Clear Sky Science · pt
Rede de atenção com dois ramos, convolução profunda dividida e transformadores multidimensionais para segmentação de imagens médicas
Visões mais nítidas para médicos
Exames modernos podem revelar tumores, vasos obstruídos e órgãos danificados com detalhes impressionantes, mas transformar essas imagens em tons de cinza em contornos claros que um computador entenda ainda é surpreendentemente difícil. Médicos precisam de limites precisos ao redor de órgãos e tecidos doentes para planejar cirurgias, acompanhar tratamentos e evitar erros. Este estudo apresenta um novo sistema de inteligência artificial, chamado D3T-Net, que traça esses limites de forma mais precisa e confiável do que muitos métodos de ponta, potencialmente reduzindo a carga de trabalho dos radiologistas e aumentando a confiança diagnóstica.
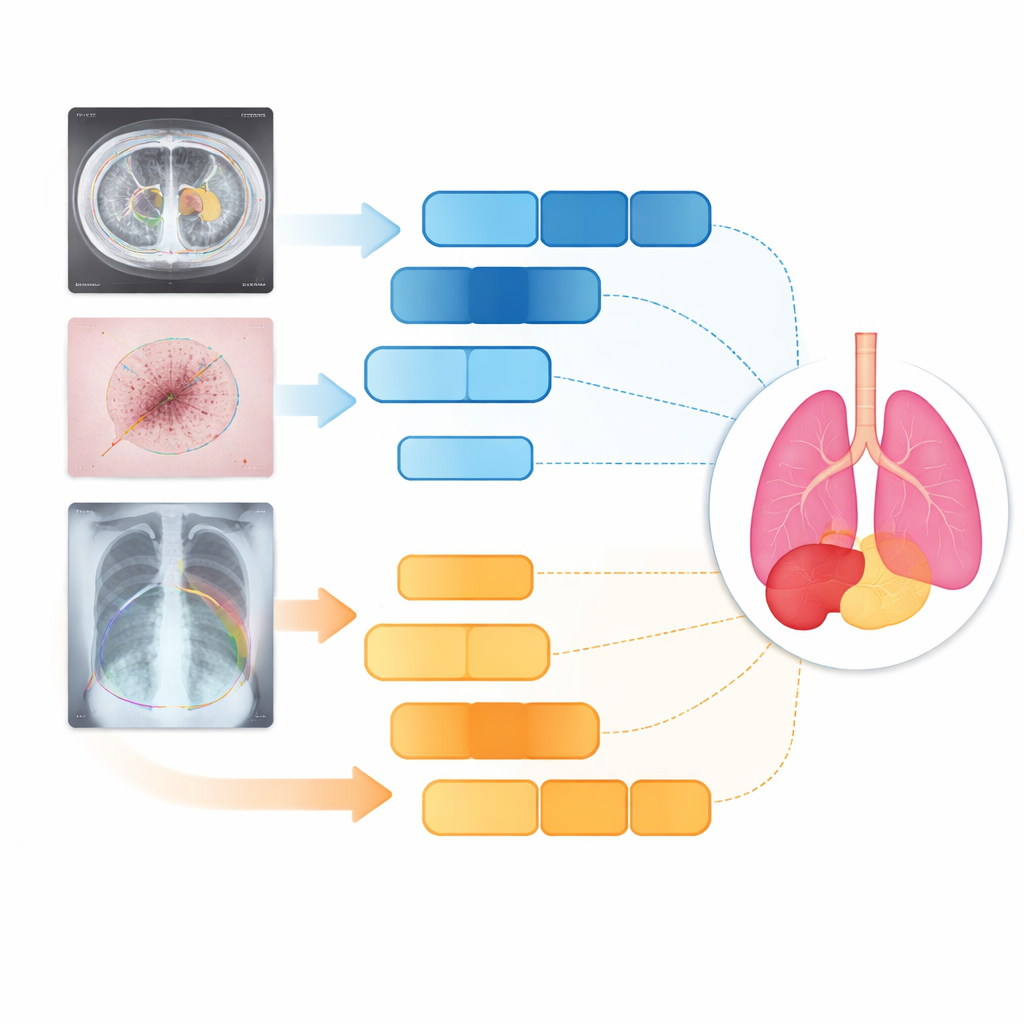
Por que desenhar linhas em exames médicos é tão difícil
Quando um radiologista olha para uma imagem de TC ou raio‑X, ele separa mentalmente estruturas sobrepostas, ignora ruído e infere bordas ausentes. Programas tradicionais têm dificuldade com isso, especialmente quando as formas dos órgãos variam de pessoa para pessoa ou quando a borda de um tumor está borrada. Sistemas anteriores baseados em redes neurais convolucionais são excelentes em captar texturas locais e bordas, mas tendem a ver apenas uma pequena vizinhança por vez. Isso facilita que percam o contexto mais amplo necessário para distinguir, por exemplo, a borda tênue de um tumor de tecido normal. Por outro lado, modelos mais novos do tipo Transformer são bons em capturar relações de longo alcance em toda a imagem, mas frequentemente deixam de lado detalhes finos, como pequenas lesões ou limites sutis.
