Clear Sky Science · de
Ein skalierbares hybrides Rechenintelligenz‑Framework mit bioinspirierter Optimierung zur Inferenz hochdimensionaler bösartiger URLs
Warum das Erkennen schlechter Links wichtig ist
Die Links, auf die wir täglich klicken, können unbemerkt Türen für Betrug, Datendiebstahl und Computerinfektionen öffnen. Cyberkriminelle erfinden ständig neue Tricks, sodass einfache Sperrlisten und regelbasierte Filter frisch auftauchende Angriffe oft übersehen. Diese Studie untersucht eine intelligentere Methode, um sichere Websites von schädlichen zu unterscheiden, indem mehrere Arten mathematischer Modelle mit suchbasierten Strategien kombiniert werden, die von der Natur inspiriert sind, mit dem Ziel, Erkennung sowohl genau als auch für Sicherheitsteams verständlich zu halten.
Von einfachen Regeln zu klügeren Abwehrmaßnahmen
Traditionelle Abwehrmechanismen gegen schädliche Websites beruhen darauf, ob ein Link auf einer schwarzen Liste steht oder bekannten Mustern im Text oder Seiteninhalt entspricht. Diese Methoden können einige Bedrohungen verhindern, versagen jedoch leicht, wenn Angreifer Adressen verschleiern, häufig ändern oder vertrauenswürdige Seiten imitieren. Das Papier argumentiert, dass die sich schnell verändernde Natur von Online‑Kriminalität flexible Werkzeuge erfordert, die aus Daten lernen, die Zuverlässigkeit ihrer Entscheidungen testen und zeigen können, welche Details einer Webadresse oder ihres Verkehrs am aufschlussreichsten sind.
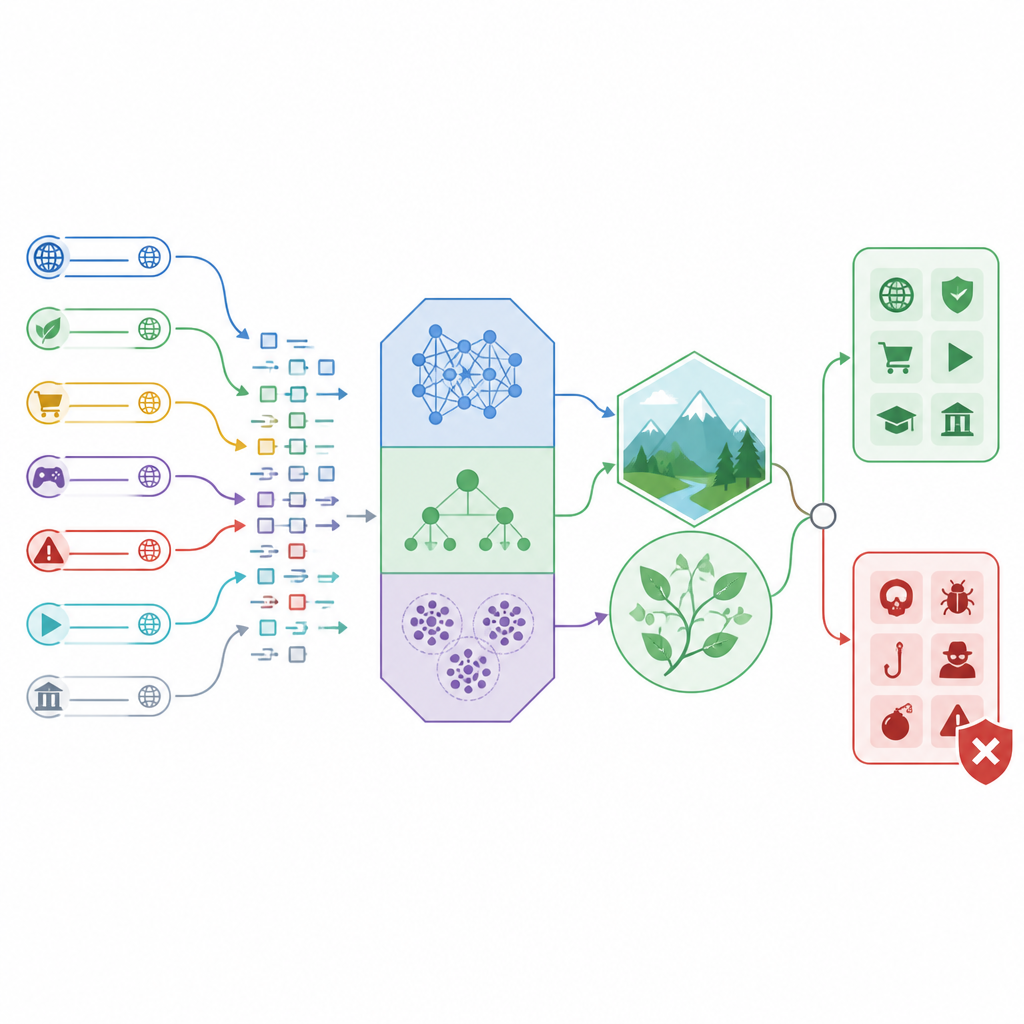
Wie das neue Erkennungs‑Framework funktioniert
Die Forscher entwickeln ein „hybrides“ Erkennungs‑Framework, das drei verschiedene Klassifizierer mit naturinspirierten Abstimmungsmethoden verbindet. Zwei der Klassifizierer, lineare und quadratische diskriminante Analyse, sind gut darin, klare Grenzen zwischen sicherem und unsicherem Verkehr mittels einfacher mathematischer Formen zu ziehen. Der dritte, CatBoost genannt, ist eine leistungsfähige