Clear Sky Science · en
A scalable hybrid computational intelligence framework with bio inspired optimization for high dimensional malicious URL inference
Why spotting bad links matters
The links we click every day can quietly open the door to scams, data theft, and computer infections. Cybercriminals constantly invent new tricks, so simple blocklists and rule-based filters often miss fresh attacks. This study explores a smarter way to tell safe websites from harmful ones by combining several kinds of mathematical models with search strategies inspired by nature, aiming to keep detection both accurate and understandable for security teams.
From simple rules to smarter defenses
Traditional defenses against bad websites rely on checking whether a link appears on a blacklist or matches known patterns in its text or page content. These methods can stop some threats, but they easily fail when attackers disguise addresses, change them often, or mimic trusted sites. The paper argues that the fast-changing nature of online crime calls for flexible tools that can learn from data, test how reliable their decisions are, and reveal which details of a web address or its traffic are most telling.
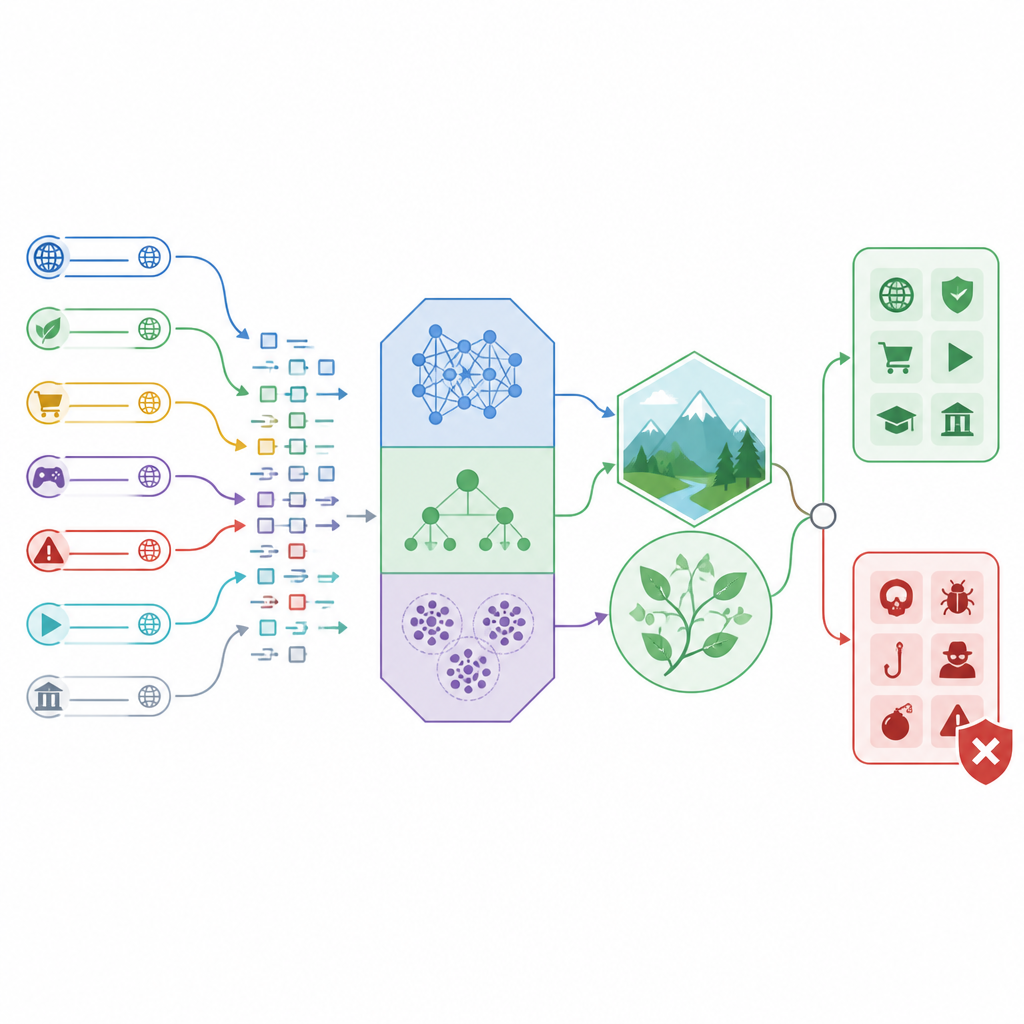
How the new detection framework works
The researchers build a “hybrid” detection framework that blends three different classifiers with nature inspired tuning methods. Two of the classifiers, called linear and quadratic discriminant analysis, are good at drawing clear boundaries between safe and unsafe traffic using simple mathematical shapes. The third, named CatBoost, is a powerful tree based method that can handle mixed types of information, such as numbers describing how long a URL is, how many unusual characters it contains, or how its network traffic behaves. Instead of trusting default settings, the study uses two search strategies modeled on a caring mother and a hunting bird to explore many possible parameter settings and keep those that work best.
What the models learn from web and network clues
The team uses a real world dataset of 1,781 website addresses, including both harmless and malicious ones, each described by details drawn from registration records, server responses, and network activity. They first examine which pieces of information truly help separate good from bad sites. Statistical tests show that a few simple traits stand out: how many special symbols appear in a link, how long the URL is, how the text encoding is set, how often the site’s address has to be looked up, and how many remote machines are contacted. By focusing on these key clues, the framework avoids getting lost in noise and makes its decisions easier to interpret.
