Clear Sky Science · nl
Een schaalbaar hybride kader voor computationele intelligentie met bio-geïnspireerde optimalisatie voor hoog-dimensionale detectie van kwaadaardige URL's
Waarom het belangrijk is om slechte links te herkennen
De links die we dagelijks aanklikken kunnen stilletjes de deur openen naar oplichting, diefstal van gegevens en besmetting van computers. Cybercriminelen verzinnen voortdurend nieuwe trucs, dus eenvoudige blocklists en op regels gebaseerde filters missen vaak nieuwe aanvallen. Deze studie onderzoekt een slimere manier om veilige websites te onderscheiden van schadelijke door verschillende soorten wiskundige modellen te combineren met zoekstrategieën geïnspireerd op de natuur, met als doel detectie zowel nauwkeurig als begrijpelijk te houden voor securityteams.
Van eenvoudige regels naar slimmere verdediging
Traditionele verdedigingsmiddelen tegen kwaadaardige websites vertrouwen op het controleren of een link voorkomt op een blacklist of overeenkomt met bekende patronen in de tekst of paginacontent. Deze methoden kunnen sommige bedreigingen stoppen, maar falen makkelijk wanneer aanvallers adressen verhullen, ze vaak wijzigen of vertrouwde sites imiteren. De paper stelt dat de snel veranderende aard van online criminaliteit flexibele middelen vereist die uit data kunnen leren, de betrouwbaarheid van hun beslissingen kunnen testen en kunnen laten zien welke details van een webadres of het verkeer het meestzeggend zijn.
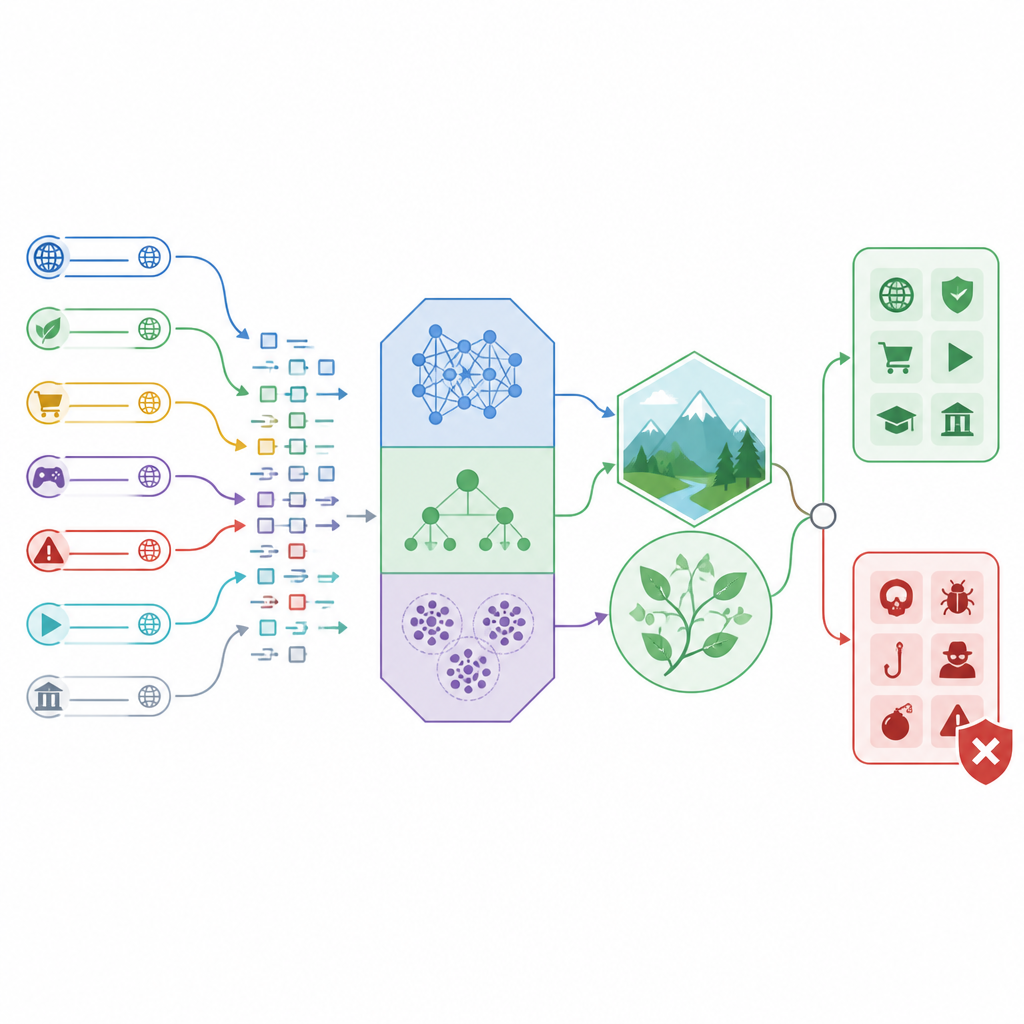
Hoe het nieuwe detectiekader werkt
De onderzoekers bouwen een “hybride” detectiekader dat drie verschillende classificatoren mengt met natuur-geïnspireerde afstemmingsmethoden. Twee van de classificatoren, lineaire en kwadratische discriminantanalyse genoemd, zijn goed in het trekken van duidelijke grenzen tussen veilig en onveilig verkeer met eenvoudige wiskundige vormen. De derde, CatBoost geheten, is