Clear Sky Science · sv
Dubbelgrensat uppmärksamhetsnät med djup uppdelningskonvolution och mångdimensionella transformatorer för segmentering av medicinska bilder
Skarpare vyer för läkare
Moderna avbildningar kan visa tumörer, tilltäppta kärl och skadade organ i imponerande detalj, men att omvandla dessa gråvita bilder till tydliga konturer som en dator kan tolka är fortfarande förvånansvärt svårt. Läkare behöver precisa avgränsningar runt organ och sjukt vävnad för att planera operationer, följa behandling och undvika misstag. Denna studie presenterar ett nytt artificiellt intelligenssystem, kallat D3T-Net, som ritar dessa gränser mer exakt och mer pålitligt än många ledande metoder, vilket potentiellt kan avlasta radiologer och öka förtroendet för diagnostiken.
Varför det är så svårt att rita linjer på medicinska bilder
När en radiolog tittar på en CT- eller röntgenbild separerar hen mentalt överlappande strukturer, bortser från brus och lägger ihop saknade kanter. Traditionella datorprogram har svårt med detta, särskilt när organformer varierar mellan personer eller när en tumörs gräns är suddig. Tidigare system baserade på konvolutionsneuronnät är mycket bra på att fånga lokala texturer och kanter, men de ser ofta bara en liten omgivning åt gången. Det gör att de lätt missar det bredare sammanhanget som behövs för att skilja till exempel en svag tumörkant från normal vävnad. Nyare "Transformer"-modeller fångar däremot långdistansrelationer över hela bilden, men tenderar ibland att förbise fina detaljer som små lesioner eller tunna gränser.
Två kompletterande sätt att se
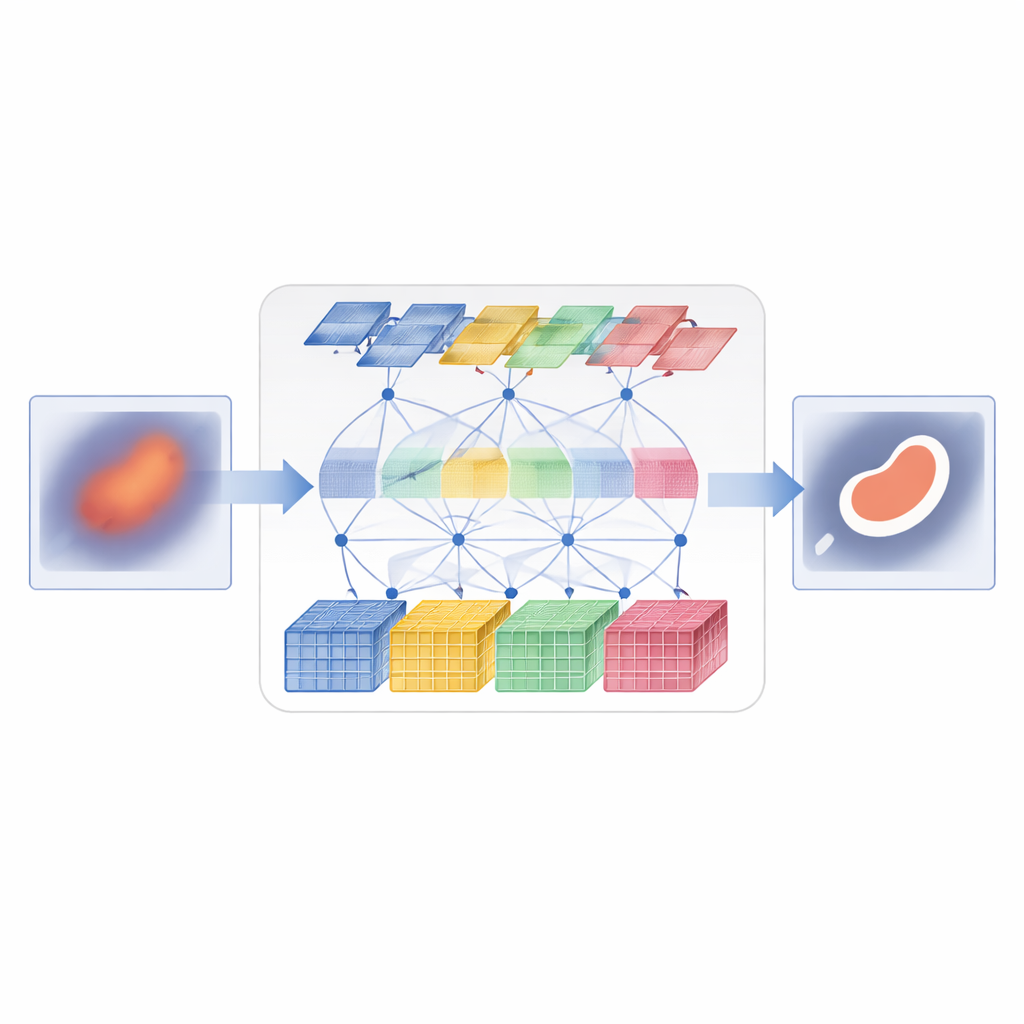
