Clear Sky Science · it
Validazione della prediction conforme nella classificazione delle atipie cervicali
Perché uno screening più intelligente per il cancro cervicale è importante
Il cancro cervicale continua a uccidere centinaia di migliaia di donne ogni anno, soprattutto in paesi dove medici e specialisti di laboratorio scarseggiano. I sistemi di intelligenza artificiale (AI) che esaminano i campioni di cellule cervicali al microscopio potrebbero contribuire a colmare questa lacuna, ma gli strumenti odierni spesso parlano con troppa sicurezza. Di solito forniscono un’unica etichetta «migliore ipotesi», anche quando l’immagine è davvero difficile da classificare. Questo studio pone una domanda semplice ma cruciale: quando un’AI dice di essere incerta, quell’incertezza corrisponde effettivamente a quanto pensano gli esperti umani?
Dalle risposte singole alle shortlist di possibilità
La maggior parte degli strumenti di AI per le immagini di Pap test imita il modo in cui sono redatti i referti di laboratorio standard: scelgono una categoria come «normale», «alterazioni di basso grado» o «alterazioni di alto grado» e forniscono una probabilità. Ma questi punteggi di probabilità possono risultare ingannevolmente netti. Il metodo studiato in questo articolo, chiamato prediction conforme, prende una strada diversa. Invece di dare una risposta finale unica, produce per ogni tassello dell’immagine un piccolo insieme di etichette plausibili. Un caso su cui è molto sicuro potrebbe ricevere una sola etichetta, mentre un caso difficile potrebbe ottenerne diverse. In linea di principio, questo dovrebbe offrire ai clinici una visione più onesta di ciò che il modello conosce e di ciò che non conosce. 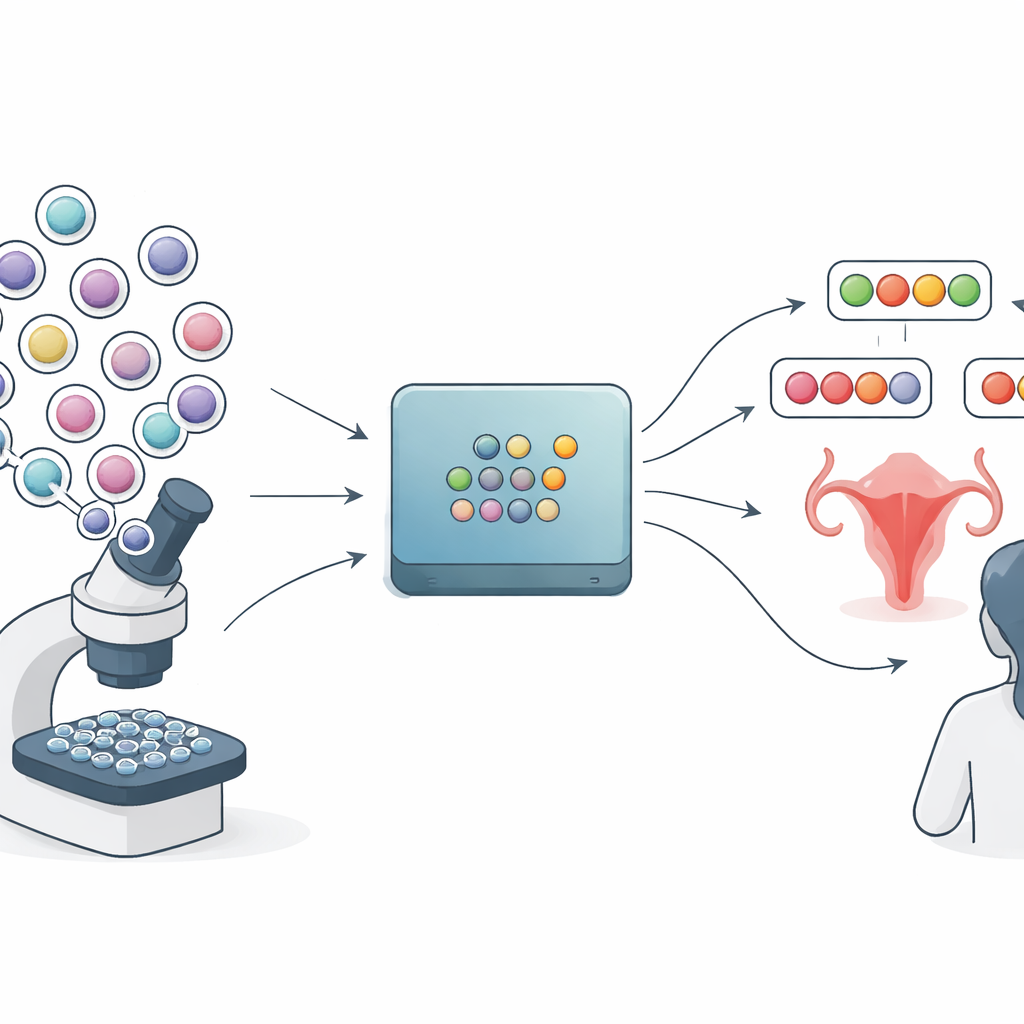
Costruire un quadro ricco del disaccordo tra esperti
Per verificare quanto questa idea funzioni nel mondo reale, i ricercatori hanno assemblato un dataset dettagliato tratto da oltre 300 vetrini di Pap raccolti in un ospedale rurale in Kenya. Un sistema AI esistente ha prima evidenziato le regioni probabilmente contenenti cellule anomale, e queste regioni sono state ritagliate in piccoli tasselli. Sei esperti di citologia con esperienza hanno poi utilizzato una piattaforma web su misura per etichettare migliaia di questi tasselli. Per un set di test centrale, quattro esperti hanno etichettato gli stessi tasselli in modo indipendente. Questo ha creato non una singola «verità di riferimento» per tassello, ma un vero e proprio profilo di accordo e disaccordo tra esperti, catturando quali immagini erano nette e quali erano naturalmente ambigue.