baumbasierte Methode, die gemischte Informationsarten verarbeiten kann, etwa Zahlen zur URL‑Länge, Anzahl ungewöhnlicher Zeichen oder zum Verhalten des Netzwerkverkehrs. Anstatt den Standardeinstellungen zu vertrauen, nutzt die Studie zwei Suchstrategien, die auf einer fürsorglichen Mutter und einem jagenden Vogel basieren, um viele mögliche Parameterkonfigurationen zu erkunden und die am besten funktionierenden beizubehalten.
Was die Modelle aus Web‑ und Netzwerkhinweisen lernen
Das Team verwendet einen realen Datensatz mit 1.781 Website‑Adressen, darunter harmlose und bösartige, jeweils beschrieben durch Angaben aus Registrierungsdaten, Serverantworten und Netzwerkaktivität. Zuerst untersuchen sie, welche Informationen tatsächlich helfen, gute von schlechten Seiten zu trennen. Statistische Tests zeigen, dass einige wenige einfache Merkmale hervorstechen: wie viele Sonderzeichen in einem Link vorkommen, die Länge der URL, wie die Textkodierung gesetzt ist, wie oft die Adresse nachgeschlagen werden muss und wie viele entfernte Maschinen kontaktiert werden. Durch die Konzentration auf diese Schlüsselhinweise vermeidet das Framework, sich in Rauschen zu verlieren, und macht seine Entscheidungen leichter interpretierbar.
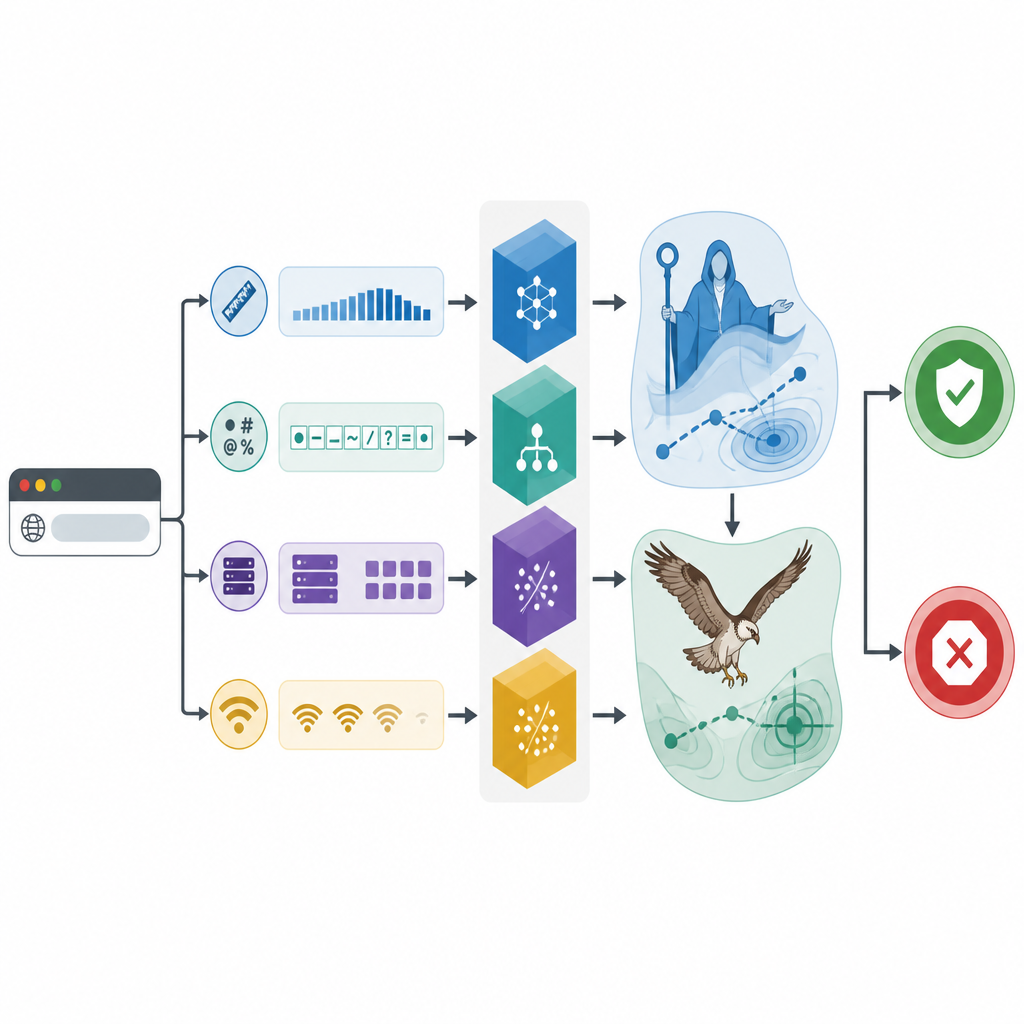
Bioinspirierte Suche schärft die Werkzeuge
Der Kern der Studie besteht in der Anwendung bioinspirierter Suchalgorithmen zur Feinabstimmung der drei Klassifizierer. Ein Optimierer ahmt Phasen von Bildung, Rat und Erziehung nach und ermutigt eine digitale „Familie“ von Kandidatenlösungen, zunächst weit zu erkunden und dann die besten Optionen zu verfeinern. Der andere kopiert die Art und Weise, wie ein Fischadler Beute erspäht und trägt: zunächst breit scannend, dann konzentriert um vielversprechende Regionen. Gemeinsam passen diese Methoden interne Einstellungen an, etwa wie komplex Entscheidungsbäume sein sollten oder wie stark die Grenzen zwischen Klassen geglättet werden. Experimente mit wiederholter Kreuzvalidierung zeigen, dass jeder Klassifizierer von dieser Abstimmung profitiert, wobei das optimierte CatBoost‑Modell, genannt CAMA, am besten abschneidet.
