Clear Sky Science · nl
Validatie van conformele voorspelling bij classificatie van cervicale atypie
Waarom slimmer screenen op baarmoederhalskanker belangrijk is
Baarmoederhalskanker eist nog steeds honderden duizenden levens per jaar, vooral in landen waar artsen en laboratoriumspecialisten schaars zijn. Kunstmatige intelligentie (AI)-systemen die cervixcellen onder de microscoop analyseren, zouden dit tekort kunnen helpen opvangen, maar de huidige systemen presenteren zich vaak met te veel zelfvertrouwen. Ze geven meestal één enkele "beste gok"-label, zelfs wanneer de afbeelding daadwerkelijk moeilijk te classificeren is. Deze studie stelt een eenvoudige maar cruciale vraag: wanneer een AI zegt dat zij onzeker is, komt die onzekerheid dan overeen met wat menselijke experts denken?
Van enkele antwoorden naar korte lijsten met mogelijkheden
De meeste medische AI-hulpmiddelen voor Pap-smearbeelden weerspiegelen hoe standaard laboratoriumrapporten worden opgesteld: ze kiezen een categorie zoals "normaal", "lage-graad veranderingen" of "hoge-graad veranderingen" en plakken er een waarschijnlijkheid aan vast. Maar deze waarschijnlijkheidsscores kunnen misleidend scherp zijn. De methode die in dit artikel wordt onderzocht, conformele voorspelling genoemd, volgt een andere benadering. In plaats van één definitief antwoord produceert ze voor elke afbeeldingsvogel van een preparaat een kleine set plausibele labels. Een zeer zeker geval krijgt mogelijk één label, terwijl een lastig geval er meerdere kan krijgen. In principe zou dit clinici een eerlijker beeld moeten geven van wat het model wel en niet weet. 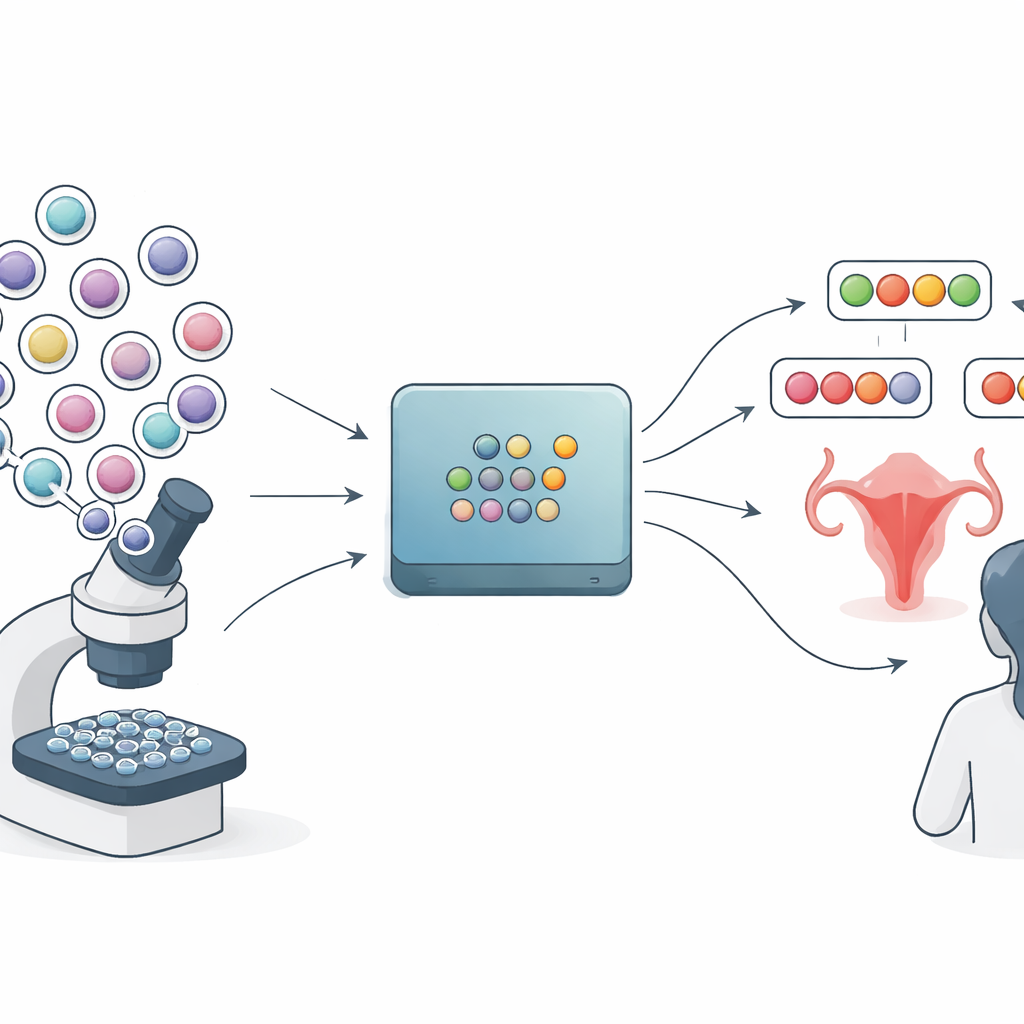
Een rijk beeld van expertsverschil opbouwen
Om te testen hoe goed dit idee in de praktijk werkt, stelden de onderzoekers een gedetailleerde dataset samen van meer dan 300 Pap-smearpreparaten verzameld in een regionaal ziekenhuis in Kenia. Een bestaand AI-systeem markeerde eerst regio’s die waarschijnlijk abnormale cellen bevatten, en deze regio’s werden uitgesneden in kleine tiles. Zes ervaren cytologie-experts gebruikten vervolgens een op maat gemaakt webplatform om duizenden van deze tiles te labelen. Voor een kern-testset labelden vier experts onafhankelijk van elkaar dezelfde tiles. Dit creëerde niet slechts één enkele "grondwaarheid" per tile, maar een volledig patroon van overeenstemming en meningsverschil tussen experts, waardoor zichtbaar werd welke beelden eenduidig waren en welke van nature ambigu.
