Clear Sky Science · pt
Modelo de regressão adaptativo para diagnóstico da doença de Parkinson a partir de sinais de voz usando agrupamento baseado em Box-Cox e Extremely Randomization
Por que ouvir vozes pode ajudar a detectar Parkinson mais cedo
A doença de Parkinson é mais conhecida por tremores e rigidez, mas muito antes desses sintomas se tornarem evidentes, a voz frequentemente começa a mudar de maneiras sutis. Como quase todo mundo carrega um microfone no bolso, essas alterações poderiam ser monitoradas em casa, transformando a fala comum em um sistema de alerta precoce. Este artigo explora como construir uma ferramenta “ouvinte” inteligente e confiável que usa técnicas computacionais avançadas para estimar quão severos são os sintomas de Parkinson de uma pessoa apenas a partir de sua voz.
Transformando gravações caseiras em pistas significativas sobre a saúde
Os pesquisadores trabalharam com um rico conjunto de dados vocais coletados de 42 pessoas com Parkinson em estágio inicial, que gravaram sons vocálicos curtos em casa ao longo de cerca de seis meses. De cada gravação, o sistema mediu dezenas de propriedades do som, como quão estável é o tom de uma vibração das cordas vocais para a próxima (jitter), quanto a intensidade oscila (shimmer) e o quão ruidosa ou ofegante a voz soa. Essas medições estão ligadas à forma como o Parkinson afeta os músculos que controlam a fala. O objetivo não era apenas dizer se alguém tem Parkinson, mas prever duas pontuações médicas detalhadas, chamadas Motor-UPDRS e Total-UPDRS, que os médicos usam para avaliar a gravidade geral dos sintomas.
Limpando dados bagunçados para que os computadores possam entendê-los
Medidas vocais brutas podem ser desordenadas: alguns valores são altamente enviesados, outros apresentam outliers extremos, e muitos são versões fortemente correlacionadas da mesma característica. Se alimentados diretamente em um modelo, essa desordem pode confundir o aprendizado e tornar os resultados frágeis. Para lidar com isso, a equipe aplicou primeiro uma etapa matemática de reconfiguração chamada transformação Box–Cox. Em termos simples, isso estica e comprime os dados para que valores extremos sejam domados e a dispersão geral se aproxime de uma curva em sino suave, que muitos algoritmos de aprendizado tratam melhor. Eles também tomaram cuidado para dividir os dados por pessoa e não por gravação, garantindo que o computador nunca visse o mesmo paciente tanto no treinamento quanto no teste, evitando a ilusão de alta acurácia causada por “decorar” vozes individuais.
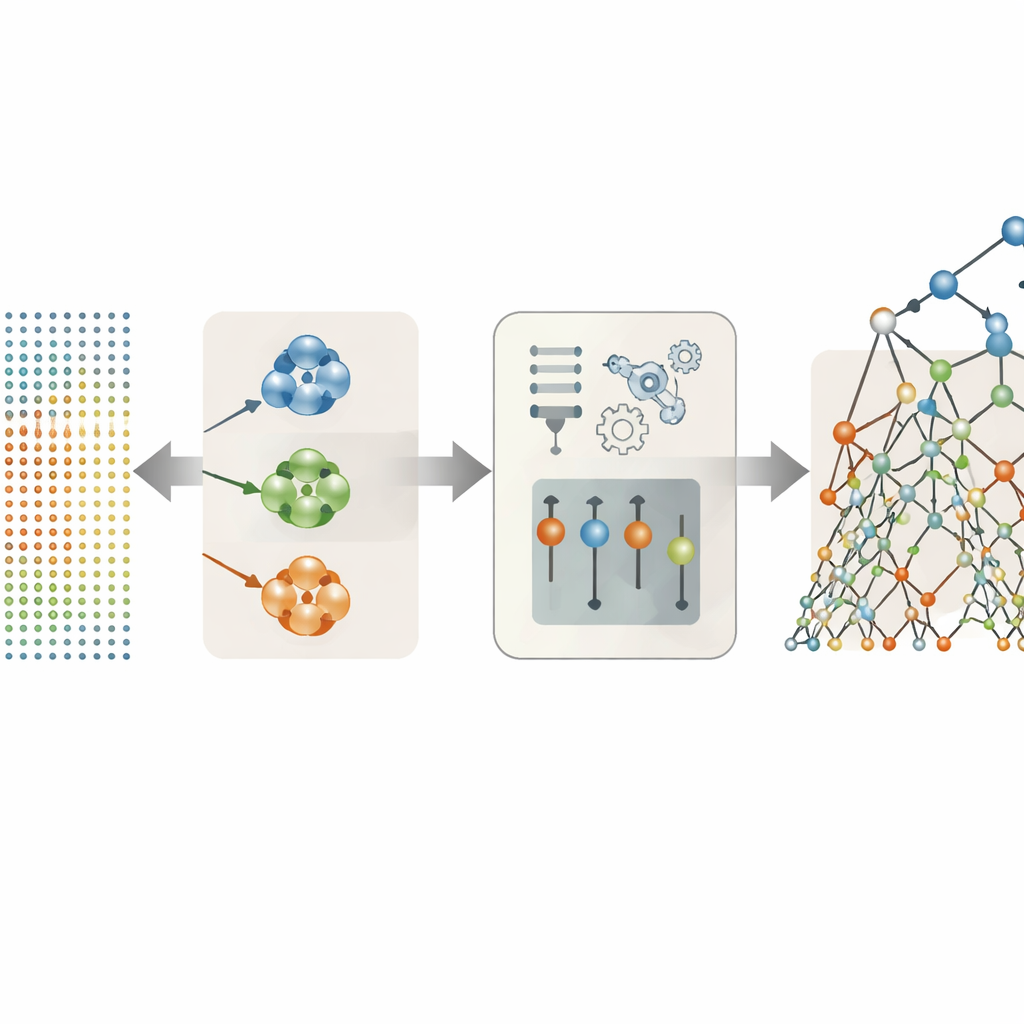
Deixando os dados decidirem quais características de voz realmente importam
