Clear Sky Science · sv
En skalbar hybridram för beräkningsintelligens med bioinspirerad optimering för inferens av skadliga URL:er i hög dimension
Varför det är viktigt att upptäcka dåliga länkar
De länkar vi klickar på varje dag kan tyst öppna dörren för bedrägerier, datastöld och datorinfektioner. Cyberbrottslingar hittar ständigt nya knep, så enkla blocklistor och reglerbaserade filter missar ofta nya angrepp. Denna studie undersöker ett smartare sätt att skilja säkra webbplatser från skadliga genom att kombinera flera typer av matematiska modeller med sökstrategier inspirerade av naturen, med målet att hålla upptäckten både träffsäker och begriplig för säkerhetsteam.
Från enkla regler till smartare försvar
Traditionella försvar mot skadliga webbplatser bygger på att kontrollera om en länk finns i en svartlista eller matchar kända mönster i texten eller sidans innehåll. Dessa metoder kan stoppa vissa hot, men de faller lätt när angripare förkläder adresser, byter dem ofta eller imiterar betrodda sidor. Artikeln hävdar att den snabbt föränderliga naturen hos nätbrottslighet kräver flexibla verktyg som kan lära av data, pröva hur tillförlitliga sina beslut är och visa vilka detaljer i en webbadress eller dess trafik som är mest avslöjande.
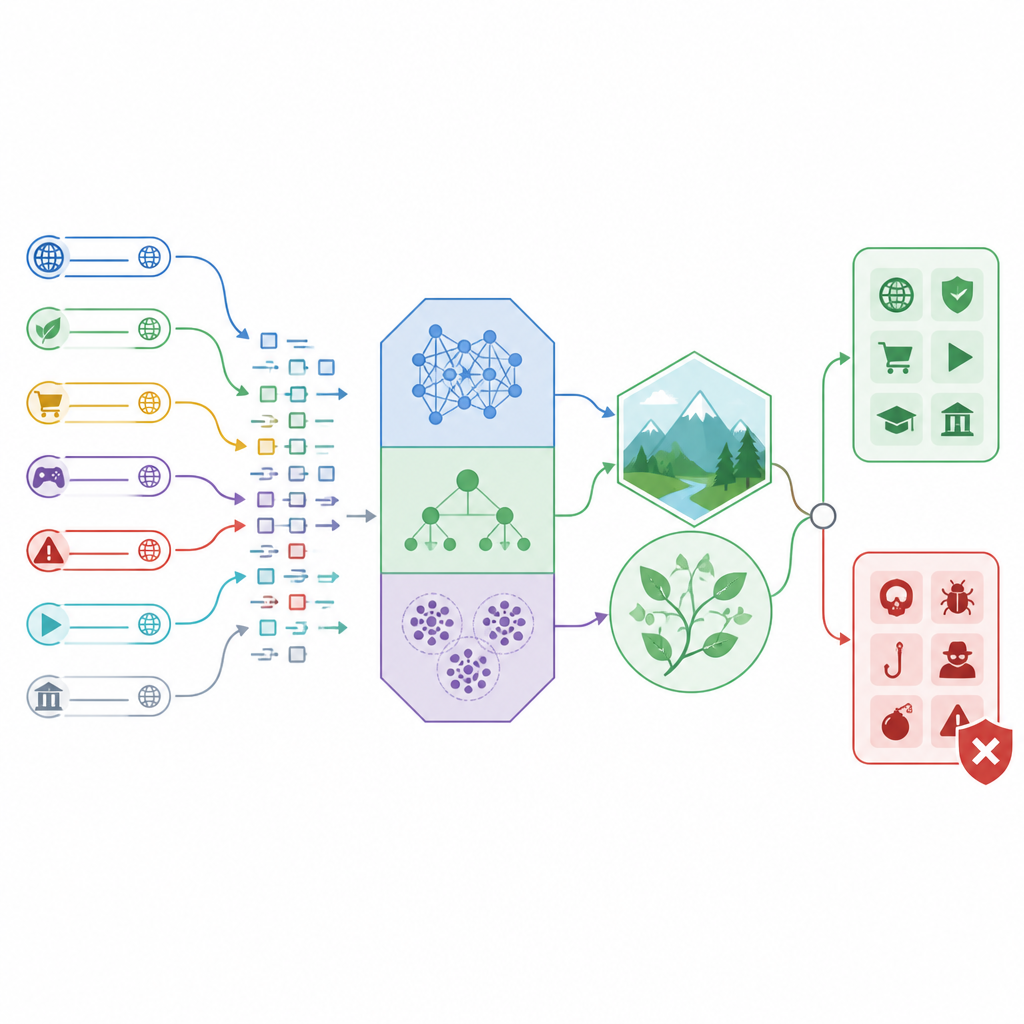
Hur den nya upptäcktsramen fungerar
Forskarnas uppbyggnad är en ”hybrid” upptäcktsram som blandar tre olika klassificerare med naturinspirerade finjusteringsmetoder. Två av klassificerarna, kallade linjär och kvadratisk diskriminantanalys, är bra på att dra tydliga gränser mellan säker och osäker trafik med enkla matematiska former. Den tredje, kallad CatBoost, är en kraftfull träd-baserad metod som kan hantera blandade typer av information, som siffror som