Testare diversi modi di esprimere l’incertezza
Il team ha addestrato tre modelli di deep learning popolari a riconoscere quattro categorie: normale, alterazioni di basso grado, alterazioni di alto grado e artefatti. Su ciascun modello hanno applicato tre varianti di prediction conforme che differiscono per la tendenza ad avere insiemi di etichette più o meno ampi. Hanno poi valutato le prestazioni in due modi complementari. Primo, hanno usato misure standard di coverage che si limitano a chiedere: l’insieme delle etichette predette include l’etichetta di consenso degli esperti almeno per una certa percentuale di volte? Secondo, hanno introdotto misure di tipo agreement che confrontano ogni insieme predetto con la lista completa delle etichette assegnate da tutti gli esperti per quel tassello, premiando i casi in cui la shortlist dell’AI corrisponde alla gamma di opinioni degli esperti.
Quando le metriche standard dipingono un quadro troppo ottimistico
Secondo le misure convenzionali di coverage, i metodi conformi sembravano impressionanti: quasi sempre includevano l’etichetta di consenso degli esperti, specialmente quando era permesso di restituire insiemi leggermente più grandi. Ma i test più rigorosi di agreement raccontavano una storia diversa. Le corrispondenze esatte tra gli insiemi di etichette dell’AI e le etichette combinate degli esperti erano solo circa un terzo dei casi, indipendentemente dal metodo. Alcuni approcci privilegiavano insiemi piccoli e precisi che escludevano etichette ritenute plausibili dagli esperti, mentre altri producevano insiemi più ampi che includevano etichette improbabili insieme a quella corretta. I metodi si sono dimostrati abili nel seguire l’ambiguità intrinseca: quando gli esperti umani erano in maggiore disaccordo, gli insiemi conformi tendevano ad aumentare di dimensione. Tuttavia, erano molto meno affidabili nel segnalare immagini che davvero non appartenevano alla distribuzione di addestramento, come Pap test molto rumorosi o campioni di midollo osseo provenienti da un diverso tipo di tessuto, e questo comportamento dipendeva fortemente dal modello sottostante utilizzato. 
Cosa significa per l’uso nel mondo reale
Per i clinici che considerano strumenti di supporto basati su AI, la conclusione principale è che le stime di incertezza non sono automaticamente affidabili solo perché accompagnate da garanzie matematiche. La prediction conforme può assicurare che l’etichetta vera sia molto spesso da qualche parte nell’insieme predetto, ma questo studio mostra che le etichette aggiuntive in quell’insieme potrebbero non corrispondere alle aspettative umane e potrebbero persino distrarre dalle possibilità più rilevanti. Gli autori sostengono che in ambiti ad alto rischio come lo screening oncologico, le uscite dell’AI vanno giudicate non solo in base al fatto che siano tecnicamente «corrette», ma anche in base al fatto che presentino informazioni in modo mirato e clinicamente significativo. Lavori futuri dovranno perfezionare sia i modelli sia gli strumenti di incertezza in modo che le loro shortlist diagnostiche risultino tanto sensate per gli esperti quanto soddisfacenti per le equazioni.
Citazione: Hagos, M.T., Suutala, A., Bychkov, D. et al. Validation of conformal prediction in cervical atypia classification. Sci Rep 16, 9649 (2026). https://doi.org/10.1038/s41598-026-44850-5
Parole chiave: screening del cancro cervicale, incertezza nelle AI mediche, prediction conforme, citologia digitale, rilevamento out-of-distribution