Clear Sky Science · ar
التحقق من توقعات التقارب في تصنيف الشذوذ العنقي
لماذا يهم وجود فحوصات أكثر ذكاءً لسرطان عنق الرحم
لا يزال سرطان عنق الرحم يودي بحياة مئات الآلاف من النساء سنوياً، خصوصاً في البلدان التي تعاني من نقص في الأطباء وأخصائيي المختبرات. قد تساعد أنظمة الذكاء الاصطناعي التي تفحص عينات الخلايا العنقية تحت المجهر في سد هذه الفجوة، لكن الأنظمة الحالية غالباً ما تعبر عن ثقة زائدة. فعادةً ما تعطي تصنيفاً واحداً باعتباره «التخمين الأفضل»، حتى عندما تكون الصورة صعبة التصنيف فعلاً. تطرح هذه الدراسة سؤالاً بسيطاً لكنه حاسم: عندما يقول الذكاء الاصطناعي إنه غير متأكد، هل يتوافق هذا الشك فعلاً مع ما يعتقده الخبراء البشريون؟
من إجابات وحيدة إلى قوائم قصيرة من الاحتمالات
تعكس معظم أدوات الذكاء الاصطناعي الطبية لصور مسحة بابانكولا طريقة كتابة تقارير المختبر الاعتيادية: تختار فئة واحدة مثل «طبيعي»، أو «تغيرات منخفضة الدرجة»، أو «تغيرات عالية الدرجة» وتلحقها باحتمالية. لكن هذه الدرجات الاحتمالية قد تبدو حادة بصورة مضللة. تتبع الطريقة التي استعرضتها هذه الورقة، المسماة توقع التقارب، مساراً مختلفاً. بدلاً من إجابة نهائية واحدة، تنتج مجموعة صغيرة من التسميات المحتملة لكل بلاطة صورة مأخوذة من شريحة. قد تحصل حالة واثقة جداً على تسمية واحدة، بينما قد تتلقى الحالة المعقدة عدة تسميات. من حيث المبدأ، ينبغي أن يمنح ذلك الأطباء رؤية أكثر صدقاً لما يعرفه النموذج وما لا يعرفه. 
بناء صورة غنية لاختلاف آراء الخبراء
لاختبار مدى نجاح هذه الفكرة في العالم الواقعي، جمع الباحثون مجموعة بيانات مفصلة من أكثر من 300 شريحة مسحة بابانكولا تم جمعها في مستشفى ريفي في كينيا. قام نظام ذكاء اصطناعي موجود مسبقاً أولاً بتمييز مناطق يحتمل أن تحوي خلايا غير طبيعية، ثم قُصت هذه المناطق إلى بلاطات صغيرة. بعد ذلك استخدم ستة خبراء متمرسين في علم الخلايا منصة ويب مخصصة لوضع تسميات لآلاف هذه البلاطات. بالنسبة لمجموعة اختبار أساسية، قام أربعة من الخبراء بتسمية نفس البلاطات بشكل مستقل. لم يخلق هذا مجرد «حقيقة أرضية» واحدة لكل بلاطة، بل نمطاً كاملاً من التوافق والاختلاف بين الخبراء، ما يلتقط أي الصور كانت حاسمة وأيها كانت غامضة بطبيعتها.
اختبار طرق مختلفة للتعبير عن عدم اليقين
درّب الفريق ثلاثة نماذج عميقة شائعة للتعرف على أربع فئات: طبيعي، تغيرات منخفضة الدرجة، تغيرات عالية الدرجة، وشوائب. وفوق كل نموذج طبقوا ثلاث نكهات من توقع التقارب تختلف في مدى اتساع مجموعات التسميات التي تنتجها. ثم قيّموا الأداء بطريقتين متممتين. أولاً، استخدموا مقاييس التغطية التقليدية التي تسأل ببساطة: هل تتضمن مجموعة التسميات المتوقعة تسمية الخبراء الإجماعية على الأقل بنسبة مئوية مختارة من الوقت؟ ثانياً، قدموا مقاييس بنمط الاتفاق التي تقارن كل مجموعة تنبؤ بالمجموعة الكاملة من التسميات التي أعطاها جميع الخبراء لتلك البلاطة، مكافئةً الحالات التي تتطابق فيها القائمة القصيرة للنموذج مع نطاق آراء الخبراء.
