Clear Sky Science · pt
Validação da predição conformal na classificação de atipias cervicais
Por que um rastreio mais inteligente do câncer cervical é importante
O câncer cervical ainda mata centenas de milhares de mulheres todo ano, especialmente em países onde faltam médicos e especialistas de laboratório. Sistemas de inteligência artificial (IA) que examinam amostras de células cervicais ao microscópio poderiam ajudar a suprir essa lacuna, mas os sistemas atuais frequentemente falam com confiança excessiva. Eles geralmente fornecem um único rótulo de “melhor palpite”, mesmo quando a imagem é realmente difícil de classificar. Este estudo faz uma pergunta simples, porém crucial: quando uma IA diz estar insegura, essa incerteza realmente se alinha com o que os especialistas humanos pensam?
De respostas únicas a listas curtas de possibilidades
A maioria das ferramentas médicas de IA para imagens de Papanicolau espelha como os laudos laboratoriais padrão são escritos: escolhem uma categoria como “normal”, “alterações de baixo grau” ou “alterações de alto grau” e associam uma probabilidade. Mas essas pontuações de probabilidade podem transmitir uma certeza enganosa. O método explorado neste artigo, chamado predição conformal, segue um caminho diferente. Em vez de uma resposta final, ele produz um pequeno conjunto de rótulos plausíveis para cada fragmento de imagem (tile) de uma lâmina. Um caso muito confiante pode receber um único rótulo, enquanto um caso complexo pode receber vários. Em princípio, isso deve dar aos clínicos uma visão mais honesta do que o modelo sabe e do que não sabe. 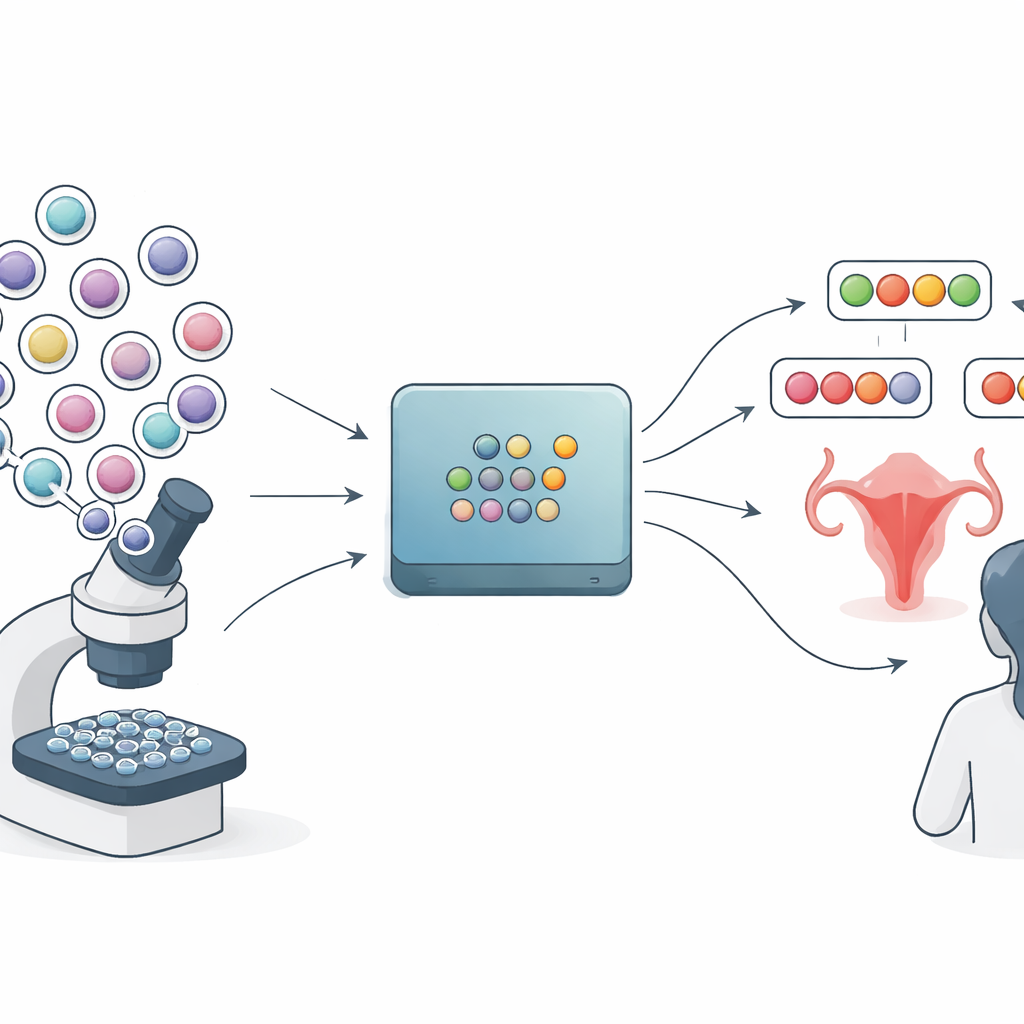
Construindo um retrato detalhado do desacordo entre especialistas
