Clear Sky Science · pt
Uma estrutura híbrida de inteligência computacional escalável com otimização bioinspirada para inferência de URLs maliciosas de alta dimensão
Por que identificar links perigosos é importante
Os links que clicamos todos os dias podem, silenciosamente, abrir portas para golpes, roubo de dados e infecções em computadores. Cibercriminosos inventam constantemente novos truques, portanto listas de bloqueio simples e filtros baseados em regras muitas vezes deixam passar ataques recentes. Este estudo explora um modo mais inteligente de distinguir sites seguros de nocivos, combinando vários tipos de modelos matemáticos com estratégias de busca inspiradas na natureza, com o objetivo de manter a detecção precisa e compreensível para equipes de segurança.
De regras simples a defesas mais inteligentes
Defesas tradicionais contra sites maliciosos dependem de verificar se um link consta em uma lista negra ou corresponde a padrões conhecidos no seu texto ou conteúdo de página. Esses métodos podem impedir algumas ameaças, mas falham facilmente quando atacantes disfarçam endereços, os alteram com frequência ou imitam sites confiáveis. O artigo argumenta que a natureza em rápida mudança do crime online exige ferramentas flexíveis que aprendam a partir dos dados, testem quão confiáveis são suas decisões e revelem quais detalhes de um endereço web ou do seu tráfego são mais indicativos.
Como a nova estrutura de detecção funciona
Os pesquisadores constroem uma estrutura de detecção “híbrida” que mistura três classificadores diferentes com métodos de ajuste inspirados na natureza. Dois dos classificadores, chamados análise discriminante linear e quadrática, são bons em traçar limites claros entre tráfego seguro e inseguro usando formas matemáticas simples. O terceiro, denominado CatBoost, é um poderoso método baseado em árvores que lida com tipos mistos de informação, como números que descrevem o comprimento de uma URL, quantos caracteres incomuns ela contém ou como seu tráfego de rede se comporta. Em vez de confiar em configurações padrão, o estudo utiliza duas estratégias de busca modeladas em uma mãe cuidadora e em uma ave de rapina para explorar muitas combinações de parâmetros e conservar as que funcionam melhor.
O que os modelos aprendem a partir de pistas web e de rede
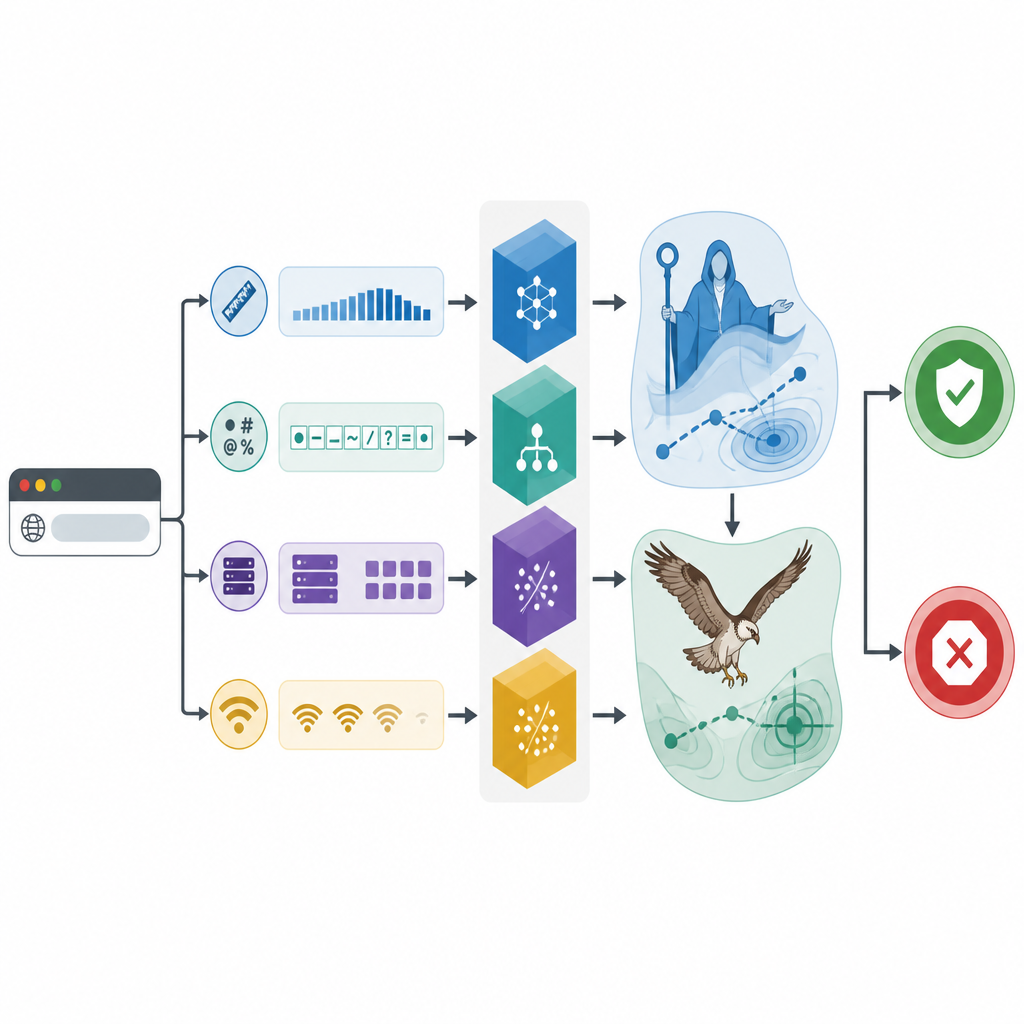
A equipe usa um conjunto de dados do mundo real com 1.781 endereços de sites, incluindo tanto benignos quanto maliciosos, cada um descrito por detalhes extraídos de registros de registro, respostas de servidor e atividade de rede. Primeiro eles examinam quais peças de informação realmente ajudam a separar sites bons de ruins. Testes estatísticos mostram que algumas características simples se destacam: quantos símbolos especiais aparecem em um link, o comprimento da URL, como a codificação de texto está definida, com que frequência o endereço do site precisa ser consultado e quantas máquinas remotas são contatadas. Ao focar nessas pistas-chave, a estrutura evita se perder em ruído e torna suas decisões mais fáceis de interpretar.
