Clear Sky Science · es
Un marco de inteligencia computacional híbrido y escalable con optimización bioinspirada para la inferencia de URLs maliciosas en alta dimensión
Por qué importa detectar enlaces peligrosos
Los enlaces que pulsamos a diario pueden, sin avisar, abrir la puerta a estafas, robo de datos e infecciones informáticas. Los ciberdelincuentes inventan constantemente nuevas artimañas, por lo que las listas de bloqueo simples y los filtros basados en reglas suelen pasar por alto ataques recientes. Este estudio explora una manera más inteligente de distinguir sitios seguros de los dañinos combinando varios tipos de modelos matemáticos con estrategias de búsqueda inspiradas en la naturaleza, con el objetivo de mantener la detección precisa y comprensible para los equipos de seguridad.
De reglas simples a defensas más inteligentes
Las defensas tradicionales contra sitios maliciosos se basan en comprobar si un enlace aparece en una lista negra o si coincide con patrones conocidos en su texto o contenido de página. Estos métodos pueden detener algunas amenazas, pero fallan fácilmente cuando los atacantes disfrazan direcciones, las cambian con frecuencia o imitan sitios confiables. El artículo sostiene que la naturaleza cambiante del delito en línea exige herramientas flexibles que puedan aprender de los datos, evaluar la fiabilidad de sus decisiones y revelar qué detalles de una dirección web o su tráfico son más informativos.
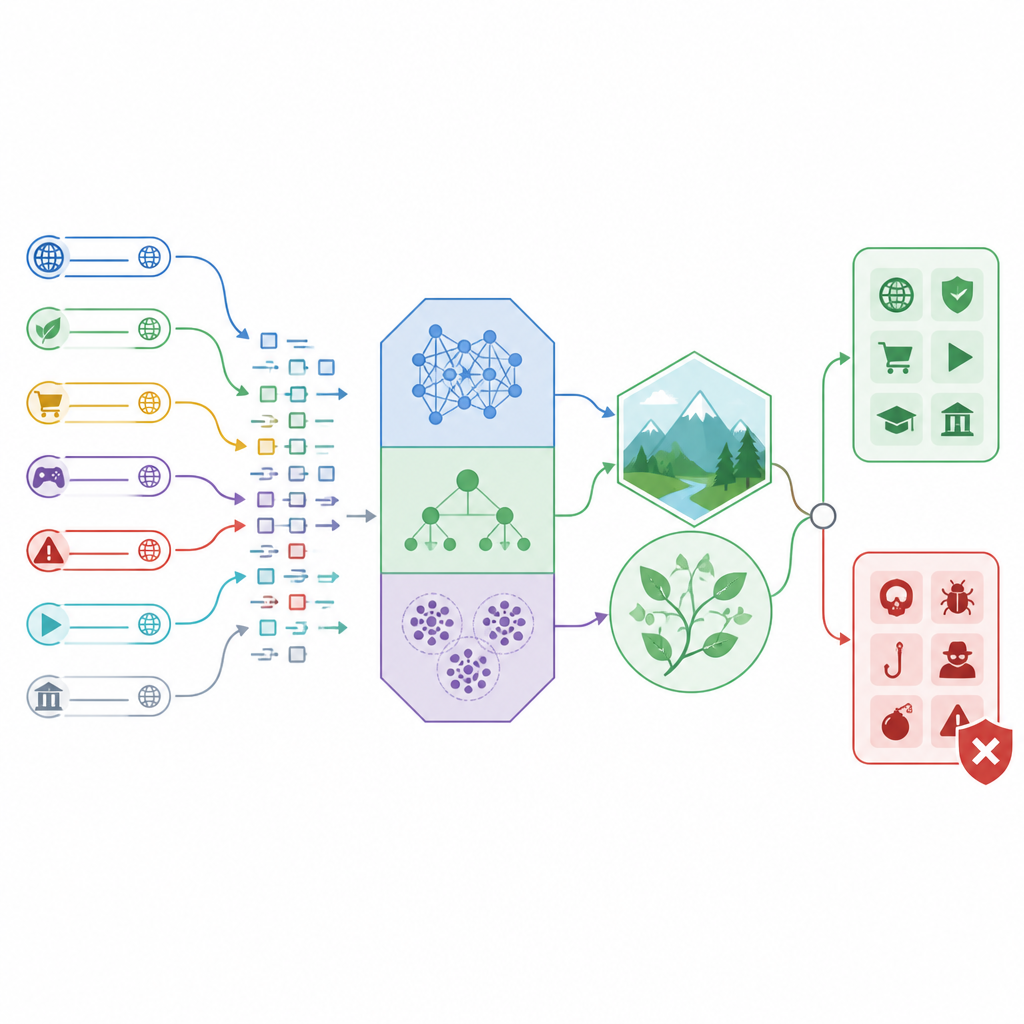
Cómo funciona el nuevo marco de detección
Los investigadores construyen un marco de detección “híbrido” que combina tres clasificadores diferentes con métodos de ajuste inspirados en la naturaleza. Dos de los clasificadores, llamados análisis discriminante lineal y cuadrático, son buenos trazando fronteras claras entre tráfico seguro e inseguro usando formas matemáticas sencillas. El tercero, denominado CatBoost, es un potente método basado en árboles que puede