Clear Sky Science · sv
Validering av konform prediktion vid klassificering av cervikal atypi
Varför smartare screening för livmoderhalscancer är viktig
Livmoderhalscancer dödar fortfarande hundratusentals kvinnor varje år, särskilt i länder där läkare och laboratoriespecialister är få. Artificiell intelligens (AI) som granskar cellprover från livmoderhalsen under mikroskopet kan hjälpa till att täppa till detta gap, men dagens system uttrycker sig ofta med för stor säkerhet. De ger vanligtvis en enda "bästa gissning"-etikett, även när bilden verkligen är svår att klassificera. Denna studie ställer en enkel men avgörande fråga: när en AI säger att den är osäker, stämmer den osäkerheten överens med vad mänskliga experter tycker?
Från enkla svar till kortlistor av möjligheter
De flesta medicinska AI-verktyg för Pap-smearbilder speglar hur vanliga laboratorierapporter skrivs: de väljer en kategori såsom "normal", "lågradsförändringar" eller "högradsförändringar" och fäster en sannolikhet. Men dessa sannolikhetspoäng kan vara missvisande skarpa. Metoden som undersöks i denna artikel, kallad konform prediktion, väljer en annan väg. Istället för ett slutligt svar producerar den en liten uppsättning rimliga etiketter för varje bildruta från ett preparat. Ett mycket säkert fall kan få en enda etikett, medan ett knepigt fall kan få flera. I princip bör detta ge kliniker en ärligare bild av vad modellen vet och inte vet. 
Bygga en nyanserad bild av experternas oenighet
För att testa hur väl idén fungerar i verkligheten samlade forskarna en detaljerad datamängd från mer än 300 Pap-preparat insamlade på ett landsbygdsjukhus i Kenya. Ett befintligt AI-system markerade först regioner som sannolikt innehöll avvikande celler, och dessa regioner beskars till små rutor. Sex erfarna cytologiexperter använde sedan en specialbyggd webbplattform för att märka tusentals av dessa rutor. För en kärntestuppsättning märkte fyra experter varje ruta oberoende av varandra. Detta skapade inte bara en enda "sanningssiffra" per ruta, utan ett fullständigt mönster av överenskommelse och oenighet mellan experterna, vilket fångade vilka bilder som var entydiga och vilka som var naturligt tvetydiga.
Test av olika sätt att uttrycka osäkerhet
Teamet tränade tre populära djupinlärningsmodeller för att känna igen fyra kategorier: normal, lågradsförändringar, högradsförändringar och artefakter. Ovanpå varje modell tillämpade de tre varianter av konform prediktion som skiljer sig åt i hur breda deras etikettuppsättningar tenderar att vara. De utvärderade sedan prestanda på två kompletterande sätt. Först använde de standardmått av täcknings-typ som enkelt frågar: innehåller den uppsättning förutspådda etiketter åtminstone konsensusetiketten från experterna en vald procent av gångerna? För det andra införde de överensstämmelsemått som jämför varje förutsägelseuppsättning med hela listan av etiketter som givits av alla experter för den rutan, och belönar fall där AIs kortlista matchar experternas eget spektrum av åsikter.
