Clear Sky Science · fr
Un cadre d’intelligence computationnelle hybride et évolutif avec optimisation bio-inspirée pour l’inférence d’URL malveillantes en grande dimension
Pourquoi repérer les mauvais liens importe
Les liens que nous cliquons chaque jour peuvent ouvrir discrètement la porte à des arnaques, au vol de données et aux infections informatiques. Les cybercriminels inventent sans cesse de nouvelles ruses, de sorte que les listes noires et les filtres basés sur des règles ratent souvent les attaques récentes. Cette étude explore une manière plus intelligente de distinguer les sites sûrs des sites malveillants en combinant plusieurs types de modèles mathématiques avec des stratégies de recherche inspirées de la nature, visant à maintenir la détection à la fois précise et compréhensible pour les équipes de sécurité.
Des règles simples à des défenses plus intelligentes
Les défenses traditionnelles contre les sites malveillants reposent sur la vérification d’un lien dans une liste noire ou la détection de motifs connus dans son texte ou le contenu de la page. Ces méthodes peuvent stopper certaines menaces, mais elles échouent facilement lorsque les attaquants déguisent les adresses, les modifient souvent ou imitent des sites de confiance. L’article soutient que la nature en évolution rapide de la cybercriminalité appelle des outils flexibles capables d’apprendre à partir des données, d’évaluer la fiabilité de leurs décisions et de révéler quelles caractéristiques d’une adresse web ou de son trafic sont les plus significatives.
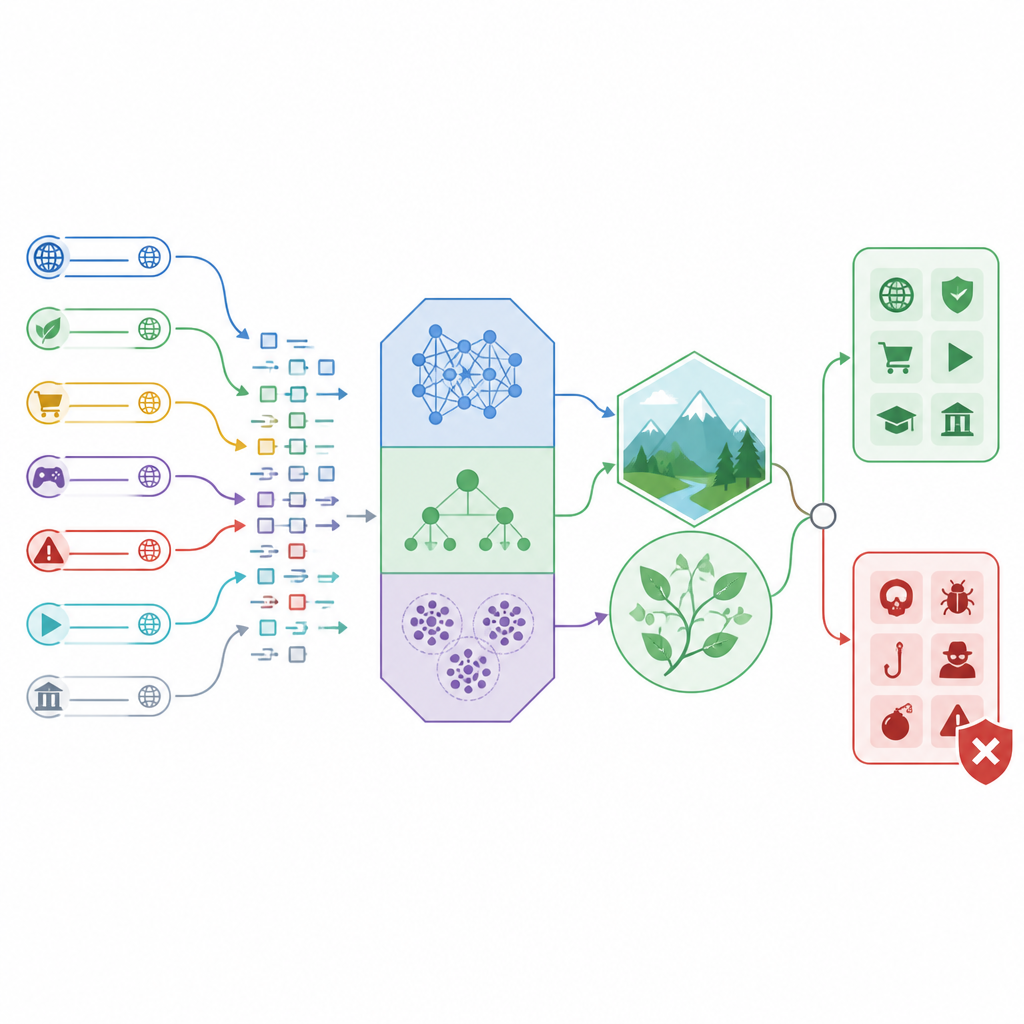
Comment fonctionne le nouveau cadre de détection
Les chercheurs construisent un cadre de détection « hybride » qui mêle trois classificateurs différents avec des méthodes d’ajustement inspirées de la nature. Deux des classificateurs, appelés analyse discriminante linéaire et quadratique, excellent à tracer des frontières claires entre trafic sûr et dangereux en utilisant des formes mathématiques simples. Le