Clear Sky Science · es
Modelo de regresión adaptable para el diagnóstico de la enfermedad de Parkinson a partir de señales de voz mediante agrupamiento basado en Box-Cox y randomización extrema
Por qué escuchar las voces puede ayudar a detectar el Parkinson antes
La enfermedad de Parkinson es más conocida por los temblores y la rigidez, pero mucho antes de que esos síntomas sean evidentes, la voz suele empezar a cambiar de forma sutil. Dado que casi todo el mundo lleva un micrófono en el bolsillo, estos cambios podrían controlarse en casa, convirtiendo el habla ordinaria en un sistema de alerta temprana. Este artículo explora cómo construir una herramienta «auditiva» inteligente y fiable que emplea técnicas informáticas avanzadas para estimar la gravedad de los síntomas de Parkinson de una persona solo a partir de su voz.
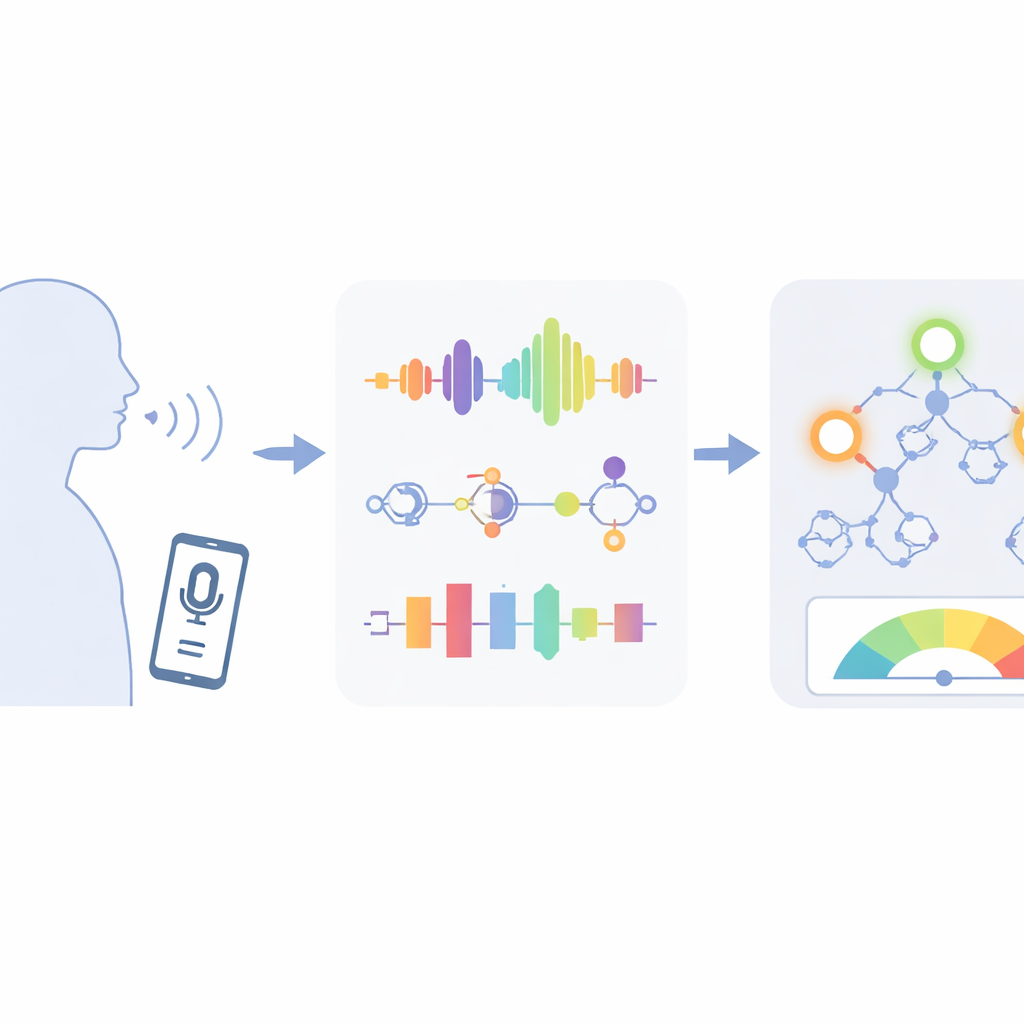
Convertir grabaciones domésticas en pistas sanitarias significativas
Los investigadores trabajaron con un rico conjunto de datos de voz recogido de 42 personas con Parkinson en fase inicial, que cada una grabó sonidos vocálicos cortos en casa durante unos seis meses. De cada grabación, el sistema midió decenas de propiedades del sonido, como la estabilidad del tono de una vibración de las cuerdas vocales a la siguiente (jitter), cuánto varía la intensidad sonora (shimmer) y cuán ruidosa o jadeante es la voz. Estas mediciones se han vinculado a la forma en que el Parkinson afecta los músculos que controlan el habla. El objetivo no era solo decir si alguien tiene Parkinson, sino predecir dos puntuaciones médicas detalladas, llamadas Motor-UPDRS y Total-UPDRS, que los médicos usan para evaluar la gravedad global de los síntomas.