beskriver hur lång en URL är, hur många ovanliga tecken den innehåller eller hur dess nätverkstrafik beter sig. Istället för att lita på standardinställningar använder studien två sökstrategier modellerade på en vårdande moder och en jaktfågel för att utforska många möjliga parameterinställningar och behålla de som fungerar bäst.
Vad modellerna lär sig från webben och nätverksledtrådar
Teamet använder en verklig dataset med 1 781 webbadresser, inklusive både ofarliga och skadliga, där varje adress beskrivs av detaljer hämtade från registreringsuppgifter, serverrespons och nätverksaktivitet. De undersöker först vilka informationsbitar som verkligen hjälper till att skilja bra från dåliga sidor. Statistiska tester visar att några enkla egenskaper sticker ut: hur många specialsymboler som förekommer i en länk, hur lång URL:en är, hur textkodningen är inställd, hur ofta adressen måste slås upp och hur många fjärrmaskiner som kontaktas. Genom att fokusera på dessa nyckelledtrådar undviker ramen att gå vilse i brus och gör sina beslut lättare att tolka.
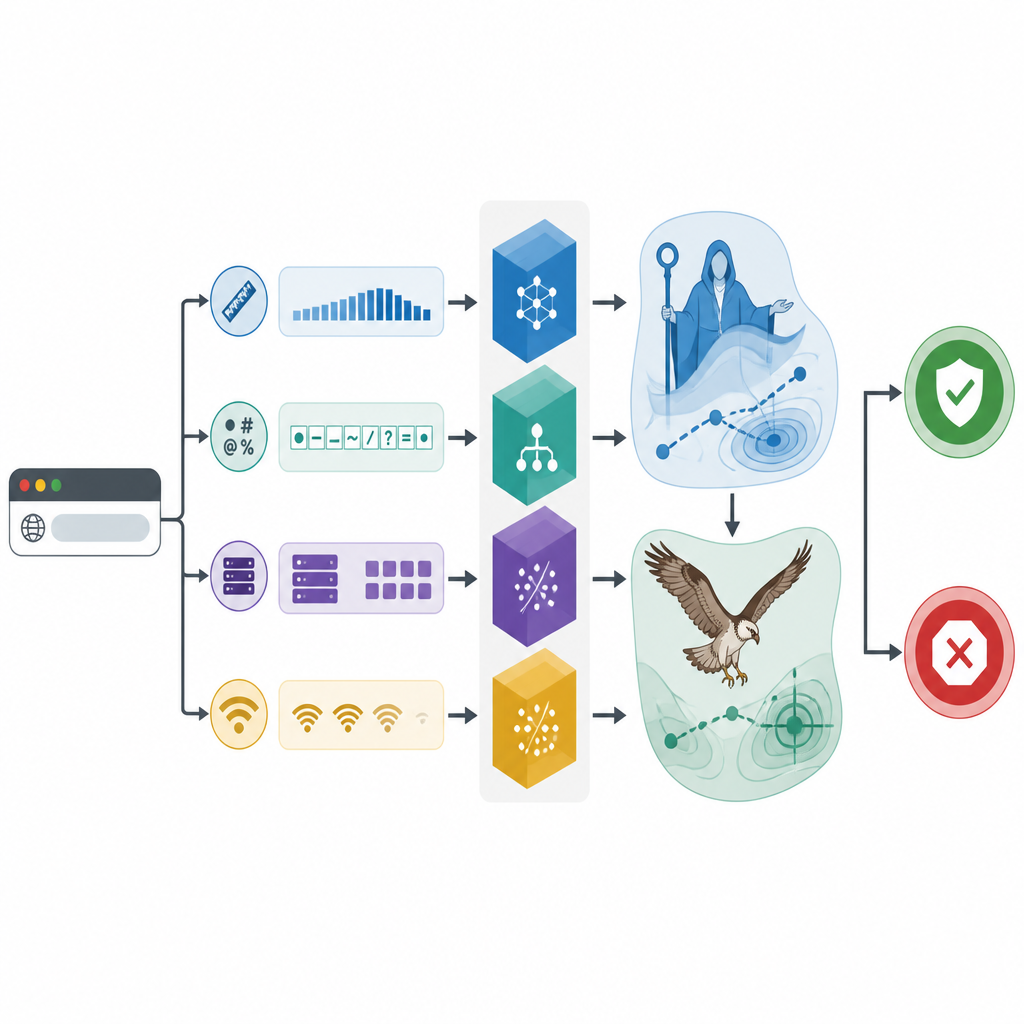
Naturinspirerad sökning skärper verktygen
Kärnan i studien ligger i att använda bioinspirerade sökalgoritmer för att finjustera de tre klassificerarna. En optimerare imiterar stadier av utbildning, råd och uppfostran och uppmuntrar en digital ”familj” av kandidatlösningar att först utforska brett och sedan förfina de bästa alternativen. Den andra kopierar hur en fiskgjuse upptäcker och bär byten, först genom att skanna vidsträckt och sedan koncentrera sig kring lovande regioner. Tillsammans justerar dessa metoder interna inställningar som hur komplexa besluts-träden bör vara eller hur starkt man ska jämna ut gränserna mellan klasser. Experiment med upprepad korsvalidering visar att varje klassificerare gynnas av denna finjustering, men den optimerade CatBoost-modellen, kallad CAMA, presterar bäst.