Dupla maneira complementar de ver
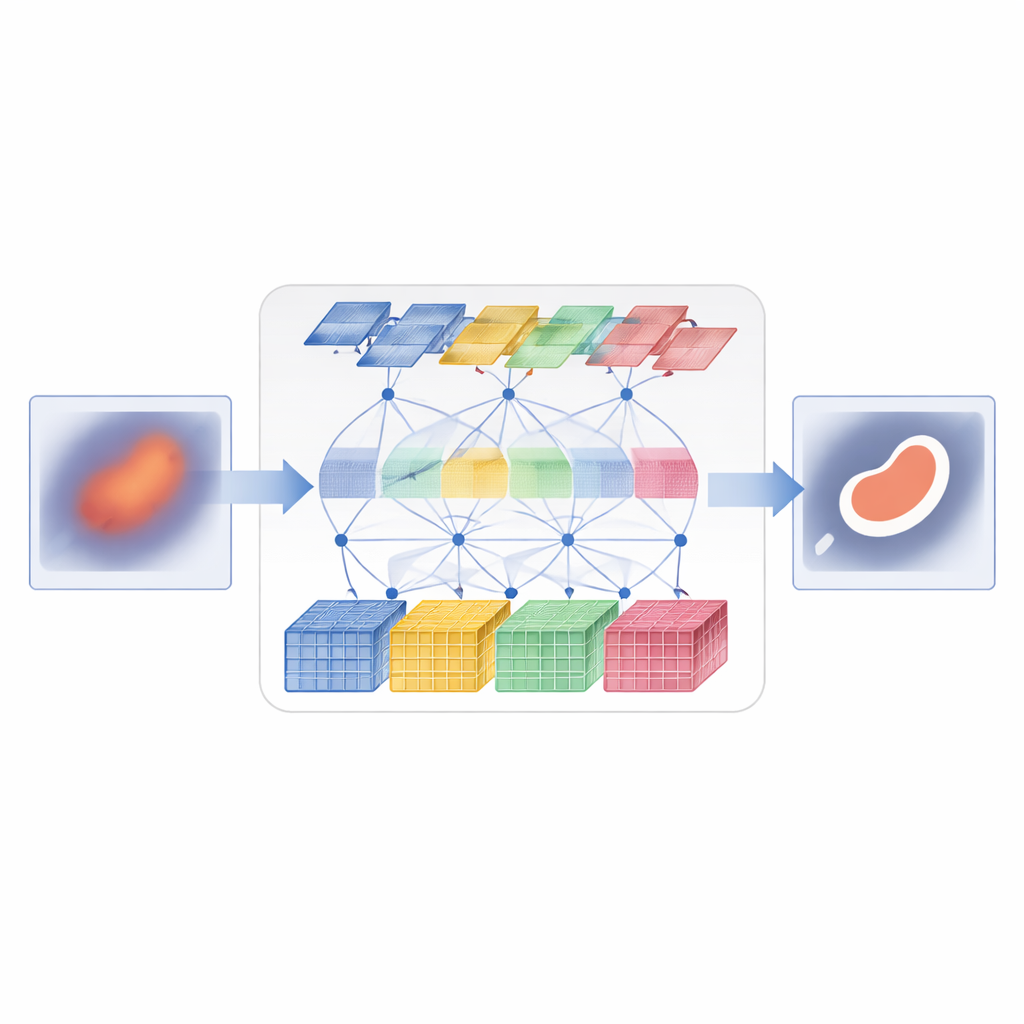
O D3T-Net enfrenta esse desafio combinando ambas as maneiras de ver em uma única rede coordenada. Um ramo se comporta como um analisador de imagem tradicional, focando em pequenos blocos para captar texturas finas e bordas nítidas. Ele usa uma estratégia de “divisão profunda”: as características de entrada são divididas em múltiplos fluxos paralelos, processadas separadamente e depois fundidas com um mecanismo de atenção que decide quais fluxos trazem as informações estruturais mais úteis. O outro ramo age mais como um observador global, usando atenção no estilo Transformer para comparar partes distantes da imagem e entender como as regiões se relacionam. Ele observa não apenas no plano da imagem, mas também através dos canais de característica, permitindo capturar tanto onde as coisas estão quanto como seus padrões de aparência se combinam.
