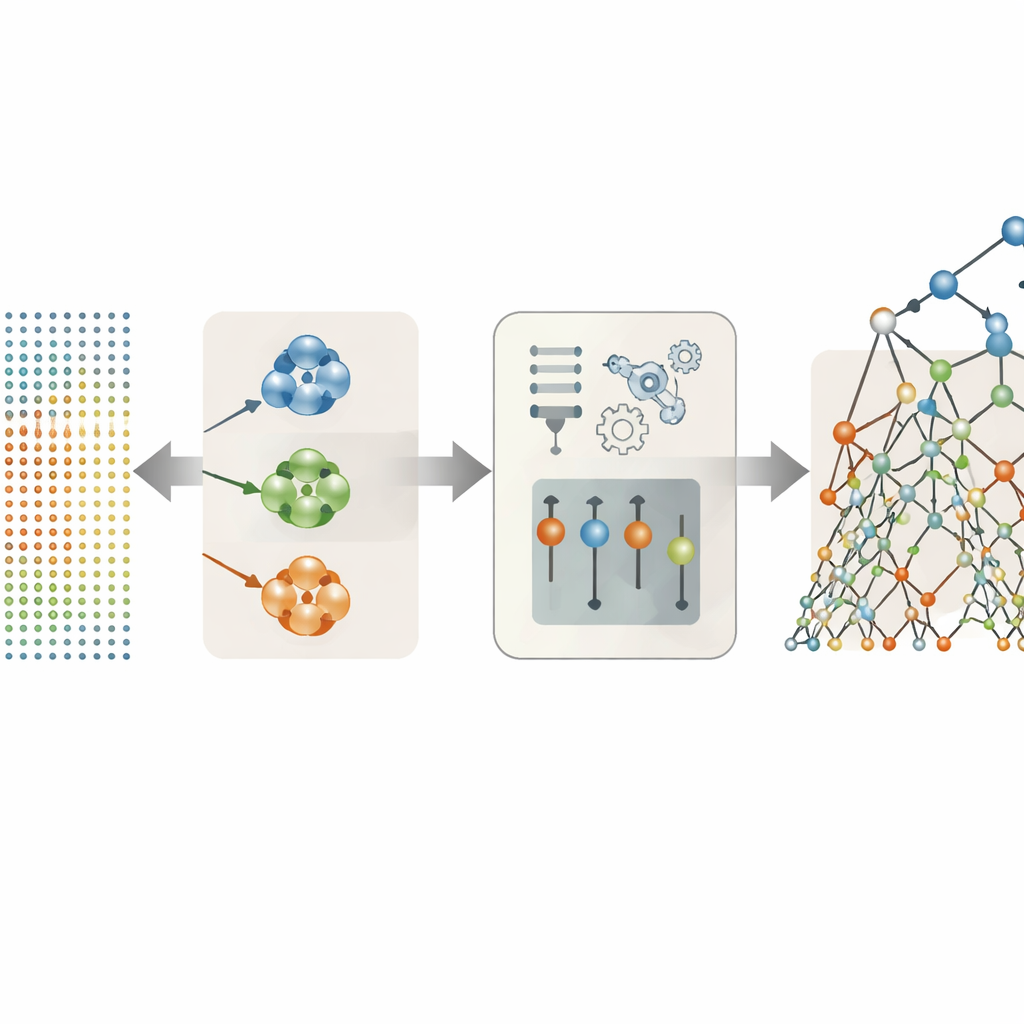
Laisser les données décider quelles caractéristiques vocales importent vraiment
Beaucoup des 26 caractéristiques vocales du jeu de données sont des variations sur un même thème — par exemple, plusieurs façons de mesurer les tremblements de la hauteur ou les variations d’intensité. Plutôt que de toutes les injecter dans le modèle, les auteurs ont testé plusieurs stratégies pour ne conserver que les plus utiles. Leur approche la plus efficace a consisté à regrouper les caractéristiques qui se comportent de manière similaire en clusters, puis à choisir un représentant unique pour chaque cluster en fonction de la force de sa relation avec les scores de symptômes. Cette sélection basée sur le regroupement a réduit l’ensemble initial à seulement trois indicateurs marquants : une mesure de jitter, une mesure de shimmer et une mesure du niveau global de bruit vocal. Malgré cette simplification radicale, ces trois caractéristiques soigneusement choisies ont capté la majeure partie de l’information clinique contenue dans les enregistrements.
Utiliser des arbres de décision randomisés pour lire les signaux vocaux
Avec ces caractéristiques vocales rationalisées, l’équipe a comparé plusieurs méthodes de prédiction, des formules linéaires simples aux modèles arborescents plus flexibles et aux autoencodeurs de type réseau de neurones. Le gagnant clair a été une approche appelée Extra Trees, un ensemble de nombreux arbres de décision qui partitionnent les données de manière fortement aléatoire. Ce hasard, combiné à l’ensemble de caractéristiques réduit et moins redondant, a aidé le modèle à éviter le surapprentissage — mémoriser les particularités des données d’entraînement plutôt que d’apprendre des motifs généraux. Sur des patients exclus de l’entraînement, la combinaison regroupement + Extra Trees a prédit avec une précision remarquable les scores Motor et Total UPDRS, correspondant si étroitement aux scores mesurés que les écarts étaient typiquement bien inférieurs à un point sur des échelles qui s’étendent sur plus d’une centaine de points.
Ce que cela signifie pour les personnes vivant avec la maladie de Parkinson
Pour un lecteur non spécialiste, le message clé est qu’un petit nombre de mesures vocales soigneusement choisies, traitées par une chaîne d’apprentissage conçue avec soin, peut suivre la sévérité de Parkinson avec une précision proche de celle clinique — à partir d’enregistrements réalisés à domicile. Bien que l’étude repose encore sur un jeu de données unique et doive être testée sur des cohortes plus larges et diversifiées, elle montre une voie prometteuse vers la télémédecine pratique : un avenir où un bref enregistrement vocal pourrait aider patients et médecins à suivre l’évolution de la maladie, ajuster les traitements et éventuellement détecter une aggravation plus tôt, le tout sans déplacement en clinique.
Citation: Essam, M., Balat, M., Zaky, A.B. et al. Adaptive regression model for Parkinson’s disease diagnosis from speech signals using Box-Cox-based clustering and extremely randomization. Sci Rep 16, 14044 (2026). https://doi.org/10.1038/s41598-026-49065-2
Mots-clés: Maladie de Parkinson, analyse de la voix, apprentissage automatique, surveillance à distance, sélection de caractéristiques