Limpiar datos desordenados para que los ordenadores los entiendan
Las mediciones de voz en bruto pueden ser desordenadas: algunos valores están muy sesgados, otros presentan valores extremos, y muchos son versiones fuertemente solapadas de la misma idea. Si se introducen directamente en un modelo, este ruido puede confundir el aprendizaje y hacer los resultados frágiles. Para abordar esto, el equipo aplicó primero un paso matemático de reconfiguración llamado transformación Box–Cox. En términos sencillos, esto estira y comprime los datos para que los valores extremos se atenúen y la dispersión global se parezca más a una curva de campana suave, que muchos algoritmos de aprendizaje manejan mejor. También se ocuparon de dividir los datos por persona en lugar de por grabación, de modo que el ordenador nunca vio al mismo paciente en el entrenamiento y en la prueba, evitando la ilusión de alta precisión causada por «recordar» voces individuales.
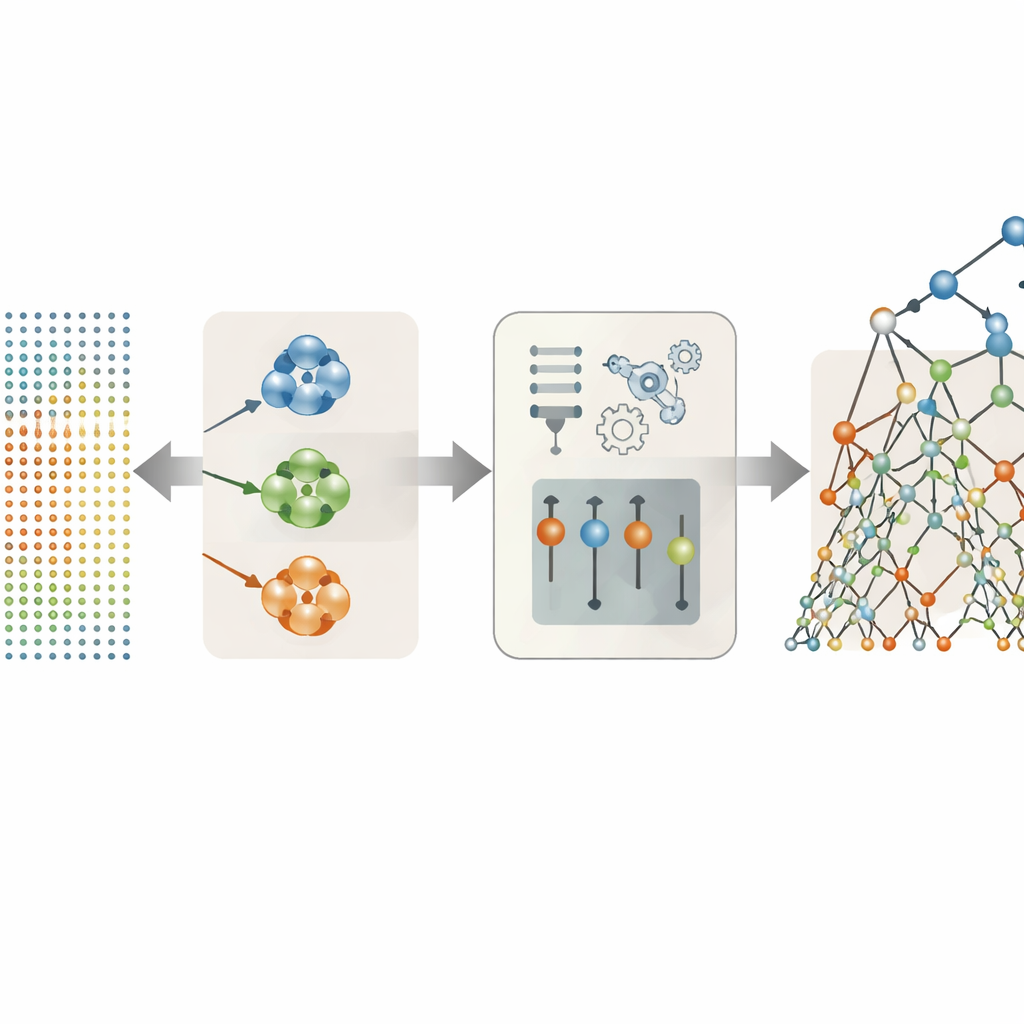
Dejar que los datos decidan qué características de la voz importan
Muchas de las 26 características de la voz del conjunto de datos son variaciones sobre un mismo tema; por ejemplo, varias formas diferentes de medir la inestabilidad del tono o la variación de la intensidad. En lugar de introducirlas todas en el modelo, los autores probaron varias estrategias para conservar solo las más útiles. Su enfoque más exitoso fue agrupar las características que se comportan de forma similar en clústeres y luego elegir un representante único de cada clúster según la fuerza de su relación con las puntuaciones de los síntomas. Esta selección basada en agrupamiento redujo el conjunto original a solo tres indicadores destacados: una medida de jitter, una de shimmer y una medida de la ruidosidad general de la voz. A pesar de esta simplificación drástica, estas tres características escogidas con cuidado capturaron la mayor parte de la información clínica oculta en las grabaciones.
Usar árboles de decisión aleatorizados para leer las señales de la voz