عندما ترسم المقاييس التقليدية صورة وردية جداً
بحسب مقاييس التغطية التقليدية، بدت طرق التقارب مثيرة للإعجاب: فقد تضمنت تقريباً دائماً تسمية الخبراء الإجماعية، خصوصاً عندما سُمح لها بإخراج مجموعات أكبر قليلاً. لكن اختبارات الاتفاق الأكثر تشدداً روت قصة مختلفة. كانت المطابقات الدقيقة بين مجموعات تسميات الذكاء الاصطناعي والتسميات المجمعة من الخبراء نحو ثلث الحالات فقط، بغض النظر عن الطريقة. فضلت بعض النهج مجموعات صغيرة ودقيقة فوتت تسميات اعتبرها الخبراء ممكنة، بينما أنتجت طرق أخرى مجموعات أكبر شملت تسميات غير محتملة إلى جانب الصحيحة. أداؤها كان جيداً في تتبع الغموض المتأصل: عندما اختلف الخبراء أكثر، نمت مجموعات التقارب عادةً في الحجم. ومع ذلك، كانت أقل موثوقية بكثير في الإشارة إلى الصور التي لا تنتمي فعلاً لتوزيع التدريب، مثل مسحات بابانكولا ذات ضوضاء شديدة أو خلايا نخاع العظم من نسيج مختلف، وكان هذا السلوك يعتمد بقوة على النموذج الأساسي المستخدم. 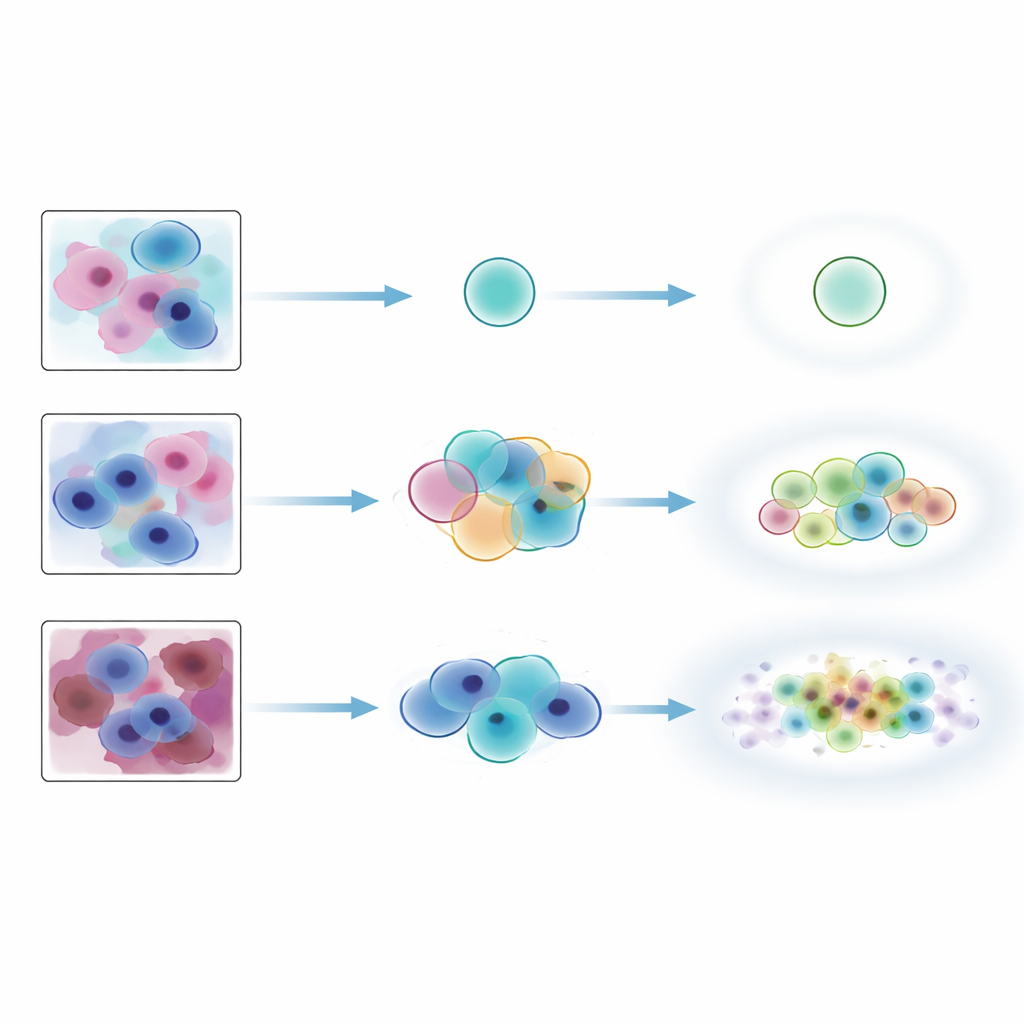
ما الذي يعنيه هذا للاستخدام في العالم الحقيقي
بالنسبة للأطباء الذين يفكرون في أدوات دعم الذكاء الاصطناعي، الخلاصة الرئيسية هي أن تقديرات عدم اليقين ليست موثوقة تلقائياً لمجرد أنها تأتي مع ضمانات رياضية. يمكن لتوقع التقارب أن يضمن أن التسمية الحقيقية غالباً ما تكون موجودة في مجموعة التسميات المتوقعة، لكن تُظهر هذه الدراسة أن التسميات الإضافية في تلك المجموعة قد لا تتوافق مع توقعات البشر وقد تشوش أحياناً عن الاحتمالات الأكثر صلة. يجادل المؤلفون بأنه في مجالات ذات مخاطر عالية مثل فحص السرطان، يجب تقييم مخرجات الذكاء الاصطناعي ليس فقط من حيث كونها «صحيحة» تقنياً، بل أيضاً من حيث تقديم المعلومات بطريقة مركزة وذات مغزى سريرياً. سيحتاج العمل المستقبلي إلى تحسين كل من النماذج وأدوات عدم اليقين بحيث تبدو القوائم القصيرة للتشخيصات منطقية للخبراء كما هو مرضٍ حسابياً.
الاستشهاد: Hagos, M.T., Suutala, A., Bychkov, D. et al. Validation of conformal prediction in cervical atypia classification. Sci Rep 16, 9649 (2026). https://doi.org/10.1038/s41598-026-44850-5
الكلمات المفتاحية: فحص سرطان عنق الرحم, عدم اليقين في الذكاء الاصطناعي الطبي, توقع التقارب, علم الخلايا الرقمي, كشف البيانات خارج التوزيع