Clear Sky Science · ru
Масштабируемая гибридная платформа вычислительного интеллекта с био-вдохновленной оптимизацией для выявления вредоносных URL в высокоразмерных данных
Почему важно замечать плохие ссылки
Ссылки, по которым мы кликаем ежедневно, могут тихо открыть дверь для мошенничества, кражи данных и заражения устройств. Киберпреступники постоянно придумывают новые уловки, поэтому простые черные списки и правила часто пропускают свежие атаки. В этом исследовании рассматривается более умный способ отличать безопасные сайты от вредоносных, объединяя несколько типов математических моделей с поисковыми стратегиями, вдохновлёнными природой, чтобы обеспечить одновременно высокую точность и понятность для команд безопасности.
От простых правил к более умным защита
Традиционные методы защиты от вредоносных сайтов опираются на проверку наличия ссылки в черном списке или соответствия известным шаблонам в тексте или содержимом страницы. Эти подходы останавливают некоторые угрозы, но легко терпят неудачу, когда атакующие маскируют адреса, часто их меняют или имитируют доверенные ресурсы. Авторы утверждают, что быстро меняющаяся природа онлайн-преступлений требует гибких инструментов, которые могут учиться по данным, оценивать надёжность своих решений и показывать, какие детали URL или трафика наиболее показательны.
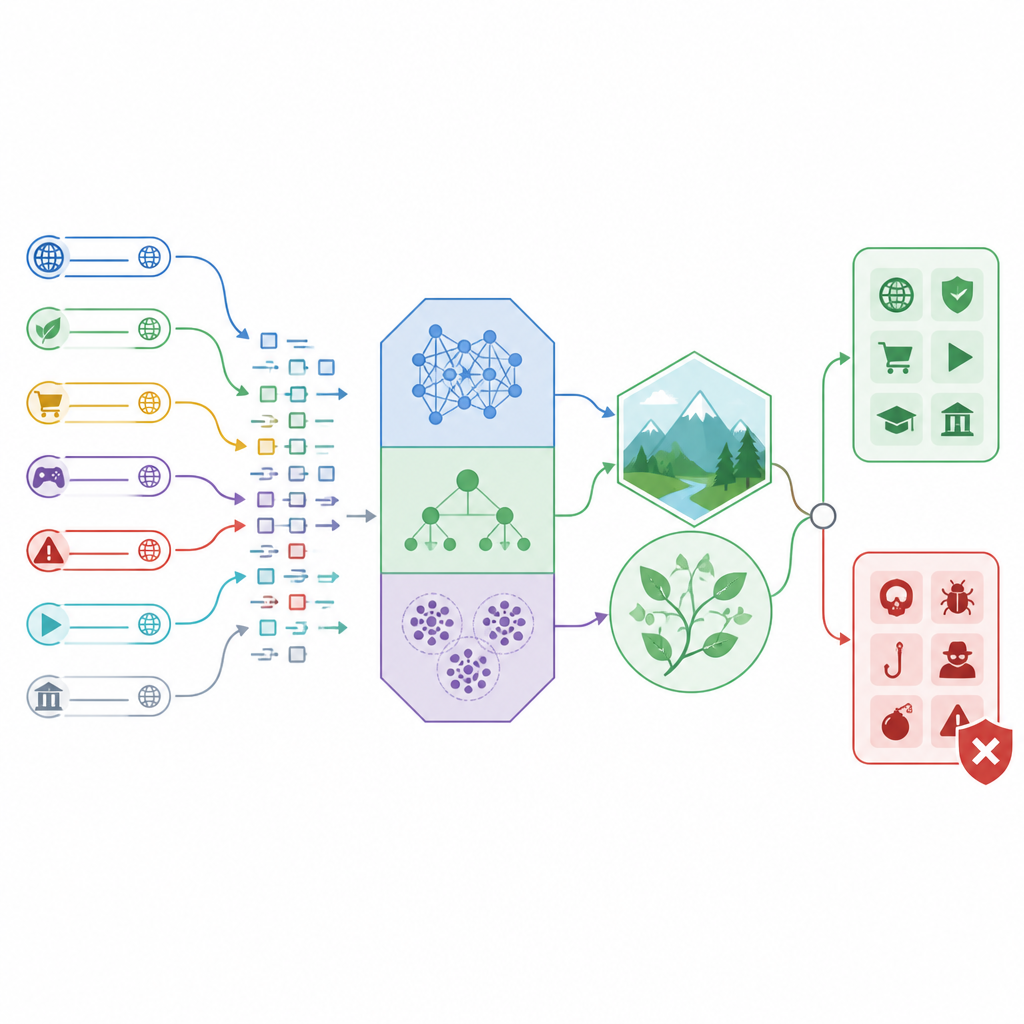
Как работает новая платформа обнаружения
Исследователи построили «гибридную» платформу обнаружения, которая сочетает три разных классификатора с методами настройки, вдохновлёнными природой. Два классификатора, называемые линейным и квадратичным дискриминантным анализом, хорошо проводят чёткие границы между безопасным и небезопасным трафиком с помощью простых математических форм. Третий, CatBoost, — мощный метод на основе деревьев, который умеет работать со смешанными типами информации: числовыми характеристиками длины URL, количеством необычных символов или поведением сетевого трафика. Вместо того чтобы полагаться на настройки по умолчанию, в работе используются две поисковые стратегии, смоделированные по образу заботливой матери и охотящейся птицы, чтобы исследовать множество параметров и сохранять те, которые работают лучше всего.
Чему модели учатся по подсказкам из веба и сети
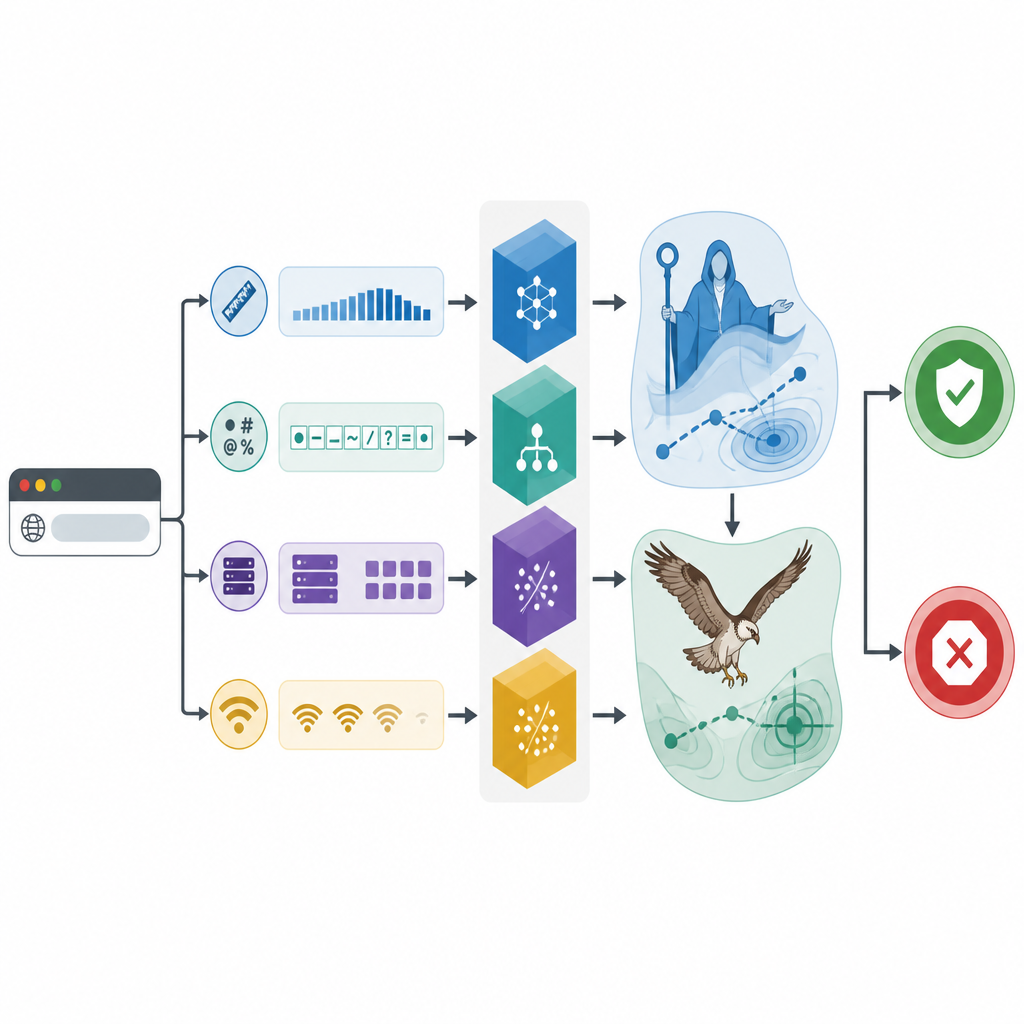
Команда использует реальную выборку из 1781 веб-адреса, включающую как безвредные, так и вредоносные ресурсы, каждый описан деталями из записей о регистрации, ответов серверов и сетевой активности. Сначала исследователи изучают, какие данные действительно помогают отделять хорошие сайты от плохих. Статистические тесты показывают, что выделяются несколько простых признаков: число специальных символов в ссылке, длина URL, кодировка текста, частота обращений к разрешению адреса и количество удалённых машин, с которыми устанавливается связь. Сфокусировавшись на этих ключевых подсказках, платформа избегает шума и делает решения более интерпретируемыми.
Био-вдохновленный поиск улучшает инструменты
Сердце исследования — применение био-вдохновленных поисковых алгоритмов для тонкой настройки трёх классификаторов. Один оптимизатор имитирует стадии обучения, советов и воспитания, побуждая цифровую «семью» кандидатных решений широко исследовать пространство, а потом уточнять лучшие варианты. Другой копирует, как орлан замечает и переносит добычу, сначала сканируя широко, а затем сосредотачиваясь вокруг перспективных областей. Вместе эти методы настраивают внутренние параметры — например, насколько сложными должны быть деревья решений или как сильно сглаживать границы между классами. Эксперименты с многократной перекрёстной проверкой показывают, что каждый классификатор выигрывает от такой настройки, но оптимизированная модель CatBoost, названная CAMA, демонстрирует наилучшие результаты.
