Clear Sky Science · en
Validation of conformal prediction in cervical atypia classification
Why smarter screening for cervical cancer matters
Cervical cancer still kills hundreds of thousands of women every year, especially in countries where doctors and laboratory specialists are scarce. Artificial intelligence (AI) systems that examine cervical cell samples under the microscope could help fill this gap, but today’s systems often speak with too much confidence. They usually give a single “best guess” label, even when the image is genuinely hard to classify. This study asks a simple but crucial question: when an AI says it is unsure, does that uncertainty actually line up with what human experts think?
From single answers to shortlists of possibilities
Most medical AI tools for Pap smear images mirror how standard lab reports are written: they pick one category such as “normal,” “low-grade changes,” or “high-grade changes” and attach a probability. But these probability scores can be misleadingly sharp. The method explored in this paper, called conformal prediction, takes a different route. Instead of one final answer, it produces a small set of plausible labels for each image tile from a slide. A very confident case might get a single label, while a tricky case might get several. In principle, this should give clinicians a more honest view of what the model does and does not know. 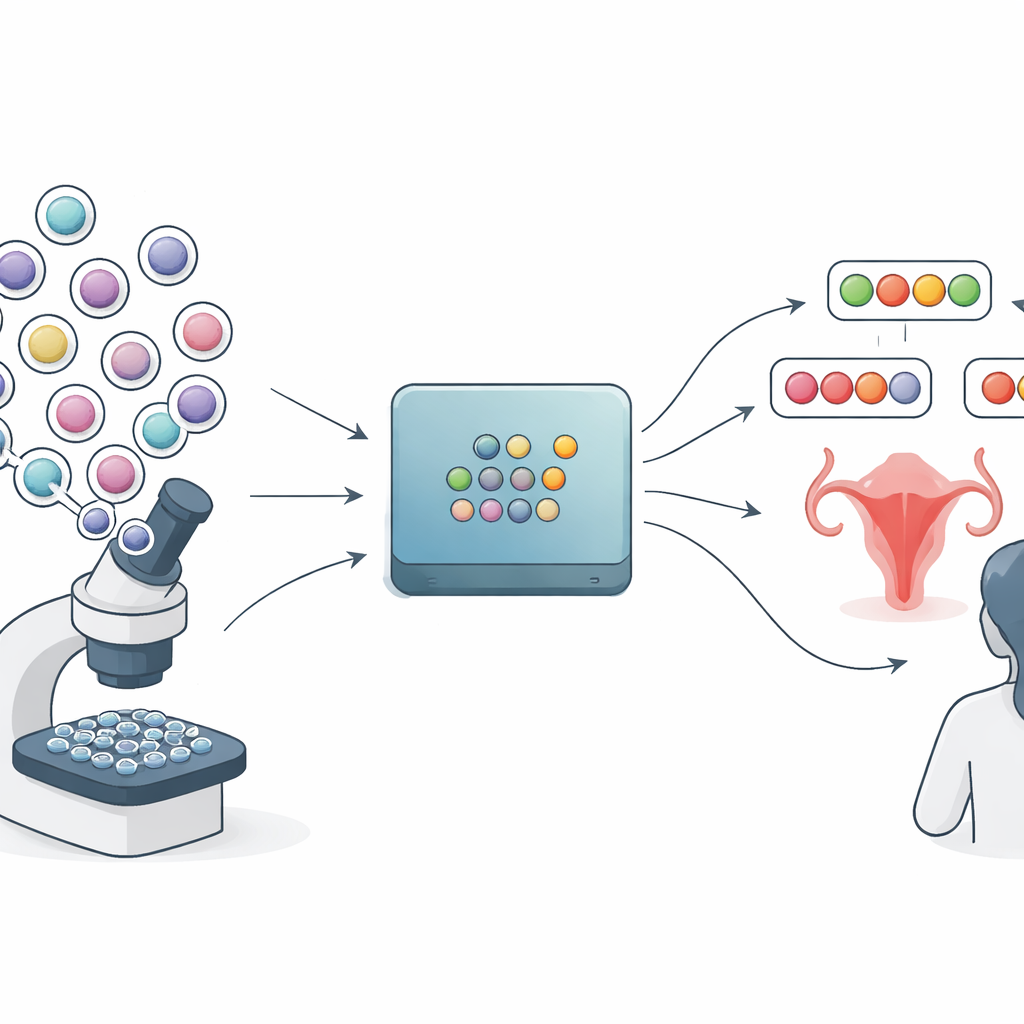
Building a rich picture of expert disagreement
To test how well this idea works in the real world, the researchers assembled a detailed dataset from more than 300 Pap smear slides collected at a rural hospital in Kenya. An existing AI system first highlighted regions likely to contain abnormal cells, and these regions were cropped into small tiles. Six experienced cytology experts then used a custom web platform to label thousands of these tiles. For a core test set, four experts each labeled the same tiles independently. This created not just a single “ground truth” per tile, but a full pattern of agreement and disagreement across experts, capturing which images were clear-cut and which were naturally ambiguous.
Testing different ways to express uncertainty
The team trained three popular deep learning models to recognize four categories: normal, low-grade changes, high-grade changes, and artifacts. On top of each model, they applied three flavors of conformal prediction that differ in how wide their label sets tend to be. They then evaluated performance in two complementary ways. First, they used standard coverage-style measures that simply ask: does the set of predicted labels include the consensus expert label at least a chosen percentage of the time? Second, they introduced agreement-style measures that compare each prediction set to the full list of labels given by all experts for that tile, rewarding cases where the AI’s shortlist matches the experts’ own range of opinions.
