Clear Sky Science · it
Modello di regressione adattivo per la diagnosi del morbo di Parkinson da segnali vocali usando clustering basato su Box-Cox e extremely randomization
Perché ascoltare le voci può aiutare a individuare il Parkinson prima
Il morbo di Parkinson è più noto per i tremori e la rigidità, ma molto prima che questi sintomi diventino evidenti la voce spesso inizia a cambiare in modi sottili. Poiché quasi tutti portano con sé un microfono in tasca, questi cambiamenti potrebbero essere monitorati a casa, trasformando il parlato ordinario in un sistema di allerta precoce. Questo articolo esplora come costruire uno strumento “uditivo” intelligente e affidabile che utilizza tecniche informatiche avanzate per stimare la gravità dei sintomi del Parkinson di una persona partendo solo dalla sua voce.
Trasformare le registrazioni domestiche in indizi di salute significativi
I ricercatori hanno lavorato con un ricco set di dati vocali raccolti da 42 persone con Parkinson in fase iniziale, ognuna delle quali ha registrato brevi suoni vocalici a casa per circa sei mesi. Da ogni registrazione il sistema ha misurato dozzine di proprietà del suono, come la stabilità del tono da una vibrazione delle corde vocali alla successiva (jitter), quanto varia il volume (shimmer) e quanto la voce risulti rumorosa o affannata. Queste misure sono state associate a come il Parkinson influisce sui muscoli che controllano la parola. L’obiettivo non era solo determinare se una persona ha il Parkinson, ma prevedere due punteggi medici dettagliati, chiamati Motor-UPDRS e Total-UPDRS, che i medici usano per valutare la gravità complessiva dei sintomi.
Ripulire dati disordinati in modo che i computer li comprendano
Le misure vocali grezze possono essere disordinate: alcuni valori sono fortemente asimmetrici, altri presentano outlier estremi e molte misure sono versioni molto sovrapposte dello stesso concetto. Se inseriti direttamente in un modello, questi elementi possono confondere l’apprendimento e rendere i risultati fragili. Per affrontare il problema, il team ha prima applicato un’operazione matematica di rimodellamento chiamata trasformazione Box–Cox. In termini semplici, questa operazione allunga e comprime i dati in modo che i valori estremi vengano attenuati e la distribuzione complessiva assomigli di più a una curva a campana, che molti algoritmi di apprendimento gestiscono meglio. Hanno inoltre provveduto a suddividere i dati per persona piuttosto che per singola registrazione, così che il computer non vedesse mai lo stesso paziente sia nella fase di training che in quella di test, evitando l’illusione di un’alta accuratezza dovuta al “riconoscimento” delle voci individuali.
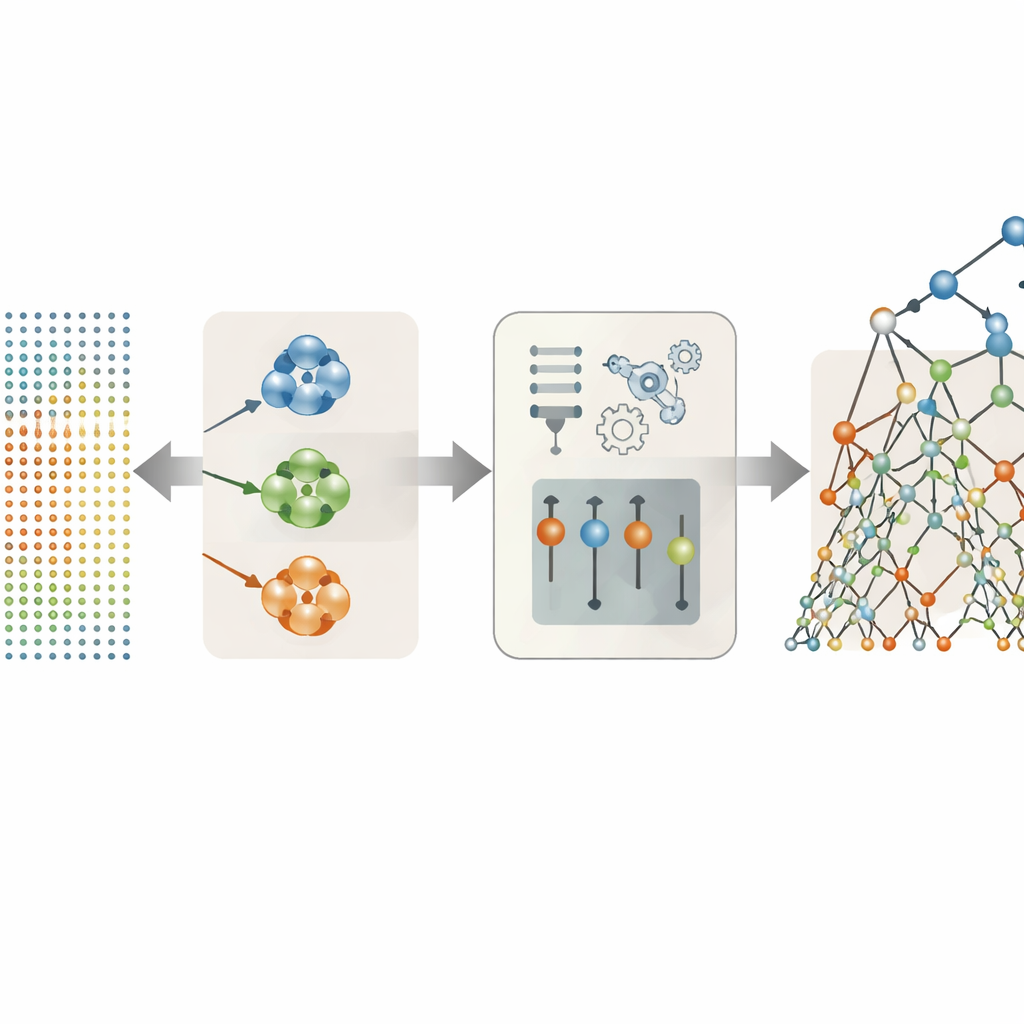
Lasciare che siano i dati a decidere quali caratteristiche vocali contano davvero
