Clear Sky Science · es
Red de atención de doble rama con convolución dividida profunda y transformadores multidimensionales para segmentación de imágenes médicas
Vistas más nítidas para los médicos
Las exploraciones modernas pueden revelar tumores, vasos obstruidos y órganos dañados con un detalle sorprendente, pero convertir esas imágenes en escala de grises en contornos claros que un ordenador entienda sigue siendo notablemente difícil. Los médicos necesitan límites precisos alrededor de los órganos y del tejido enfermo para planificar cirugías, seguir tratamientos y evitar errores. Este estudio presenta un nuevo sistema de inteligencia artificial, llamado D3T-Net, que traza esos contornos con mayor precisión y fiabilidad que muchos métodos punteros, lo que podría aliviar la carga de los radiólogos y aumentar la confianza diagnóstica.
Por qué es tan difícil dibujar líneas en exploraciones médicas
Cuando un radiólogo examina una imagen de TC o una radiografía, separa mentalmente estructuras solapadas, descarta el ruido e infiere bordes ausentes. Los programas tradicionales tienen problemas con esto, sobre todo cuando las formas de los órganos varían entre personas o cuando el borde de un tumor está difuminado. Los sistemas anteriores basados en redes convolucionales destacan en captar texturas locales y bordes, pero tienden a ver solo un vecindario pequeño a la vez. Eso facilita que pasen por alto el contexto más amplio necesario para distinguir, por ejemplo, un borde tumoral tenue de tejido normal. Por otro lado, los modelos tipo “Transformer” captan bien las relaciones a larga distancia en toda la imagen, pero a menudo sacrifican detalles finos como lesiones diminutas o límites delgados.
Dos maneras complementarias de ver
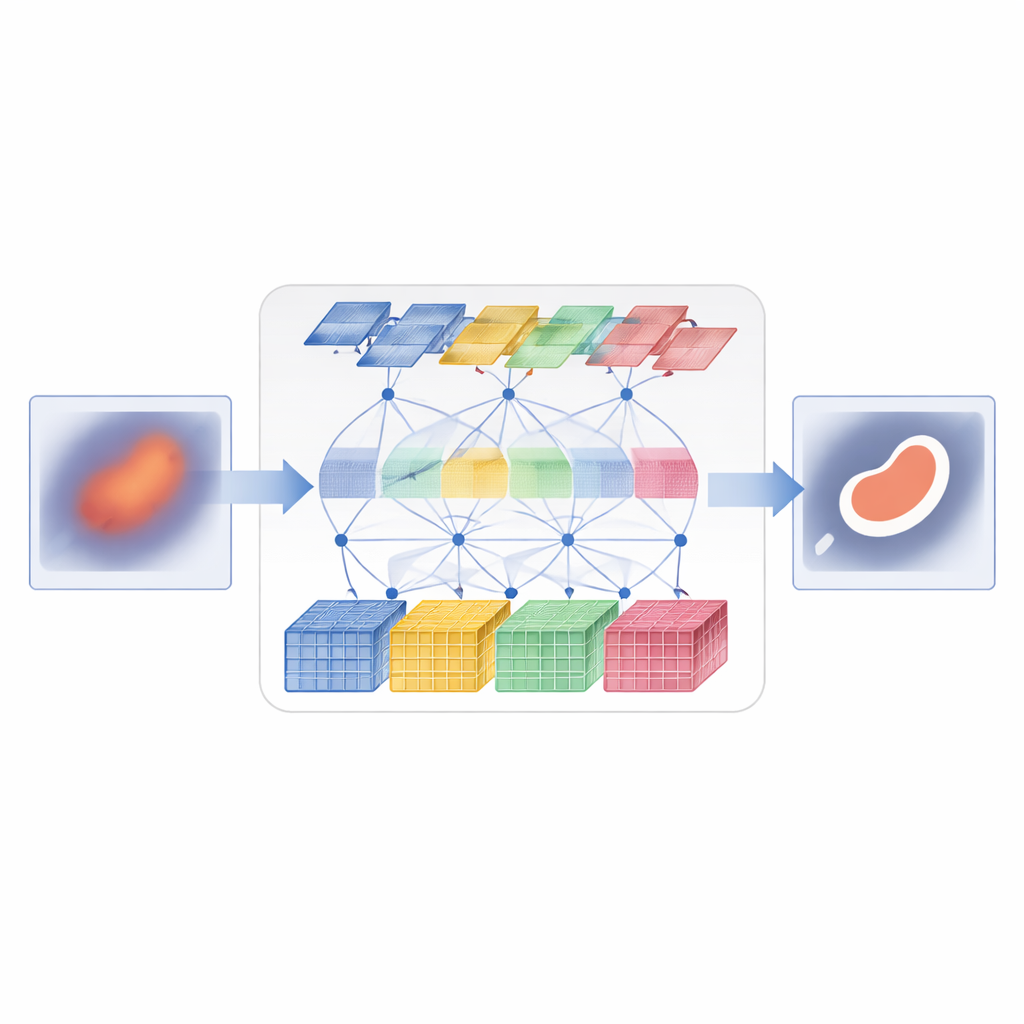