D3T-Net tacklar denna utmaning genom att kombinera båda synsätten i ett enda, tätt koordinerat nätverk. En gren beter sig som en traditionell bildanalysator och fokuserar på små patchar för att fånga fina texturer och skarpa kanter. Den använder en "djup uppdelnings"-strategi: inkommande bildfunktioner delas upp i flera parallella strömmar, bearbetas separat och sedan sammanfogas med en uppmärksamhetsmekanism som beslutar vilka strömmar som bär den mest användbara strukturella informationen. Den andra grenen fungerar mer som en global observatör och använder transformatorliknande uppmärksamhet för att jämföra avlägsna delar av bilden och förstå hur regioner relaterar till varandra. Den ser inte bara över bildplanet utan också över feature-kanaler, vilket gör det möjligt att fånga både var saker befinner sig och hur deras utseendemönster hänger ihop.
Få båda grenarna att samarbeta
Att bara köra två grenar parallellt räcker inte; de måste utbyta information på ett smart sätt. I encoder-delen av D3T-Net undersöker en särskild interaktionsmodul mönster från flera riktningar över bilden och använder pooling och uppmärksamhet för att framhäva de mest informativa strukturerna—som organsilhuetter eller lesionkärnor—och dela denna betoning mellan den lokala och den globala grenen. I decoder-delen, där den slutliga segmenteringskartan sätts ihop, lär sig en kors-uppmärksamhetsmekanism hur man kombinerar vad varje gren har lärt sig och organiserar om funktioner så att globalt sammanhang skärper lokala kanter och lokala detaljer förfinar den bredare globala bilden. Multiskaliga skip-anslutningar för vidare information från tidiga, högupplösta bearbetningssteg till senare steg, vilket hjälper systemet att hålla reda på små objekt och känsliga gränser som annars kunde gå förlorade.
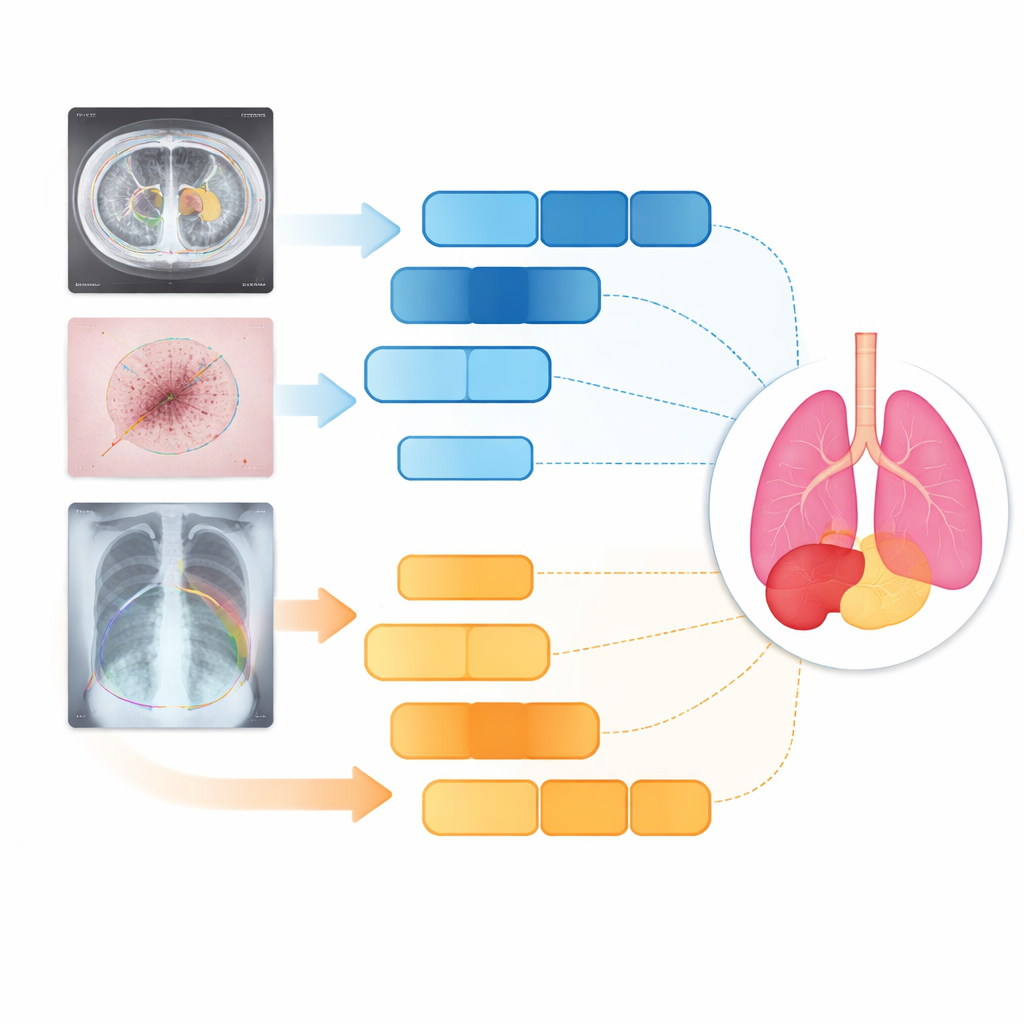
Testning på organ, hud och lungor