Busca bioinspirada aprimora as ferramentas
O cerne do estudo está no uso de algoritmos de busca bioinspirados para ajustar finamente os três classificadores. Um otimizador imita estágios de educação, conselho e criação, encorajando uma “família” digital de soluções candidatas a explorar amplamente e então refinar as melhores opções. O outro copia a forma como um gavião-pescador (osprey) avista e carrega a presa, primeiro escaneando amplamente e depois concentrando-se em regiões promissoras. Juntos, esses métodos ajustam configurações internas como quão complexas devem ser as árvores de decisão ou quão fortemente suavizar os limites entre classes. Experimentos com validação cruzada repetida mostram que todo classificador se beneficia desse ajuste, mas o modelo CatBoost otimizado, chamado CAMA, tem o melhor desempenho.
Resultados mais fortes e insights mais claros
Em diversos testes, os modelos híbridos superam as versões mais simples em acurácia, precisão, recall e medidas relacionadas que equilibram ameaças não detectadas e falsos positivos. O modelo principal classifica corretamente cerca de 96% dos sites, mantendo também baixo o número de sites seguros bloqueados indevidamente. Para evitar que o sistema se torne uma caixa-preta misteriosa, os autores aplicam um método que atribui a cada previsão um conjunto de “créditos” mostrando quanto cada característica empurrou a decisão em direção a seguro ou inseguro. Isso revela, por exemplo, que uma contagem elevada de símbolos estranhos e comportamento incomum de consultas ao endereço são fortes sinais de perigo.
O que isso significa para a segurança web do dia a dia
Para não especialistas, a mensagem é que um punhado de pistas bem escolhidas sobre endereços web e seu tráfego, examinadas por vários modelos cooperantes e ajustadas com ideias emprestadas da natureza, pode sinalizar sites perigosos com alta confiabilidade. Embora o estudo utilize um conjunto de dados de tamanho modesto e ainda precise ser testado em fluxos maiores e dinâmicos de tráfego online, ele mostra que combinar diversidade, busca cuidadosa e explicações claras pode tornar defesas automatizadas mais afiadas e mais confiáveis.
Citação: Liu, H. A scalable hybrid computational intelligence framework with bio inspired optimization for high dimensional malicious URL inference. Sci Rep 16, 14842 (2026). https://doi.org/10.1038/s41598-026-44851-4
Palavras-chave: detecção de URL maliciosa, cibersegurança, aprendizado de máquina, otimização bioinspirada, análise de tráfego web