When standard metrics paint too rosy a picture
By conventional coverage measures, the conformal methods looked impressive: they almost always included the consensus expert label, especially when allowed to output slightly larger sets. But the stricter agreement tests told a different story. Exact matches between the AI’s label sets and the experts’ combined labels were only about one-third of cases, regardless of method. Some approaches favored small, precise sets that missed labels experts considered plausible, while others produced larger sets that swept in unlikely labels alongside the correct one. The methods did perform well at tracking built-in ambiguity: when human experts disagreed more, the conformal sets tended to grow in size. However, they were much less reliable at flagging images that truly did not belong to the training distribution, such as heavily noised Pap smears or bone marrow cells from a different tissue type, and this behavior depended strongly on which underlying model was used. 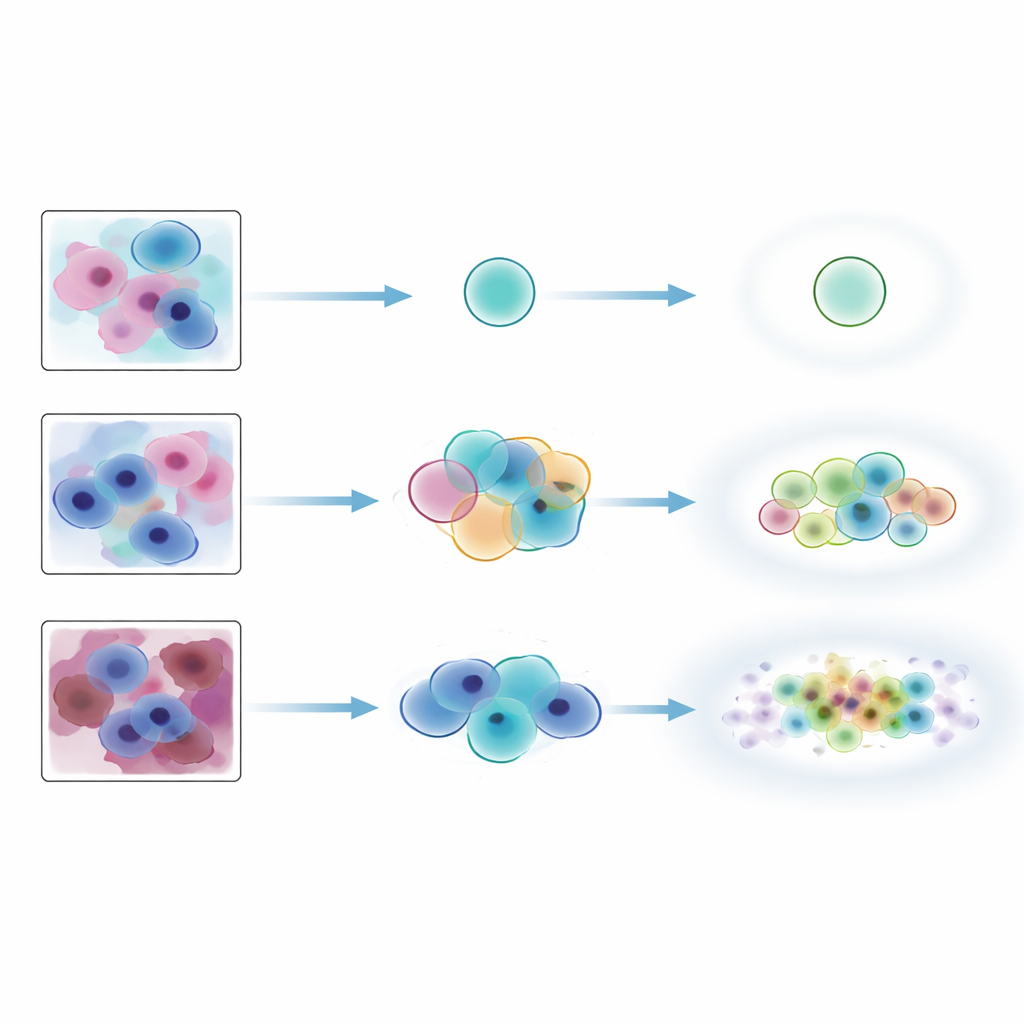
What this means for real-world use
For clinicians considering AI support tools, the main takeaway is that uncertainty estimates are not automatically trustworthy just because they come with mathematical guarantees. Conformal prediction can ensure that the true label is very often somewhere in the predicted set, but this study shows that the extra labels in that set may not match human expectations and may even distract from the most relevant possibilities. The authors argue that in high-stakes areas like cancer screening, AI outputs must be judged not only on whether they are technically “correct,” but also on whether they present information in a focused and clinically meaningful way. Future work will need to refine both models and uncertainty tools so that their shortlists of diagnoses feel as sensible to experts as they do satisfactory to equations.
Citation: Hagos, M.T., Suutala, A., Bychkov, D. et al. Validation of conformal prediction in cervical atypia classification. Sci Rep 16, 9649 (2026). https://doi.org/10.1038/s41598-026-44850-5
Keywords: cervical cancer screening, medical AI uncertainty, conformal prediction, digital cytology, out-of-distribution detection