Para testar quão bem essa ideia funciona no mundo real, os pesquisadores reuniram um conjunto de dados detalhado com mais de 300 lâminas de Papanicolau coletadas em um hospital rural no Quênia. Um sistema de IA existente primeiro destacou regiões com provável presença de células anormais, e essas regiões foram recortadas em pequenos tiles. Seis especialistas experientes em citologia então utilizaram uma plataforma web personalizada para rotular milhares desses tiles. Para um conjunto de teste central, quatro especialistas rotularam independentemente os mesmos tiles. Isso gerou não apenas uma única “verdade de referência” por tile, mas um padrão completo de acordo e desacordo entre especialistas, capturando quais imagens eram claras e quais eram naturalmente ambíguas.
Testando diferentes formas de expressar incerteza
A equipe treinou três modelos de deep learning populares para reconhecer quatro categorias: normal, alterações de baixo grau, alterações de alto grau e artefatos. Sobre cada modelo, aplicaram três variantes de predição conformal que diferem em quão amplos tendem a ser seus conjuntos de rótulos. Em seguida, avaliaram o desempenho de duas maneiras complementares. Primeiro, usaram medidas tradicionais de cobertura que simplesmente perguntam: o conjunto de rótulos previsto inclui o rótulo consensual dos especialistas pelo menos uma porcentagem escolhida do tempo? Segundo, introduziram medidas de acordo que comparam cada conjunto de predição à lista completa de rótulos dada por todos os especialistas para aquele tile, recompensando os casos em que a lista curta da IA corresponde à própria gama de opiniões dos especialistas.
Quando métricas padrão pintam um quadro excessivamente otimista
Pelas medidas convencionais de cobertura, os métodos conformais pareceram impressionantes: quase sempre incluíam o rótulo consensual dos especialistas, especialmente quando podiam emitir conjuntos ligeiramente maiores. Mas os testes mais estritos de acordo contaram outra história. Correspondências exatas entre os conjuntos de rótulos da IA e os rótulos combinados dos especialistas ocorreram em apenas cerca de um terço dos casos, independentemente do método. Algumas abordagens favoreceram conjuntos pequenos e precisos que