Лучшие результаты и более ясные выводы
В многочисленных тестах гибридные модели превосходят более простые варианты по точности, точности положительных срабатываний (precision), полноте (recall) и другим мерам, балансирующим пропущенные угрозы и ложные срабатывания. Лучший классификатор правильно определяет примерно 96 процентов сайтов, при этом сохраняя низкое число ошибочно заблокированных безопасных ресурсов. Чтобы система не превращалась в таинственную «чёрную коробку», авторы применяют метод, присваивающий каждой прогнозируемой метке набор «кредитов», показывающих, насколько каждый признак сдвигает решение в сторону безопасного или небезопасного. Это выявляет, например, что большое число странных символов и необычное поведение при разрешении адреса являются сильными признаками опасности.
Что это означает для повседневной безопасности в сети
Для неспециалистов вывод прост: несколько хорошо подобранных подсказок о веб-адресах и их трафике, проанализированные несколькими сотрудничающими моделями и откалиброванные с идеями, заимствованными у природы, могут с высокой надёжностью обозначать опасные сайты. Хотя исследование использует умеренную по размеру выборку и требует дальнейшего тестирования на больших, меняющихся потоках онлайн-трафика, оно демонстрирует, что сочетание разнообразия, тщательного поиска и понятных объяснений может сделать автоматизированную защиту одновременно остроумнее и более заслуживающей доверия.
Цитирование: Liu, H. A scalable hybrid computational intelligence framework with bio inspired optimization for high dimensional malicious URL inference. Sci Rep 16, 14842 (2026). https://doi.org/10.1038/s41598-026-44851-4
Ключевые слова: обнаружение вредоносных URL, кибербезопасность, машинное обучение, био-вдохновленная оптимизация, анализ веб-трафика