een krachtig op bomen gebaseerd model dat om kan gaan met gemengde soorten informatie, zoals cijfers over de lengte van een URL, het aantal ongebruikelijke tekens of het gedrag van het netwerkverkeer. In plaats van te vertrouwen op standaardinstellingen gebruikt de studie twee zoekstrategieën die gemodelleerd zijn naar een zorgende moeder en een jagende vogel om vele mogelijke parameters te verkennen en die te behouden die het beste werken.
Wat de modellen leren van web- en netwerkclues
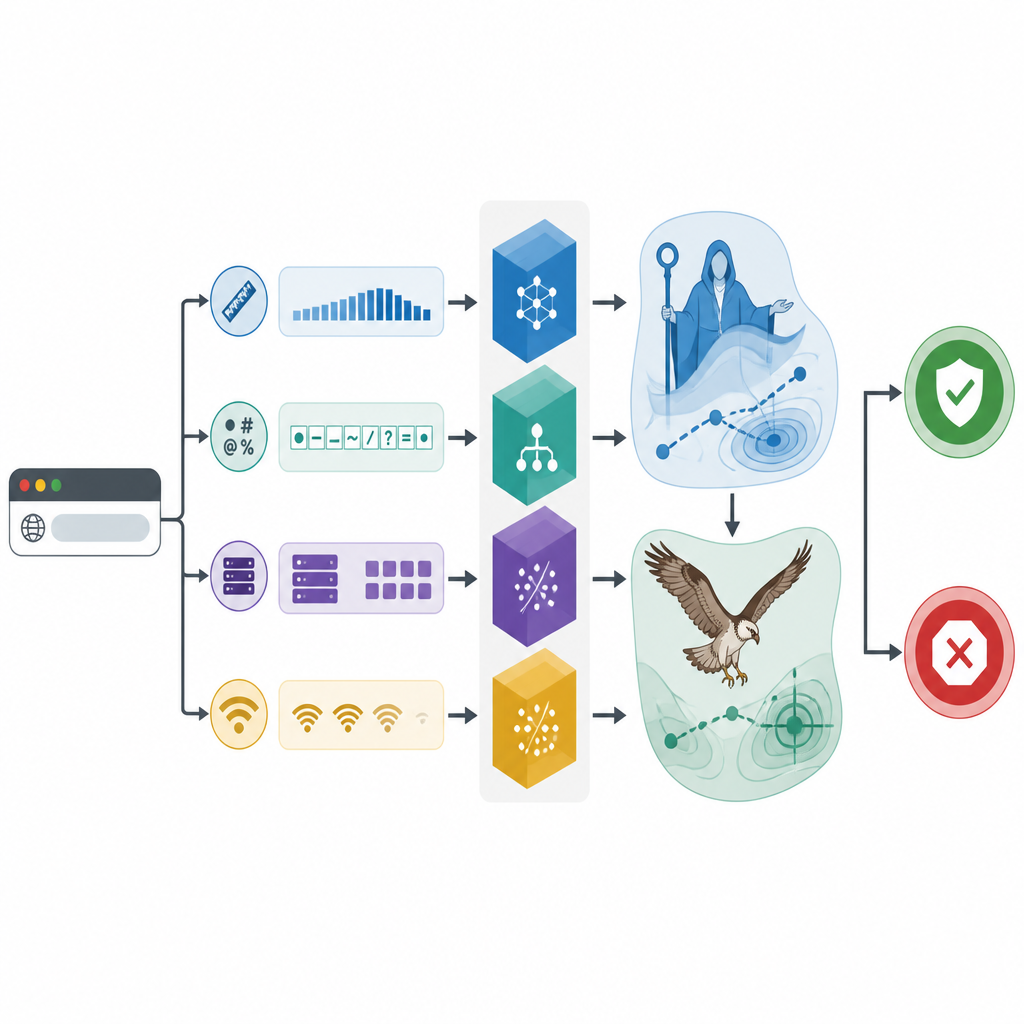
Het team gebruikt een realistische dataset van 1.781 webadressen, zowel onschadelijke als kwaadaardige, elk beschreven door gegevens uit registratiegegevens, serverantwoorden en netwerkactiviteit. Ze onderzoeken eerst welke informatie-stukken echt helpen om goede van slechte sites te scheiden. Statistische tests tonen aan dat een paar eenvoudige eigenschappen opvallen: hoeveel speciale symbolen in een link voorkomen, hoe lang de URL is, hoe de tekstcodering is ingesteld, hoe vaak het adres moet worden opgezocht en hoeveel externe machines worden aangesproken. Door zich op deze sleutelclues te richten, voorkomt het kader dat het verdwaalt in ruis en maakt het zijn beslissingen makkelijker te interpreteren.
Natuur-geïnspireerd zoeken verscherpt de instrumenten
De kern van het onderzoek ligt in het gebruik van bio-geïnspireerde zoekalgoritmen om de drie classificatoren fijn af te stemmen. Eén optimizer bootst stadia van opvoeding, advies en vorming na en moedigt een digitale “familie” van kandidaatoplossingen aan om breed te verkennen en daarna de beste opties te verfijnen. De andere kopieert de manier waarop een visarend prooi spot en vervoert: eerst ruim scannend en daarna concentrerend rond veelbelovende gebieden. Samen passen deze methoden interne instellingen aan, zoals hoe complex de beslissingsbomen moeten zijn of hoe sterk de grenzen tussen klassen moeten worden gesmooth. Experimenten met herhaalde kruisvalidatie laten zien dat elke classificator baat heeft bij deze afstemming, maar het geoptimaliseerde CatBoost-model, CAMA genoemd, presteert het best.