Verschillende manieren om onzekerheid uit te drukken testen
Het team trainde drie populaire deep-learningmodellen om vier categorieën te herkennen: normaal, lage-graad veranderingen, hoge-graad veranderingen en artefacten. Bovenop elk model pasten ze drie varianten van conformele voorspelling toe die verschillen in hoe breed hun labellijsten geneigd zijn te zijn. Ze evalueerden de prestaties vervolgens op twee aanvullende manieren. Ten eerste gebruikten ze standaard coverage-achtige maten die eenvoudigweg vragen: bevat de set voorspelde labels ten minste een gekozen percentage van de tijd het consensuslabel van de experts? Ten tweede introduceerden ze agreement-achtige maten die elke voorspellingsset vergelijken met de volledige lijst labels die alle experts voor die tile hebben gegeven, en belonen gevallen waarin de AI-shortlist overeenkomt met het eigen scala aan meningen van de experts.
Wanneer standaardstatistieken een te rooskleurig beeld schetsen
Volgens conventionele coverage-maten leken de conforme methoden indrukwekkend: ze bevatten bijna altijd het consensuslabel van de experts, vooral wanneer ze iets grotere sets mochten outputten. Maar de strengere agreement-tests gaven een ander beeld. Exacte overeenkomsten tussen de AI-labellijsten en de gecombineerde labels van de experts kwamen in slechts ongeveer een derde van de gevallen voor, ongeacht de methode. Sommige benaderingen gaven de voorkeur aan kleine, precieze sets die labels misten die experts als plausibel beschouwden, terwijl andere grotere sets produceerden die onwaarschijnlijke labels meepakte naast het correcte label. De methoden presteerden wel goed in het volgen van ingebouwde ambiguïteit: wanneer menselijke experts het meer oneens waren, groeiden de conforme sets meestal in omvang. Ze waren echter veel minder betrouwbaar in het signaleren van afbeeldingen die duidelijk niet tot de trainingsverdeling behoorden, zoals zwaar verstoorde Pap-smears of beenmergcellen van een ander weefseltype, en dit gedrag hing sterk af van welk onderliggend model werd gebruikt. 
Wat dit betekent voor gebruik in de praktijk
Voor clinici die AI-hulpmiddelen overwegen, is de belangrijkste conclusie dat onzekerheidsschattingen niet automatisch betrouwbaar zijn alleen omdat ze met wiskundige garanties komen. Conformele voorspelling kan waarborgen dat het juiste label zeer vaak ergens in de voorspelde set zit, maar deze studie toont aan dat de extra labels in die set mogelijk niet overeenkomen met de verwachtingen van menselijke experts en zelfs kunnen afleiden van de meest relevante mogelijkheden. De auteurs betogen dat in risicovolle domeinen zoals kankerscreening AI-uitvoer niet alleen op technische "correctheid" beoordeeld moet worden, maar ook op de vraag of zij informatie op een gefocuste en klinisch zinvolle manier presenteert. Toekomstig werk zal zowel modellen als onzekerheidsinstrumenten moeten verfijnen zodat hun shortlists met diagnoses voor experts net zo redelijk aanvoelen als ze wiskundig bevredigend zijn.
Bronvermelding: Hagos, M.T., Suutala, A., Bychkov, D. et al. Validation of conformal prediction in cervical atypia classification. Sci Rep 16, 9649 (2026). https://doi.org/10.1038/s41598-026-44850-5
Trefwoorden: baarmoederhalskankerscreening, onzekerheid van medische AI, conforme voorspelling, digitale cytologie, detectie van out-of-distribution