Muitas das 26 características vocais no conjunto de dados são variações sobre um mesmo tema — por exemplo, várias formas diferentes de medir tremor de pitch ou variação de intensidade. Em vez de colocar tudo no modelo, os autores testaram várias estratégias para manter apenas as mais úteis. A abordagem de maior sucesso foi agrupar características que se comportam de forma semelhante em clusters e então escolher um único representante de cada cluster com base em quão fortemente ele se relaciona com as pontuações dos sintomas. Essa seleção baseada em agrupamento reduziu o conjunto original para apenas três indicadores de destaque: uma medida de jitter, uma de shimmer e uma medida da sonoridade/ruído geral da voz. Apesar dessa simplificação drástica, essas três características cuidadosamente escolhidas capturaram a maior parte da informação clínica escondida nas gravações.
Usando árvores de decisão randomizadas para interpretar os sinais vocais
Com as características vocais simplificadas em mãos, a equipe comparou uma série de métodos de predição, de fórmulas lineares simples a modelos baseados em árvores mais flexíveis e autoencoders no estilo de redes neurais. O claro vencedor foi uma abordagem chamada Extra Trees, um conjunto de muitas árvores de decisão que dividem os dados de maneiras altamente randomizadas. Essa aleatoriedade, combinada com o conjunto de características reduzido e menos redundante, ajudou o modelo a evitar overfitting — memorizar peculiaridades dos dados de treinamento em vez de aprender padrões gerais. Em pacientes mantidos fora do treinamento, a combinação de agrupamento mais Extra Trees previu tanto as pontuações Motor quanto Total UPDRS com precisão impressionante, correspondendo às pontuações medidas tão de perto que as diferenças tipicamente ficavam bem abaixo de um ponto em escalas que variam por mais de cem pontos.
O que isso significa para pessoas que vivem com Parkinson
Para um leitor leigo, a mensagem chave é que um pequeno número de medições vocais cuidadosamente selecionadas, processadas por um pipeline de aprendizado bem projetado, pode acompanhar a severidade do Parkinson com precisão quase clínica — usando gravações feitas em casa. Embora o estudo ainda se baseie em um único conjunto de dados e precise ser testado em grupos maiores e mais variados de pacientes, ele demonstra um caminho promissor para a telemedicina prática: um futuro em que uma breve gravação de voz poderia ajudar pacientes e médicos a acompanhar a progressão da doença, ajustar medicamentos e possivelmente detectar pioras mais cedo, tudo isso sem uma ida à clínica.
Citação: Essam, M., Balat, M., Zaky, A.B. et al. Adaptive regression model for Parkinson’s disease diagnosis from speech signals using Box-Cox-based clustering and extremely randomization. Sci Rep 16, 14044 (2026). https://doi.org/10.1038/s41598-026-49065-2
Palavras-chave: Doença de Parkinson, Análise de voz, Aprendizado de máquina, Monitoramento remoto, Seleção de características