Clear Sky Science · pl
Skalowalna hybrydowa rama inteligencji obliczeniowej z bioinspirowaną optymalizacją do analizy złośliwych URL-ów o wysokiej wymiarowości
Dlaczego wykrywanie złych linków ma znaczenie
Linki, które klikamy codziennie, mogą cicho otworzyć drzwi do oszustw, kradzieży danych i infekcji komputerów. Cyberprzestępcy nieustannie wymyślają nowe sztuczki, dlatego proste listy blokujące i filtry oparte na regułach często nie wykrywają świeżych ataków. W badaniu opisano mądrzejszy sposób rozróżniania bezpiecznych stron od szkodliwych przez połączenie kilku rodzajów modeli matematycznych z strategiami poszukiwań inspirowanymi naturą, mając na celu zachowanie wykrywania zarówno dokładnego, jak i zrozumiałego dla zespołów zajmujących się bezpieczeństwem.
Od prostych reguł do inteligentniejszych obron
Tradycyjne środki ochrony przed złośliwymi stronami opierają się na sprawdzaniu, czy link znajduje się na czarnej liście lub czy pasuje do znanych wzorców w tekście lub zawartości strony. Metody te potrafią zatrzymać niektóre zagrożenia, ale zawodzą, gdy atakujący maskują adresy, często je zmieniają lub podszywają się pod zaufane witryny. Artykuł argumentuje, że szybko zmieniający się charakter przestępczości online wymaga elastycznych narzędzi, które potrafią uczyć się na danych, oceniać wiarygodność swoich decyzji i ujawniać, które elementy adresu WWW lub ruchu sieciowego są najbardziej informatywne.
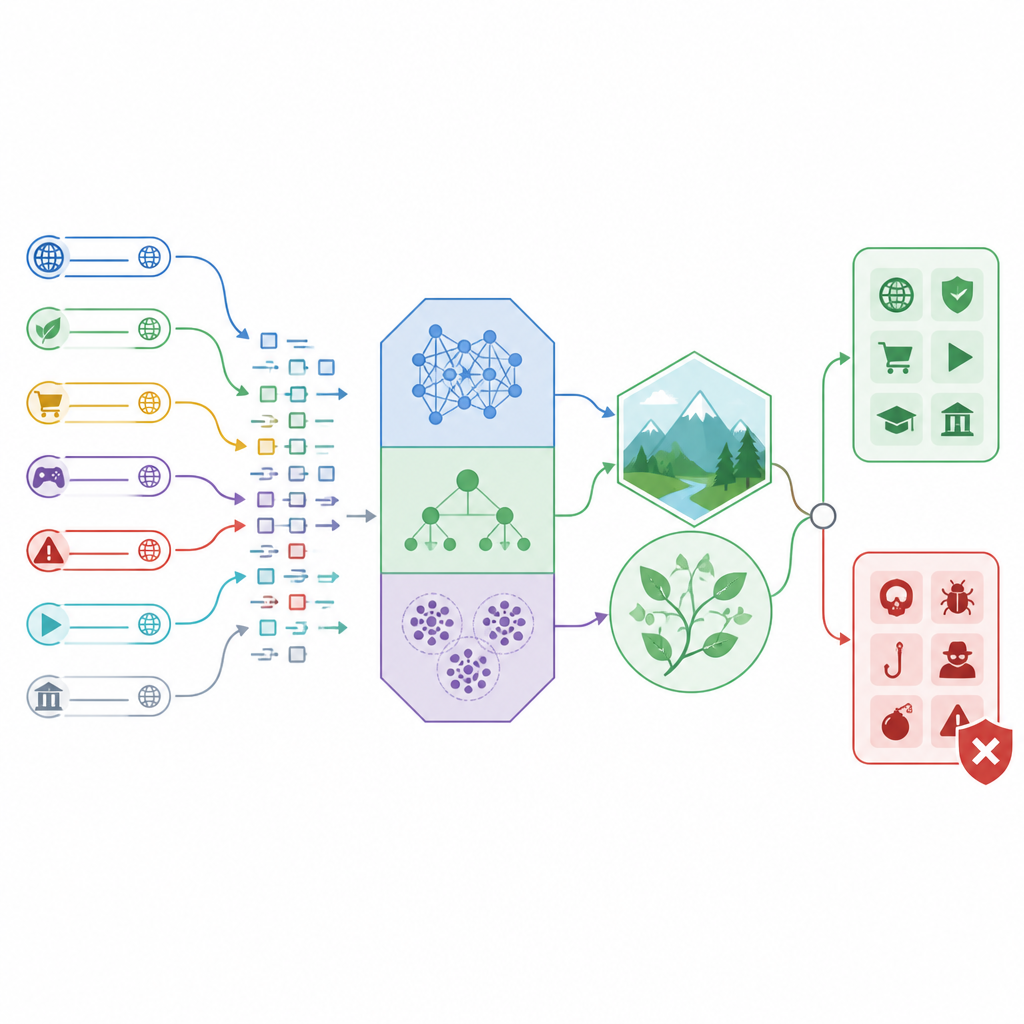
Jak działa nowa rama wykrywania
Naukowcy zbudowali „hybrydową” ramę wykrywania, która łączy trzy różne klasyfikatory z bioinspirowanymi metodami strojenia. Dwa z klasyfikatorów, zwane liniową i kwadratową analizą dyskryminacyjną, dobrze nadają się do wyznaczania wyraźnych granic między bezpiecznym a niebezpiecznym ruchem przy użyciu prostych kształtów matematycznych. Trzeci, o nazwie CatBoost, to potężna metoda oparta na