Clear Sky Science · it
Rete di attenzione a doppio ramo con convoluzione profonda divisa e transformer multidimensionali per la segmentazione di immagini mediche
Visioni più nitide per i medici
Le moderne scansioni possono rivelare tumori, vasi ostruiti e organi danneggiati con dettagli sorprendenti, ma trasformare quelle immagini in scala di grigi in contorni precisi che un computer possa interpretare resta sorprendentemente difficile. I medici hanno bisogno di confini accurati intorno agli organi e ai tessuti malati per pianificare gli interventi, monitorare i trattamenti ed evitare errori. Questo studio presenta un nuovo sistema di intelligenza artificiale, chiamato D3T-Net, che traccia quei confini in modo più accurato e affidabile rispetto a molti metodi di punta, alleggerendo potenzialmente il carico di lavoro dei radiologi e migliorando la fiducia diagnostica.
Perché tracciare i contorni nelle immagini mediche è così difficile
Quando un radiologo osserva una TC o una radiografia, separa mentalmente strutture sovrapposte, ignora il rumore e inferisce i bordi mancanti. I programmi tradizionali fanno fatica in questo, soprattutto quando le forme degli organi variano da persona a persona o quando il bordo di un tumore è sfumato. I sistemi basati su reti neurali convoluzionali eccellono nell’individuare texture locali e bordi, ma tendono a considerare solo un piccolo intorno alla volta. Questo li porta a perdere il contesto più ampio necessario per distinguere, per esempio, il bordo tenue di un tumore dal tessuto normale. D’altro canto, i modelli più recenti basati su Transformer sono bravi a catturare relazioni a lungo raggio su tutta l’immagine, ma spesso trascurano i dettagli fini come piccole lesioni o sottili confini.
Due modi complementari di osservare
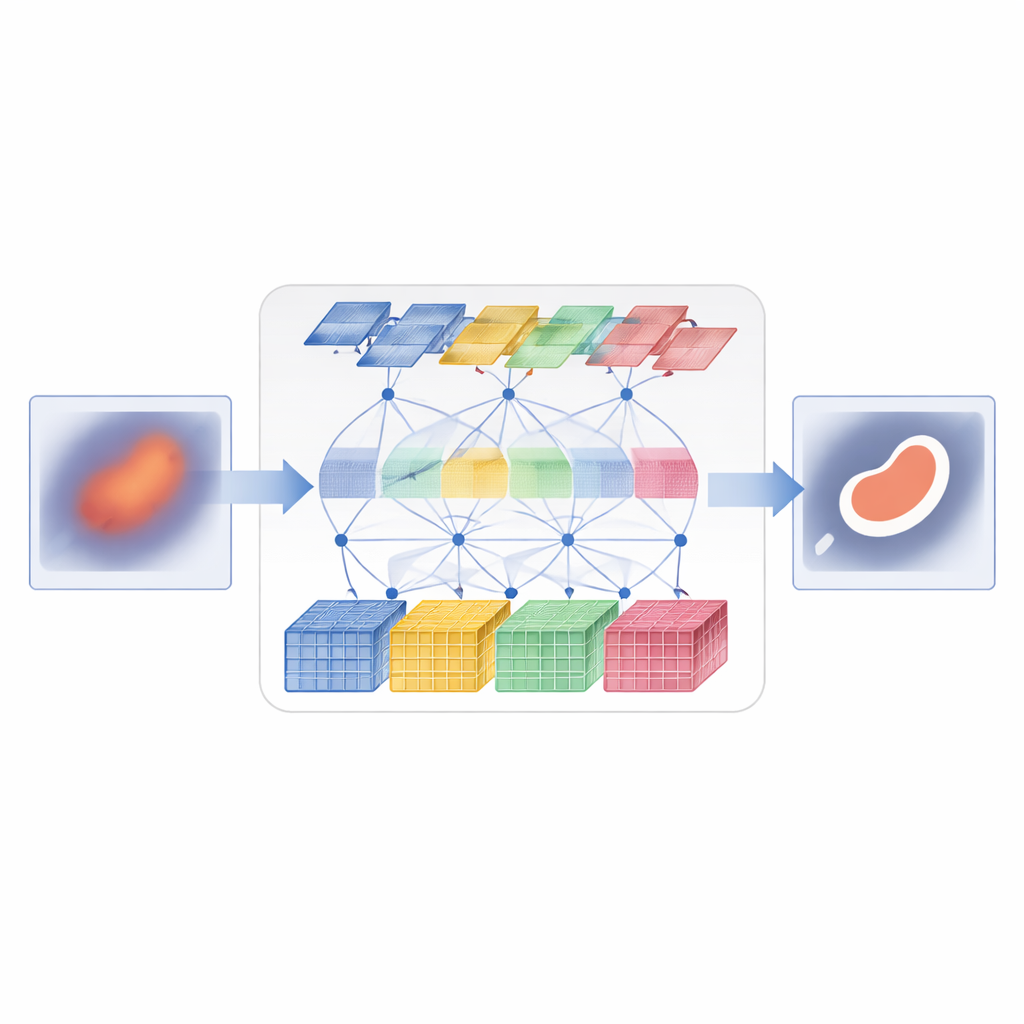
D3T-Net affronta questa sfida combinando entrambi i modi di vedere in una singola rete strettamente coordinata. Un ramo si comporta come un analizzatore d’immagine tradizionale, concentrandosi su piccole regioni per catturare texture fini e bordi netti. Usa una strategia di “deep splitting”: le feature in ingresso vengono divise in più flussi paralleli, processate separatamente e poi fuse con un meccanismo di attenzione che decide quali flussi contengono le informazioni strutturali più utili. L’altro ramo agisce più come un osservatore globale, usando attenzione in stile Transformer per confrontare parti distanti dell’immagine e comprendere come le regioni si relazionano tra loro. Non guarda solo attraverso il piano dell’immagine ma anche lungo i canali delle feature, permettendo di catturare sia dove si trovano gli oggetti sia come i loro pattern di aspetto si combinano.