manejar tipos de información mixtos, como números que describen la longitud de una URL, la cantidad de caracteres inusuales que contiene o cómo se comporta su tráfico de red. En lugar de confiar en configuraciones por defecto, el estudio utiliza dos estrategias de búsqueda modeladas en una madre protectora y un ave rapaz para explorar muchas posibles combinaciones de parámetros y conservar las que mejor funcionan.
Lo que los modelos aprenden de las pistas web y de red
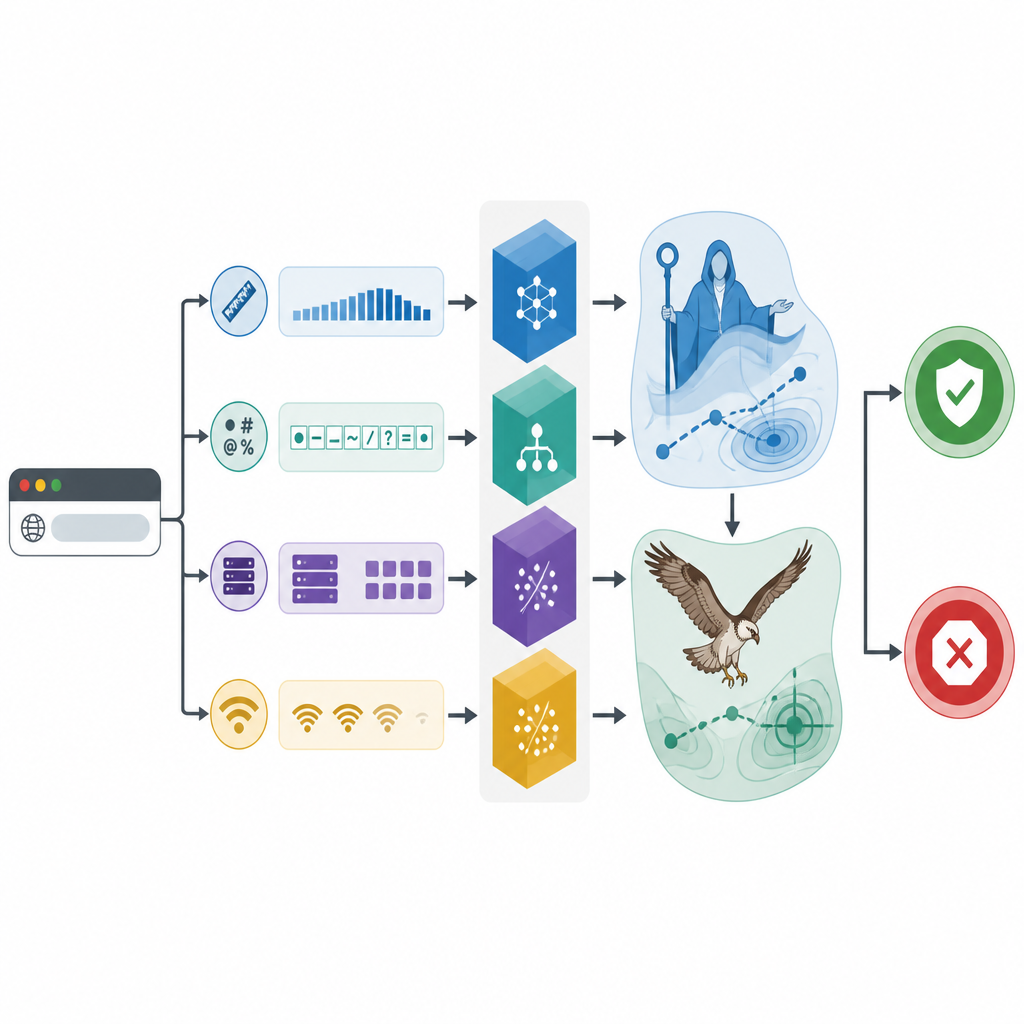
El equipo emplea un conjunto de datos real de 1.781 direcciones web, que incluye tanto sitios inofensivos como maliciosos, cada uno descrito por detalles extraídos de registros de registro, respuestas del servidor y actividad de red. Primero examinan qué piezas de información realmente ayudan a separar sitios buenos de malos. Pruebas estadísticas muestran que unas pocas características simples destacan: cuántos símbolos especiales aparecen en un enlace, la longitud de la URL, cómo está configurada la codificación del texto, con qué frecuencia hay que resolver la dirección del sitio y cuántas máquinas remotas se contactan. Al centrarse en estas pistas clave, el marco evita perderse en el ruido y hace que sus decisiones sean más fáciles de interpretar.
La búsqueda bioinspirada afina las herramientas
El núcleo del estudio reside en usar algoritmos de búsqueda bioinspirados para afinar los tres clasificadores. Un optimizador imita etapas de educación, consejo y crianza, fomentando que una “familia” digital de soluciones candidatas explore ampliamente y luego refine las mejores opciones. El otro copia la manera en que un águila pescadora detecta y transporta presas, primero escaneando de forma amplia y luego concentrándose alrededor de regiones prometedoras. Juntos, estos métodos ajustan configuraciones internas como cuán complejos deben ser los árboles de decisión o con qué fuerza suavizar las fronteras entre clases. Experimentos con validación cruzada repetida muestran que todos los clasificadores se benefician de este ajuste, pero el modelo CatBoost optimizado, llamado CAMA, ofrece el mejor rendimiento.