Nature inspired search sharpens the tools
The heart of the study lies in using bio inspired search algorithms to fine tune the three classifiers. One optimizer imitates stages of education, advice, and upbringing, encouraging a digital “family” of candidate solutions to explore widely and then refine the best options. The other copies the way an osprey spots and carries prey, first scanning broadly and then concentrating around promising regions. Together, these methods adjust internal settings like how complex the decision trees should be or how strongly to smooth the boundaries between classes. Experiments with repeated cross checking show that every classifier benefits from this tuning, but the optimized CatBoost model, called CAMA, performs best.
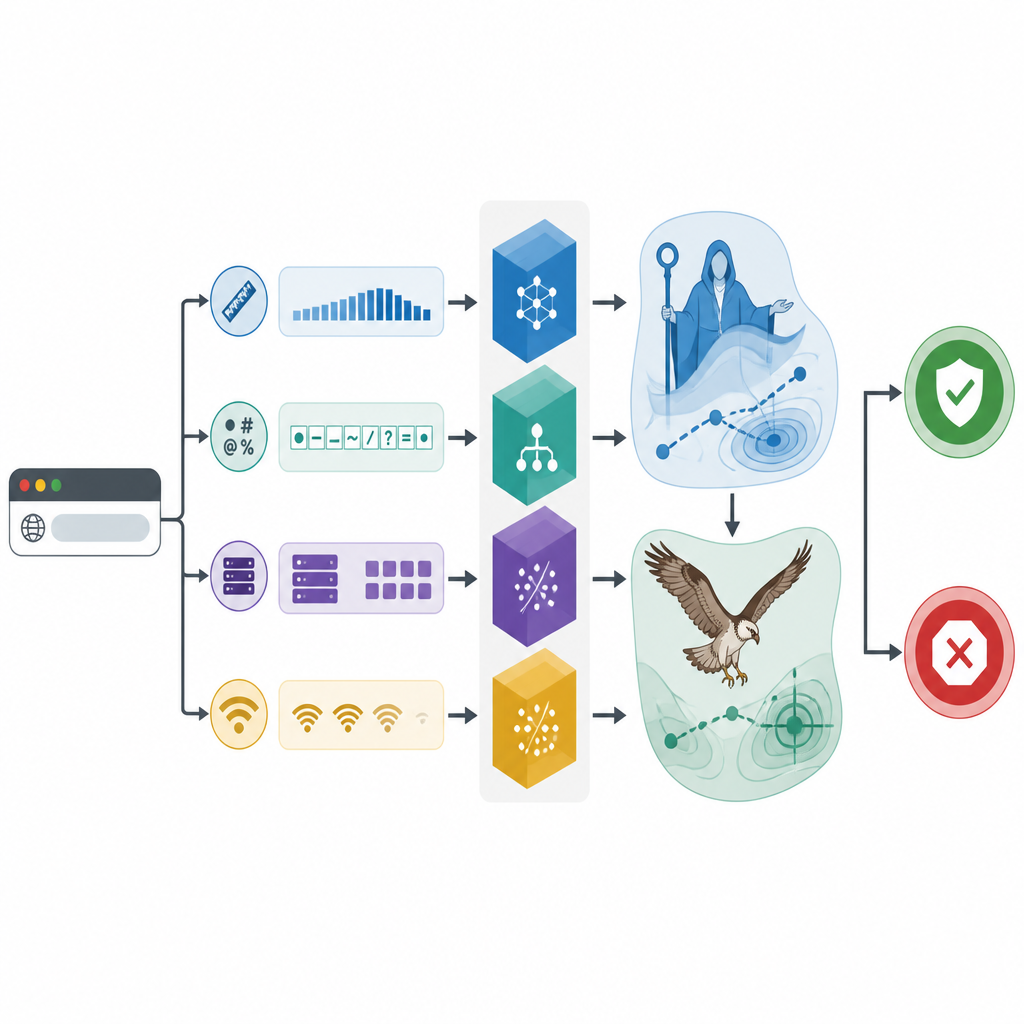
Stronger results and clearer insights
Across many tests, the hybrid models beat the simpler versions on accuracy, precision, recall, and related measures that balance missed threats against false alarms. The top model correctly classifies about 96 percent of websites, while also keeping the number of wrongly blocked safe sites low. To keep the system from becoming a mysterious black box, the authors apply a method that assigns each prediction a set of “credits” showing how much each feature pushed the decision toward safe or unsafe. This reveals, for example, that a high count of strange symbols and unusual address lookup behavior are strong warnings of danger.
What this means for everyday web safety
For non specialists, the message is that a handful of well chosen clues about web addresses and their traffic, examined by several cooperating models and tuned with ideas borrowed from nature, can flag dangerous sites with high reliability. While the study uses a modest sized dataset and still needs testing on larger, shifting streams of online traffic, it shows that combining diversity, careful search, and clear explanations can make automated defenses both sharper and more trustworthy.
Citation: Liu, H. A scalable hybrid computational intelligence framework with bio inspired optimization for high dimensional malicious URL inference. Sci Rep 16, 14842 (2026). https://doi.org/10.1038/s41598-026-44851-4
Keywords: malicious URL detection, cybersecurity, machine learning, bio inspired optimization, web traffic analysis