deixavam de fora rótulos que os especialistas consideravam plausíveis, enquanto outras produziram conjuntos maiores que adicionavam rótulos improváveis junto com o correto. Os métodos se saíram bem ao acompanhar a ambiguidade intrínseca: quando os especialistas humanos discordavam mais, os conjuntos conformais tendiam a aumentar de tamanho. No entanto, mostraram-se muito menos confiáveis ao sinalizar imagens que realmente não pertenciam à distribuição de treinamento, como Papanicolaus com muito ruído ou amostras de medula óssea de outro tipo de tecido, e esse comportamento dependia fortemente de qual modelo subjacente foi usado. 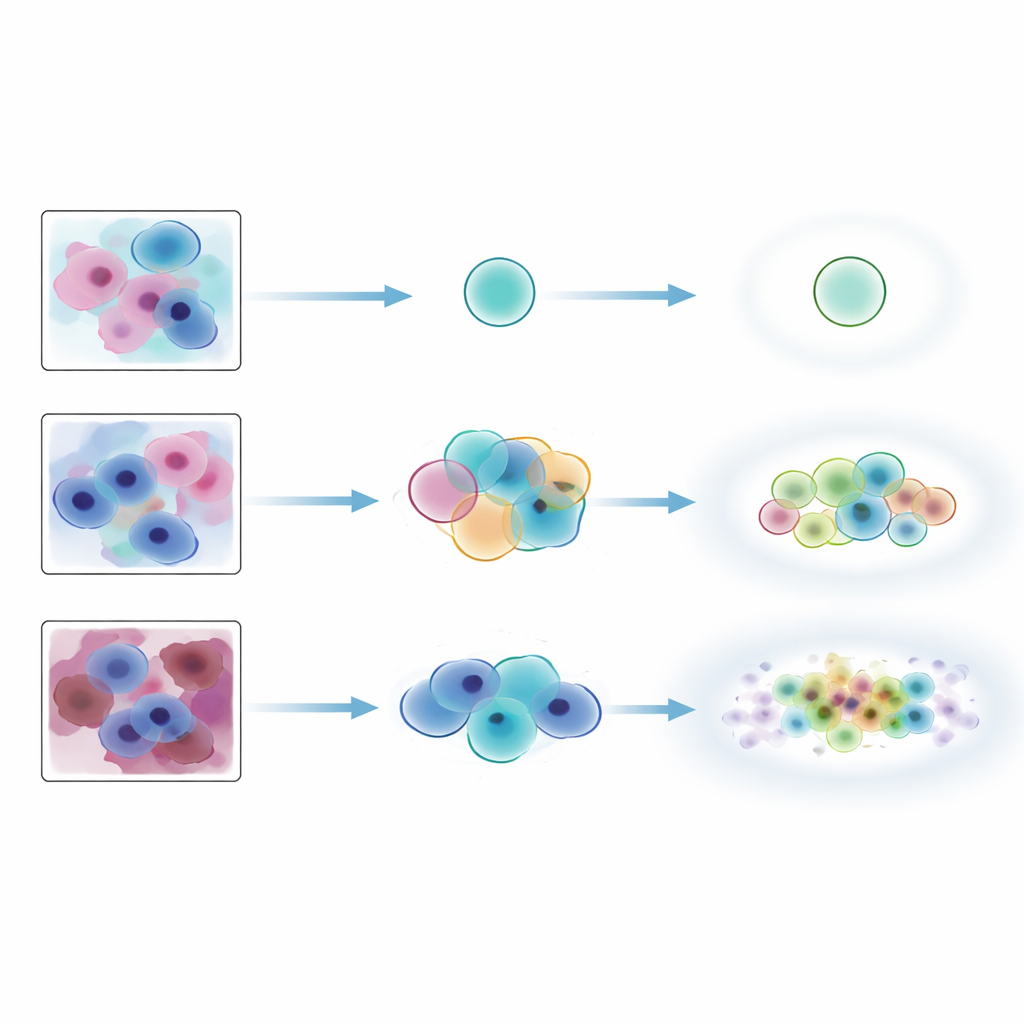
O que isso significa para o uso no mundo real
Para clínicos que consideram ferramentas de suporte com IA, a conclusão principal é que estimativas de incerteza não são automaticamente confiáveis só porque vêm com garantias matemáticas. A predição conformal pode assegurar que o rótulo verdadeiro esteja muito frequentemente em algum lugar do conjunto previsto, mas este estudo mostra que os rótulos extras nesse conjunto podem não corresponder às expectativas humanas e podem até distrair das possibilidades mais relevantes. Os autores argumentam que, em áreas de alto risco como o rastreio do câncer, as saídas de IA devem ser julgadas não apenas por serem tecnicamente “corretas”, mas também por apresentarem informação de maneira focada e clinicamente significativa. Trabalhos futuros precisarão refinar tanto os modelos quanto as ferramentas de incerteza para que suas listas curtas de diagnósticos façam tanto sentido para os especialistas quanto satisfazem as equações.
Citação: Hagos, M.T., Suutala, A., Bychkov, D. et al. Validation of conformal prediction in cervical atypia classification. Sci Rep 16, 9649 (2026). https://doi.org/10.1038/s41598-026-44850-5
Palavras-chave: rastreio do câncer cervical, incerteza em IA médica, predição conformal, citologia digital, detecção fora da distribuição