Molte delle 26 caratteristiche vocali nel dataset sono variazioni sullo stesso tema—for esempio diversi modi di misurare l’instabilità del tono o la variazione di intensità. Invece di inserirle tutte nel modello, gli autori hanno provato diverse strategie per mantenere solo le più utili. L’approccio più efficace è stato raggruppare le caratteristiche che si comportano in modo simile in cluster e poi selezionare un rappresentante per ciascun cluster basandosi su quanto fortemente è correlato ai punteggi dei sintomi. Questa selezione basata sul clustering ha ridotto il set originale a sole tre caratteristiche di rilievo: una misura di jitter, una misura di shimmer e una misura della rumorosità complessiva della voce. Nonostante questa drastica semplificazione, queste tre caratteristiche scelte con cura hanno catturato gran parte delle informazioni mediche nascoste nelle registrazioni.
Usare alberi decisionali randomizzati per leggere i segnali vocali
Con le caratteristiche vocali semplificate, il team ha confrontato una serie di metodi predittivi, da formule lineari semplici a modelli ad albero più flessibili e autoencoder in stile rete neurale. Il vincitore netto è stato un approccio chiamato Extra Trees, un ensemble di molti alberi decisionali che ciascuno suddivide i dati in modi altamente randomizzati. Questa casualità, combinata con il set di caratteristiche ridotto e meno ridondante, ha aiutato il modello a evitare l’overfitting—memorizzare le particolarità del training invece di apprendere pattern generali. Su pazienti non usati durante l’addestramento, la combinazione clustering più Extra Trees ha previsto sia i punteggi Motor sia i punteggi Total UPDRS con una precisione sorprendente, avvicinandosi così tanto ai valori misurati che le differenze erano tipicamente molto inferiori a un punto su scale che si estendono oltre cento punti.
Cosa significa questo per le persone che convivono con il Parkinson
Per il lettore non specialista, il messaggio chiave è che un piccolo numero di misure vocali selezionate con attenzione, elaborate con una pipeline di apprendimento progettata con cura, può monitorare la gravità del Parkinson con una precisione vicina a quella clinica—usando registrazioni effettuate a casa. Sebbene lo studio si basi ancora su un singolo dataset e richieda test su gruppi più ampi e vari di pazienti, dimostra una via promettente verso la telemedicina pratica: un futuro in cui una breve registrazione vocale potrebbe aiutare pazienti e medici a seguire la progressione della malattia, regolare i farmaci e possibilmente cogliere un peggioramento dei sintomi prima, il tutto senza una visita in clinica.
Citazione: Essam, M., Balat, M., Zaky, A.B. et al. Adaptive regression model for Parkinson’s disease diagnosis from speech signals using Box-Cox-based clustering and extremely randomization. Sci Rep 16, 14044 (2026). https://doi.org/10.1038/s41598-026-49065-2
Parole chiave: Morbo di Parkinson, analisi della voce, apprendimento automatico, monitoraggio remoto, selezione delle caratteristiche