Forskarna testade D3T-Net på tre mycket olika medicinska uppgifter: att markera bukorgan på CT-skanningar, spåra hudlesioner i kliniska fotografier och segmentera lungor på thoraxröntgen. I standardmått för noggrannhet och kantskärpa överträffade D3T-Net konsekvent en bred uppställning av moderna system, inklusive välkända U-Net-varianter och transformatorbaserade hybrider. Det var särskilt starkt på att hålla organskonturer kontinuerliga, korrekt separera intilliggande strukturer och fånga små eller lågkontrastmål som gallblåsan eller oregelbundna hudlesioner. Viktigt är att dessa vinster uppnåddes utan en extrem ökning av beräkningstiden: modellens bearbetningskostnad förblev jämförbar med många välanvända nätverk, vilket gör det troligt att den kan användas i klinisk praxis.
Vad detta betyder för patienter och kliniker
Enkelt uttryckt visar studien att när en algoritm får "tänka" både lokalt och globalt samtidigt leder det till renare avgränsningar av organ och sjukdom på medicinska bilder. Genom att noggrant samordna en detaljorienterad gren med en kontextmedveten gren kan D3T-Net skilja frisk och sjuk vävnad mer exakt än många befintliga verktyg. Även om den inte kommer att ersätta radiologer kan den fungera som en kraftfull assistent—automatiskt försegmentera skanningar, flagga subtila lesioner och leverera mer tillförlitliga masker för efterföljande uppgifter som 3D-planering eller behandlingsuppföljning. När liknande dubbelvy-designs tillämpas på andra avbildningsproblem kan patienter få fördelar i form av snabbare, mer konsekvent och mer personligt anpassad vård.
Citering: Li, D., Yuan, C., Yao, Y. et al. Dual-branch attention network with deep split convolution and multi-dimensional transformers for medical image segmentation. Sci Rep 16, 14238 (2026). https://doi.org/10.1038/s41598-026-44413-8
Nyckelord: segmentering av medicinska bilder, djupinlärning, transformatornätverk, lever- och organsanalys, datorstödd diagnostik