Stärkere Ergebnisse und klarere Einsichten
In zahlreichen Tests übertreffen die hybriden Modelle die einfacheren Versionen bei Genauigkeit, Präzision, Trefferquote und verwandten Maßen, die verpasste Bedrohungen gegen Fehlalarme abwägen. Das Spitzmodell klassifiziert etwa 96 Prozent der Websites korrekt, während gleichzeitig die Zahl fälschlich blockierter sicherer Seiten gering bleibt. Um zu verhindern, dass das System zu einer rätselhaften Black Box wird, wenden die Autoren eine Methode an, die jeder Vorhersage eine Reihe von „Gutschriften“ zuweist, die zeigen, wie stark jedes Merkmal die Entscheidung in Richtung sicher oder unsicher beeinflusst hat. Das zeigt beispielsweise, dass eine hohe Anzahl seltsamer Symbole und ungewöhnliches Adress‑Lookup‑Verhalten starke Warnzeichen sind.
Was das für die alltägliche Web‑Sicherheit bedeutet
Für Nicht‑Spezialisten lautet die Botschaft, dass eine Handvoll gut gewählter Hinweise zu Webadressen und deren Verkehr, untersucht von mehreren kooperierenden Modellen und mit Ideen aus der Natur abgestimmt, gefährliche Seiten mit hoher Zuverlässigkeit kennzeichnen kann. Obwohl die Studie einen moderat großen Datensatz verwendet und noch Tests auf größeren, sich verschiebenden Strömen von Online‑Verkehr benötigt, zeigt sie, dass die Kombination aus Vielfalt, sorgfältiger Suche und klaren Erklärungen automatisierte Abwehrmaßnahmen sowohl schärfer als auch vertrauenswürdiger machen kann.
Zitation: Liu, H. A scalable hybrid computational intelligence framework with bio inspired optimization for high dimensional malicious URL inference. Sci Rep 16, 14842 (2026). https://doi.org/10.1038/s41598-026-44851-4
Schlüsselwörter: Erkennung bösartiger URLs, Cybersicherheit, Maschinelles Lernen, bioinspirierte Optimierung, Analyse von Webverkehr