drzewach, która radzi sobie z mieszanymi typami informacji, takimi jak liczby opisujące długość URL-a, liczbę nietypowych znaków czy zachowanie w ruchu sieciowym. Zamiast polegać na ustawieniach domyślnych, badanie wykorzystuje dwie strategie poszukiwań wzorowane na troskliwej matce i ptaku drapieżnym, aby przeszukać wiele możliwych konfiguracji parametrów i zachować te, które działają najlepiej.
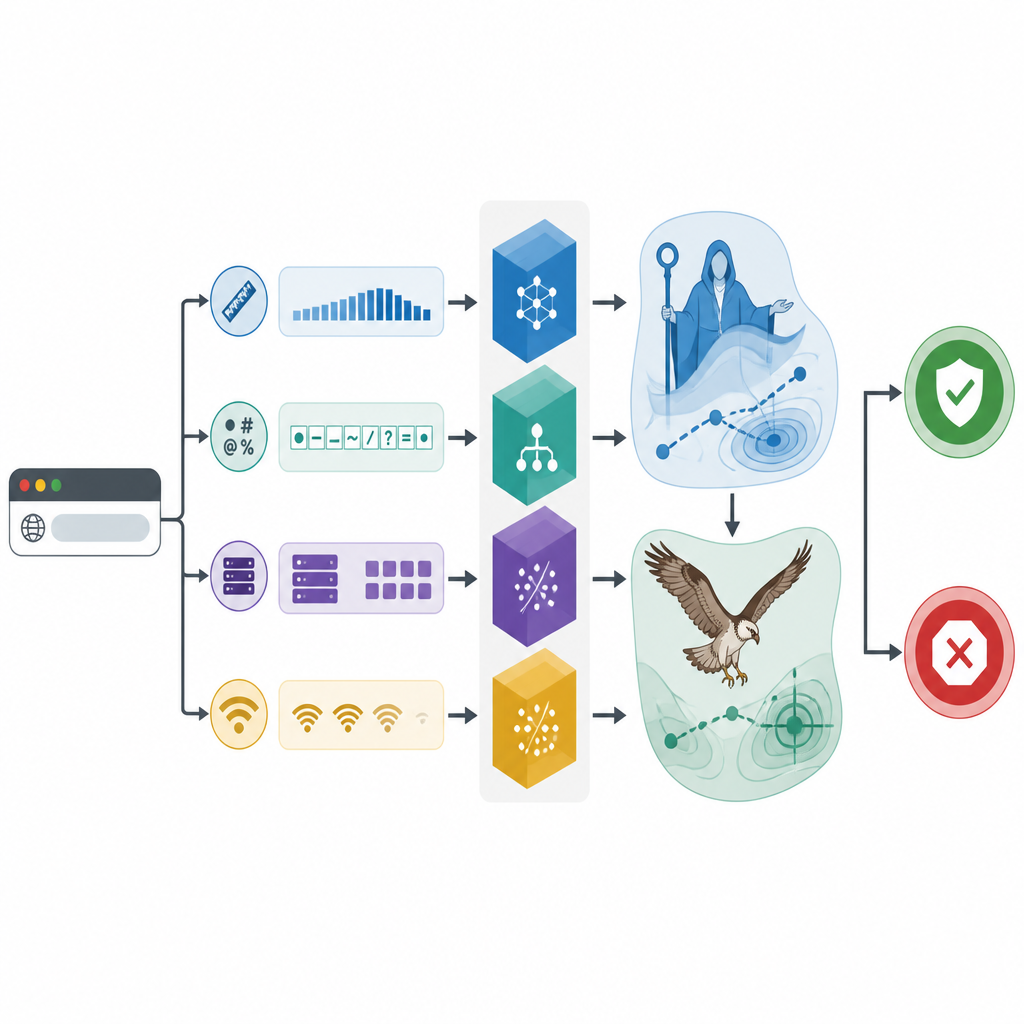
Czego modele uczą się z podpowiedzi sieci i ruchu
Zespół używa rzeczywistego zbioru danych obejmującego 1781 adresów stron internetowych, zarówno nieszkodliwych, jak i złośliwych, z których każdy opisany jest szczegółami zaczerpniętymi z rejestrów domen, odpowiedzi serwerów i aktywności sieciowej. Najpierw badacze sprawdzają, które informacje rzeczywiście pomagają odróżnić dobre od złych stron. Testy statystyczne pokazują, że kilka prostych cech wyróżnia się: ile specjalnych symboli pojawia się w linku, jak długi jest URL, jakie ustawienie kodowania tekstu występuje, jak często trzeba wyszukiwać adres strony oraz ile zdalnych maszyn jest kontaktowanych. Koncentrując się na tych kluczowych wskazówkach, rama unika gubienia się w szumie i ułatwia interpretację swoich decyzji.
Poszukiwania inspirowane naturą ostrzą narzędzia
Rdzeń badania polega na zastosowaniu bioinspirowanych algorytmów poszukiwań do dopracowania trzech klasyfikatorów. Jeden optymalizator imituje etapy edukacji, porady i wychowania, zachęcając cyfrową „familę” kandydatów do szerokiego eksplorowania, a następnie dopracowywania najlepszych opcji. Drugi naśladuje sposób, w jaki rybołów (osprey) wypatruje i unosi zdobycz, najpierw skanując szeroko, a potem koncentrując się wokół obiecujących obszarów. Razem te metody dostosowują ustawienia wewnętrzne, takie jak złożoność drzew decyzyjnych czy stopień wygładzania granic między klasami. Eksperymenty z powtarzanym sprawdzaniem krzyżowym pokazują, że każdy klasyfikator zyskuje na tym strojeniu, ale zoptymalizowany model CatBoost, nazwany CAMA, wypada najlepiej.