Resultados más sólidos y conocimientos más claros
En numerosas pruebas, los modelos híbridos superan a las versiones más simples en precisión, exactitud, recall y medidas relacionadas que equilibran las amenazas no detectadas frente a las falsas alarmas. El modelo superior clasifica correctamente alrededor del 96 por ciento de los sitios web, manteniendo al mismo tiempo bajo el número de sitios seguros bloqueados por error. Para evitar que el sistema se convierta en una caja negra misteriosa, los autores aplican un método que asigna a cada predicción un conjunto de “créditos” que muestran cuánto cada característica empujó la decisión hacia segura o no segura. Esto revela, por ejemplo, que un alto recuento de símbolos extraños y un comportamiento inusual en la resolución de direcciones son advertencias fuertes de peligro.
Qué supone esto para la seguridad web cotidiana
Para los no especialistas, el mensaje es que una mano de pistas bien elegidas sobre direcciones web y su tráfico, examinadas por varios modelos que cooperan y afinadas con ideas tomadas de la naturaleza, pueden señalar sitios peligrosos con alta fiabilidad. Aunque el estudio usa un conjunto de datos de tamaño moderado y aún necesita probarse en flujos más grandes y cambiantes de tráfico en línea, demuestra que combinar diversidad, búsqueda cuidadosa y explicaciones claras puede hacer que las defensas automatizadas sean tanto más agudas como más confiables.
Cita: Liu, H. A scalable hybrid computational intelligence framework with bio inspired optimization for high dimensional malicious URL inference. Sci Rep 16, 14842 (2026). https://doi.org/10.1038/s41598-026-44851-4
Palabras clave: detección de URL maliciosas, ciberseguridad, aprendizaje automático, optimización bioinspirada, análisis del tráfico web