D3T-Net aborda este reto combinando ambas formas de ver en una única red estrechamente coordinada. Una rama actúa como un analizador tradicional de imágenes, centrándose en parches pequeños para capturar texturas finas y bordes nítidos. Emplea una estrategia de «división profunda»: las características de la imagen entrante se dividen en múltiples flujos paralelos, se procesan por separado y luego se fusionan mediante un mecanismo de atención que decide qué flujos contienen la información estructural más útil. La otra rama funciona más como un observador global, usando atención al estilo Transformer para comparar partes distantes de la imagen y entender cómo se relacionan las regiones entre sí. Mira no solo a través del plano de la imagen, sino también a través de los canales de características, lo que le permite capturar tanto dónde están las cosas como cómo se combinan sus patrones de apariencia.
Lograr que ambas ramas cooperen
Ejecutar simplemente dos ramas en paralelo no es suficiente; deben intercambiar información de forma inteligente. En la parte de codificador de D3T-Net, un módulo especial de interacción examina patrones desde múltiples direcciones a lo largo de la imagen, usando pooling y atención para resaltar las estructuras más informativas—como contornos de órganos o núcleos de lesiones—y compartir ese énfasis entre las ramas local y global. En la parte del decodificador, donde se ensambla el mapa de segmentación final, un mecanismo de atención cruzada aprende cómo combinar lo que cada rama ha aprendido, reorganizando las características para que el contexto global agudice los bordes locales y el detalle local refine la visión global. Conexiones skip multi-escala llevan información de etapas iniciales y de alta resolución directamente a etapas posteriores, ayudando al sistema a seguir pequeños objetos y bordes delicados que de otro modo podrían perderse.
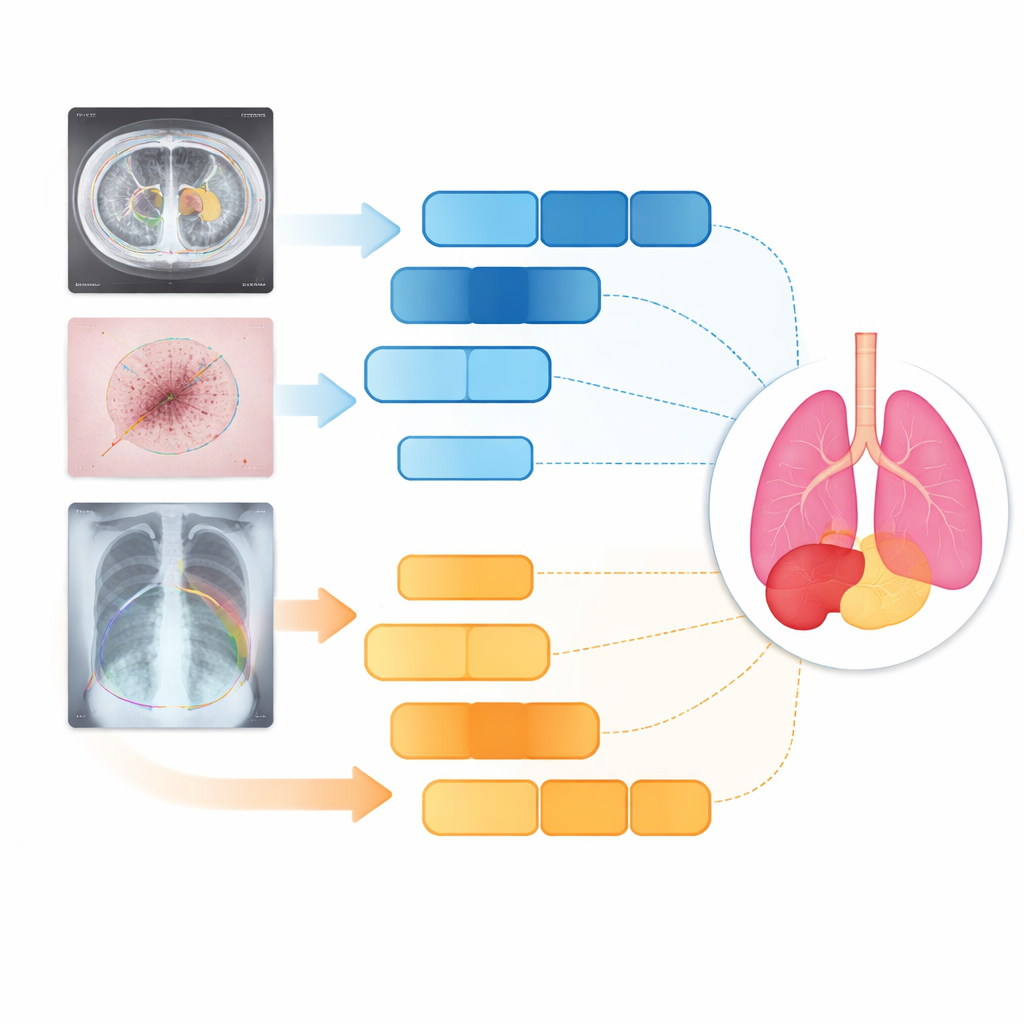
Pruebas en órganos, piel y pulmones