troisième, nommé CatBoost, est une méthode puissante basée sur des arbres capable de traiter des types d’information mixtes, comme des nombres décrivant la longueur d’une URL, le nombre de caractères inhabituels qu’elle contient, ou le comportement de son trafic réseau. Plutôt que de se fier aux réglages par défaut, l’étude utilise deux stratégies de recherche modélisées sur une mère protectrice et un oiseau de proie pour explorer de nombreux jeux de paramètres possibles et conserver ceux qui fonctionnent le mieux.
Ce que les modèles apprennent des indices web et réseau
L’équipe utilise un jeu de données réel de 1 781 adresses web, comprenant à la fois des sites inoffensifs et malveillants, chacune décrite par des détails tirés des registres d’enregistrement, des réponses serveur et de l’activité réseau. Ils examinent d’abord quelles informations aident réellement à séparer les bons des mauvais sites. Des tests statistiques montrent que quelques traits simples se distinguent : combien de symboles spéciaux apparaissent dans un lien, la longueur de l’URL, le codage du texte, la fréquence des recherches de l’adresse du site, et le nombre de machines distantes contactées. En se concentrant sur ces indices clés, le cadre évite de se perdre dans le bruit et rend ses décisions plus faciles à interpréter.
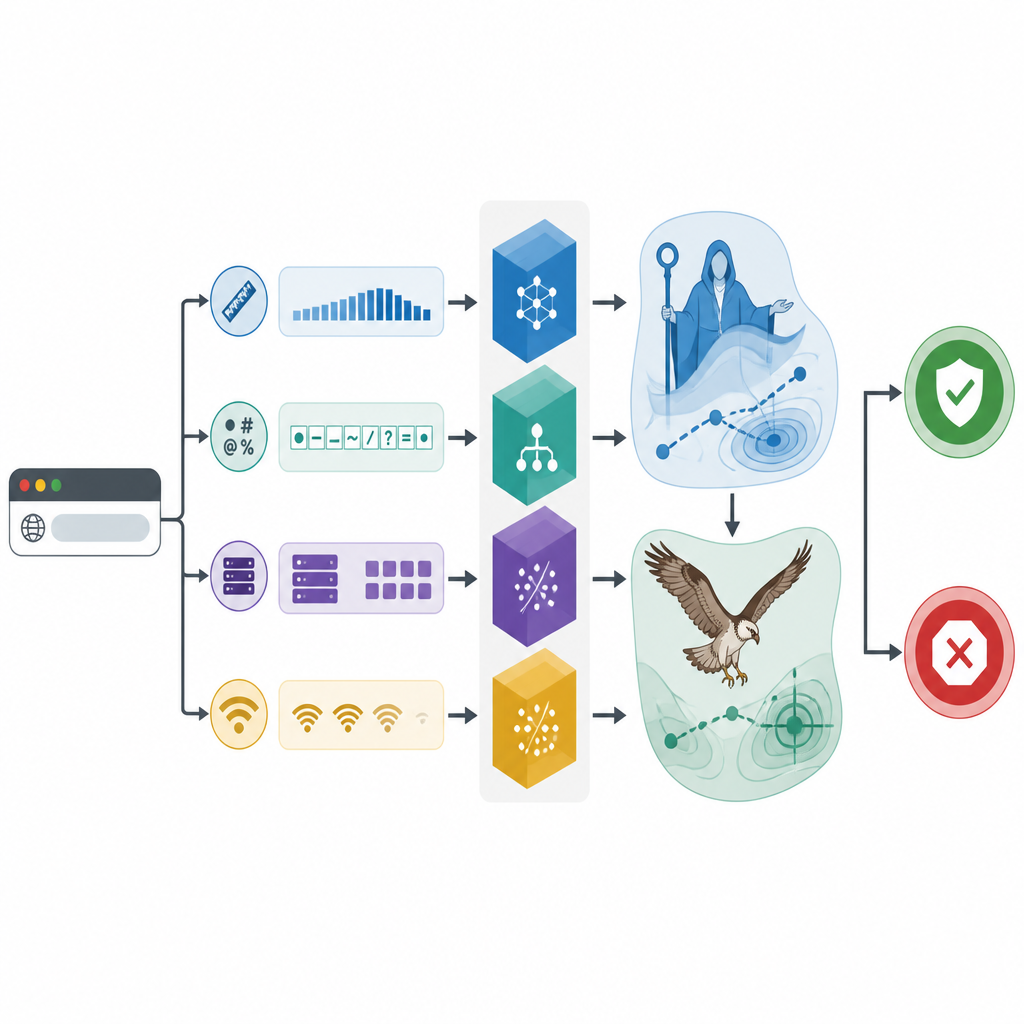
La recherche bio-inspirée affine les outils
Le cœur de l’étude réside dans l’utilisation d’algorithmes de recherche bio-inspirés pour régler finement les trois classificateurs. Un optimiseur imite des phases d’éducation, de conseil et d’élevage, encourageant une « famille » numérique de solutions candidates à explorer largement puis à affiner les meilleures options. L’autre reproduit la manière dont un balbuzard repère et transporte sa proie, d’abord en balayage large puis en concentration autour de régions prometteuses. Ensemble, ces méthodes ajustent des paramètres internes comme la complexité des arbres de décision ou le degré de lissage des frontières entre classes. Des expériences avec validation croisée répétée montrent que chaque classificateur bénéficie de cet ajustement, mais que le modèle CatBoost optimisé, appelé CAMA, donne les meilleures performances.