Starkare resultat och tydligare insikter
Över många tester överträffar de hybrida modellerna de enklare versionerna vad gäller noggrannhet, precision, recall och relaterade mått som väger missade hot mot falska larm. Den bästa modellen klassificerar korrekt cirka 96 procent av webbplatserna, samtidigt som antalet felaktigt blockerade säkra sidor hålls lågt. För att förhindra att systemet blir en mystisk svart låda tillämpar författarna en metod som tilldelar varje prediktion ett sett av ”krediter” som visar hur mycket varje funktion drev beslutet mot säkert eller osäkert. Detta avslöjar till exempel att ett högt antal ovanliga symboler och märkligt uppslagsbeteende för adressen är starka varningssignaler.
Vad detta betyder för vardaglig webbsäkerhet
För icke-specialister är budskapet att en handfull väl valda ledtrådar om webbadresser och deras trafik, undersökta av flera samarbetande modeller och finjusterade med idéer lånade från naturen, kan flagga farliga sidor med hög tillförlitlighet. Medan studien använder en relativt liten dataset och fortfarande behöver prövas på större, föränderliga strömmar av online-trafik, visar den att kombinationen av mångfald, noggrann sökning och tydliga förklaringar kan göra automatiserat försvar både skarpare och mer trovärdigt.
Citering: Liu, H. A scalable hybrid computational intelligence framework with bio inspired optimization for high dimensional malicious URL inference. Sci Rep 16, 14842 (2026). https://doi.org/10.1038/s41598-026-44851-4
Nyckelord: upptäckt av skadliga URL:er, cybersäkerhet, maskininlärning, bioinspirerad optimering, analys av webbtrafik