När standardmått målar upp en för rosig bild
Enligt konventionella täckningsmått såg de konforma metoderna imponerande ut: de inkluderade nästan alltid experternas konsensusetikett, särskilt när de tilläts leverera något större uppsättningar. Men de striktare överensstämmelsetesterna berättade en annan historia. Exakta matchningar mellan AIs etikettuppsättningar och experternas kombinerade etiketter var bara kring en tredjedel av fallen, oavsett metod. Vissa angreppssätt föredrog små, precisa uppsättningar som missade etiketter experter ansåg tänkbara, medan andra producerade större uppsättningar som svepte in osannolika etiketter tillsammans med den korrekta. Metoderna presterade dock väl när det gällde att följa inbyggd tvetydighet: när mänskliga experter var mer oeniga tenderade de konforma uppsättningarna att öka i storlek. Däremot var de mycket mindre tillförlitliga när det gällde att flagga bilder som verkligen inte hörde till träningsdistributionen, såsom kraftigt brusiga Pap-bilder eller benmärgsceller från en annan vävnadstyp, och detta beteende berodde starkt på vilken underliggande modell som användes. 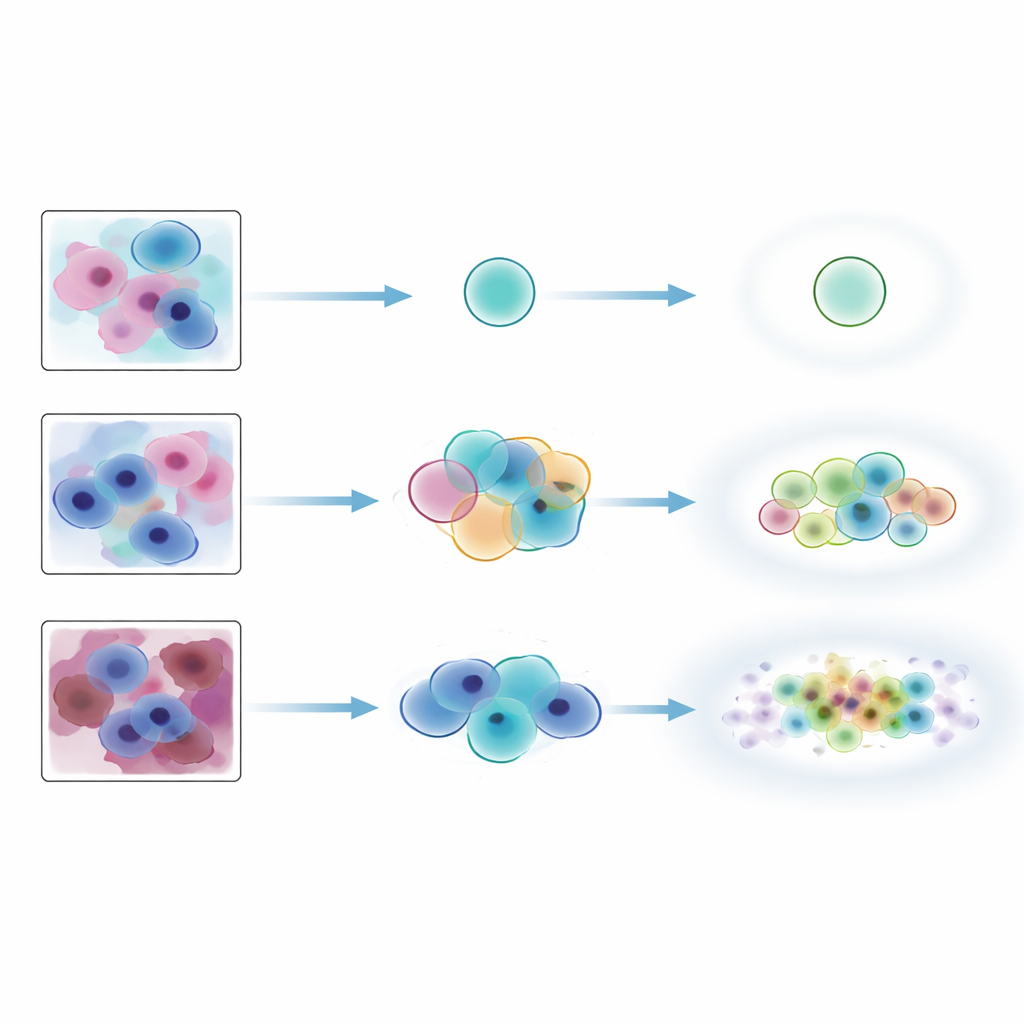
Vad detta betyder för användning i verkligheten
För kliniker som överväger AI-verktyg som stöd är huvudslutsatsen att osäkerhetsuppskattningar inte automatiskt är pålitliga bara för att de åtföljs av matematiska garantier. Konform prediktion kan säkerställa att den verkliga etiketten mycket ofta finns någonstans i den förutsagda uppsättningen, men denna studie visar att de extra etiketterna i den uppsättningen kanske inte överensstämmer med mänskliga förväntningar och till och med kan distrahera från de mest relevanta möjligheterna. Författarna hävdar att inom områden där insatserna är höga, såsom cancerscreening, måste AI-utdata bedömas inte bara utifrån om de är tekniskt "korrekta", utan också utifrån om de presenterar information på ett fokuserat och kliniskt meningsfullt sätt. Framtida arbete behöver förfina både modeller och osäkerhetsverktyg så att deras kortlistor över diagnoser känns lika rimliga för experter som de är tillfredsställande för ekvationer.
Citering: Hagos, M.T., Suutala, A., Bychkov, D. et al. Validation of conformal prediction in cervical atypia classification. Sci Rep 16, 9649 (2026). https://doi.org/10.1038/s41598-026-44850-5
Nyckelord: screening för livmoderhalscancer, osäkerhet i medicinsk AI, konform prediktion, digital cytologi, detektion av out-of-distribution