Des résultats plus solides et des insights plus clairs
Sur de nombreux tests, les modèles hybrides surpassent les versions plus simples en précision, exactitude, rappel et autres mesures équilibrant menaces manquées et fausses alertes. Le meilleur modèle classe correctement environ 96 % des sites web, tout en maintenant un faible nombre de sites sûrs bloqués par erreur. Pour éviter que le système ne devienne une boîte noire mystérieuse, les auteurs appliquent une méthode qui attribue à chaque prédiction un ensemble de « crédits » montrant dans quelle mesure chaque caractéristique a poussé la décision vers sûr ou dangereux. Cela révèle, par exemple, qu’un nombre élevé de symboles étranges et un comportement inhabituel dans la recherche d’adresse sont de forts signaux d’alerte.
Ce que cela signifie pour la sécurité web de tous les jours
Pour les non-spécialistes, le message est qu’une poignée d’indices bien choisis sur les adresses web et leur trafic, examinés par plusieurs modèles coopérants et réglés avec des idées empruntées à la nature, peuvent signaler les sites dangereux avec une grande fiabilité. Bien que l’étude utilise un jeu de données de taille modeste et nécessite encore des tests sur des flux plus larges et changeants du trafic en ligne, elle montre que combiner diversité, recherche soignée et explications claires peut rendre les défenses automatisées à la fois plus précises et plus dignes de confiance.
Citation: Liu, H. A scalable hybrid computational intelligence framework with bio inspired optimization for high dimensional malicious URL inference. Sci Rep 16, 14842 (2026). https://doi.org/10.1038/s41598-026-44851-4
Mots-clés: détection d’URL malveillantes, cybersécurité, apprentissage automatique, optimisation bio-inspirée, analyse du trafic web