Sterkere resultaten en helderdere inzichten
In veel tests verslaan de hybride modellen de eenvoudigere varianten op nauwkeurigheid, precisie, recall en gerelateerde maten die gemiste bedreigingen afwegen tegen valse alarmen. Het beste model classificeert ongeveer 96 procent van de websites correct, terwijl het aantal onterecht geblokkeerde veilige sites laag blijft. Om te voorkomen dat het systeem een mysterieus black box wordt, passen de auteurs een methode toe die elke voorspelling een set “kredieten” toekent die laat zien hoeveel elk kenmerk de beslissing richting veilig of onveilig heeft geduwd. Dit onthult bijvoorbeeld dat een hoog aantal vreemde symbolen en ongewoon zoekgedrag van adressen sterke waarschuwingssignalen zijn.
Wat dit betekent voor alledaagse webveiligheid
Voor niet-specialisten is de boodschap dat een handvol goed gekozen aanwijzingen over webadressen en hun verkeer, onderzocht door meerdere samenwerkende modellen en afgestemd met ideeën uit de natuur, gevaarlijke sites met hoge betrouwbaarheid kan signaleren. Hoewel de studie een bescheiden dataset gebruikt en nog getest moet worden op grotere, veranderende stromen van online verkeer, laat het zien dat het combineren van diversiteit, zorgvuldige zoekmethoden en duidelijke verklaringen geautomatiseerde verdedigingssystemen zowel scherper als betrouwbaarder kan maken.
Bronvermelding: Liu, H. A scalable hybrid computational intelligence framework with bio inspired optimization for high dimensional malicious URL inference. Sci Rep 16, 14842 (2026). https://doi.org/10.1038/s41598-026-44851-4
Trefwoorden: detectie van kwaadaardige URL's, cybersecurity, machine learning, bio-geïnspireerde optimalisatie, analyse van webverkeer