Los investigadores probaron D3T-Net en tres tareas médicas muy diferentes: delinear órganos abdominales en tomografías, trazar lesiones cutáneas en fotografías clínicas y segmentar pulmones en radiografías de tórax. Según medidas estándar de precisión y nitidez de bordes, D3T-Net superó de forma consistente a una amplia gama de sistemas de última generación, incluidas variantes conocidas de U-Net e híbridos basados en Transformers. Fue especialmente eficaz en mantener contornos de órganos continuos, separar correctamente estructuras vecinas y capturar objetivos pequeños o de bajo contraste como la vesícula biliar o lesiones cutáneas irregulares. Es importante que estas mejoras no implicaron un aumento extremo del tiempo de cómputo: el coste de procesamiento del modelo se mantuvo comparable al de muchas redes ampliamente usadas, lo que lo hace plausible para su implementación clínica.
Qué significa esto para pacientes y clínicos
En términos sencillos, el estudio muestra que permitir que un algoritmo «piense» tanto de forma local como global al mismo tiempo conduce a contornos más limpios de órganos y enfermedades en imágenes médicas. Al coordinar cuidadosamente una rama orientada al detalle con otra consciente del contexto, D3T-Net puede distinguir tejido sano de tejido enfermo con mayor precisión que muchas herramientas existentes. Aunque no reemplazará a los radiólogos, puede servir como un asistente potente: presegmentando automáticamente exploraciones, señalando lesiones sutiles y proporcionando máscaras más fiables para tareas posteriores como planificación 3D o monitorización del tratamiento. A medida que diseños duales similares se apliquen a otros problemas de imagen, los pacientes podrían beneficiarse de una atención más rápida, más consistente y más personalizada.
Cita: Li, D., Yuan, C., Yao, Y. et al. Dual-branch attention network with deep split convolution and multi-dimensional transformers for medical image segmentation. Sci Rep 16, 14238 (2026). https://doi.org/10.1038/s41598-026-44413-8
Palabras clave: segmentación de imágenes médicas, aprendizaje profundo, redes tipo transformer, análisis de hígado y órganos, diagnóstico asistido por ordenador