Mocniejsze wyniki i jaśniejsze wnioski
We wszystkich testach modele hybrydowe przewyższają prostsze wersje pod względem dokładności, precyzji, czułości i powiązanych miar równoważących pominięte zagrożenia z fałszywymi alarmami. Najlepszy model klasyfikuje poprawnie około 96 procent stron, jednocześnie utrzymując niską liczbę błędnie blokowanych bezpiecznych witryn. Aby zapobiec przekształceniu systemu w tajemniczą czarną skrzynkę, autorzy stosują metodę przypisującą każdej predykcji zestaw „kredytów” pokazujących, jak bardzo każda cecha przesunęła decyzję w stronę bezpieczne lub niebezpieczne. Pokazuje to, na przykład, że wysoka liczba dziwnych symboli i nietypowe zachowania przy wyszukiwaniu adresu są silnymi ostrzeżeniami o zagrożeniu.
Co to oznacza dla codziennego bezpieczeństwa w sieci
Dla osób niebędących specjalistami przekaz jest taki, że garść dobrze dobranych wskazówek o adresach internetowych i ich ruchu, analizowanych przez kilka współpracujących modeli i dostrojonych pomysłami zapożyczonymi z natury, może z dużą niezawodnością wykrywać niebezpieczne witryny. Choć badanie wykorzystuje umiarkowane rozmiary zbioru danych i wymaga jeszcze testów na większych, zmieniających się strumieniach ruchu online, pokazuje, że łączenie różnorodności, starannego poszukiwania i przejrzystych wyjaśnień może uczynić zautomatyzowane obrony jednocześnie skuteczniejszymi i bardziej godnymi zaufania.
Cytowanie: Liu, H. A scalable hybrid computational intelligence framework with bio inspired optimization for high dimensional malicious URL inference. Sci Rep 16, 14842 (2026). https://doi.org/10.1038/s41598-026-44851-4
Słowa kluczowe: wykrywanie złośliwych URL-i, cyberbezpieczeństwo, uczenie maszynowe, bioinspirowana optymalizacja, analiza ruchu sieciowego