Fazendo os dois ramos cooperarem
Executar dois ramos em paralelo não basta; eles precisam trocar informação de forma inteligente. Na parte do codificador do D3T-Net, um módulo de interação especial examina padrões em múltiplas direções pela imagem, usando pooling e atenção para destacar as estruturas mais informativas — como contornos de órgãos ou núcleos de lesões — e compartilhar esse destaque entre os ramos local e global. Na parte do decodificador, onde o mapa de segmentação final é montado, um mecanismo de atenção cruzada aprende a combinar o que cada ramo aprendeu, reorganizando características para que o contexto global afine bordas locais e o detalhe local refine a visão global ampla. Conexões de salto em múltiplas escalas levam informações de estágios iniciais de alta resolução diretamente para estágios posteriores, ajudando o sistema a acompanhar objetos pequenos e limites delicados que poderiam ser perdidos.
Testes em órgãos, pele e pulmões
Os pesquisadores testaram o D3T-Net em três tarefas médicas bastante diferentes: contornar órgãos abdominais em tomografias, traçar lesões cutâneas em fotografias clínicas e segmentar pulmões em radiografias de tórax. Em medidas padrão de acurácia e nitidez de contorno, o D3T-Net superou consistentemente uma ampla gama de sistemas de estado da arte, incluindo variantes conhecidas do U‑Net e híbridos baseados em Transformer. Foi particularmente forte em manter contornos de órgãos contínuos, separar corretamente estruturas vizinhas e capturar alvos pequenos ou de baixo contraste, como a vesícula biliar ou lesões cutâneas irregulares. Importante, esses ganhos vieram sem um aumento extremo no tempo de processamento: o custo computacional do modelo permaneceu comparável ao de muitas redes amplamente usadas, tornando-o plausível para implantação clínica.
O que isso significa para pacientes e clínicos
Em termos simples, o estudo mostra que permitir que um algoritmo “pense” tanto local quanto globalmente ao mesmo tempo leva a contornos mais limpos de órgãos e doenças em imagens médicas. Ao coordenar cuidadosamente um ramo orientado a detalhes com um ramo atento ao contexto, o D3T-Net pode separar tecido saudável e doente com mais precisão do que muitas ferramentas existentes. Embora não substitua radiologistas, ele pode servir como um assistente poderoso — pré‑segmentando automaticamente exames, sinalizando lesões sutis e fornecendo máscaras mais confiáveis para tarefas posteriores, como planejamento 3D ou monitoramento de tratamento. À medida que designs de visão dupla semelhantes forem aplicados a outros problemas de imagem, pacientes podem se beneficiar de cuidados mais rápidos, consistentes e personalizados.
Citação: Li, D., Yuan, C., Yao, Y. et al. Dual-branch attention network with deep split convolution and multi-dimensional transformers for medical image segmentation. Sci Rep 16, 14238 (2026). https://doi.org/10.1038/s41598-026-44413-8
Palavras-chave: segmentação de imagens médicas, aprendizado profundo, redes Transformer, análise do fígado e órgãos, diagnóstico assistido por computador