Con las características de voz racionalizadas, el equipo comparó una batería de métodos de predicción, desde fórmulas lineales sencillas hasta modelos más flexibles basados en árboles y autoencoders tipo red neuronal. El claro vencedor fue un enfoque llamado Extra Trees, un conjunto de muchos árboles de decisión que a cada uno le asigna divisiones de datos altamente aleatorias. Esta aleatoriedad, combinada con el conjunto de características reducido y menos redundante, ayudó al modelo a evitar el sobreajuste: memorizar rarezas de los datos de entrenamiento en vez de aprender patrones generales. Sobre pacientes reservados para la prueba, la combinación de agrupamiento y Extra Trees predijo con notable precisión tanto las puntuaciones Motor como Total UPDRS, ajustándose a las puntuaciones medidas de manera que las diferencias normalmente quedaron muy por debajo de un punto en escalas que abarcan más de cien puntos.
Qué significa esto para las personas que viven con Parkinson
Para un lector general, el mensaje clave es que un pequeño número de mediciones de la voz cuidadosamente seleccionadas, procesadas con una canalización de aprendizaje bien diseñada, pueden seguir la gravedad del Parkinson con precisión casi clínica usando grabaciones realizadas en casa. Aunque el estudio aún se basa en un único conjunto de datos y necesitará pruebas en grupos de pacientes más grandes y variados, demuestra un camino prometedor hacia la telemedicina práctica: un futuro en el que una breve grabación de voz podría ayudar a pacientes y médicos a seguir la progresión de la enfermedad, ajustar medicamentos y posiblemente detectar empeoramientos antes, todo ello sin una visita al consultorio.
Cita: Essam, M., Balat, M., Zaky, A.B. et al. Adaptive regression model for Parkinson’s disease diagnosis from speech signals using Box-Cox-based clustering and extremely randomization. Sci Rep 16, 14044 (2026). https://doi.org/10.1038/s41598-026-49065-2
Palabras clave: Enfermedad de Parkinson, análisis de la voz, aprendizaje automático, monitorización remota, selección de características