Far cooperare i due rami
Far girare semplicemente due rami in parallelo non basta; devono scambiarsi informazioni in modo intelligente. Nella parte encoder di D3T-Net, un modulo di interazione speciale esamina i pattern da più direzioni sull’immagine, usando pooling e attenzione per evidenziare le strutture più informative—come i contorni degli organi o i nuclei delle lesioni—and per condividere questa enfasi tra i rami locale e globale. Nella parte decoder, dove si compone la mappa di segmentazione finale, un meccanismo di cross-attention impara a combinare ciò che ciascun ramo ha appreso, riorganizzando le feature in modo che il contesto globale affini i bordi locali e il dettaglio locale perfezioni la visione globale. Connessioni skip multi-scala trasportano informazioni dalle fasi iniziali ad alta risoluzione direttamente alle fasi successive, aiutando il sistema a non perdere oggetti piccoli e confini delicati che altrimenti andrebbero persi.
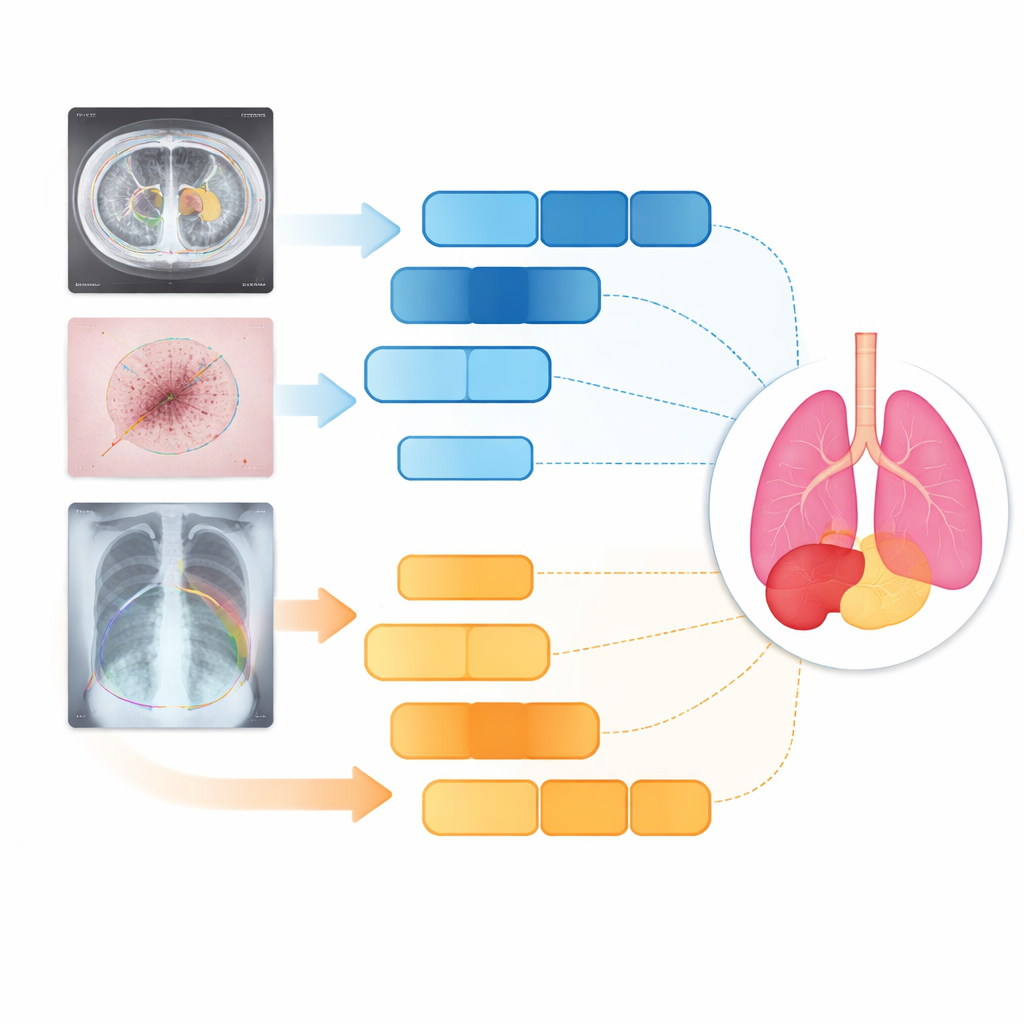
Test su organi, pelle e polmoni
I ricercatori hanno testato D3T-Net su tre compiti medici molto diversi: delineare organi addominali su scansioni TC, tracciare lesioni cutanee in fotografie cliniche e segmentare i polmoni nelle radiografie del torace. Sulle misure standard di accuratezza e nitidezza dei bordi, D3T-Net ha superato costantemente una vasta serie di sistemi allo stato dell’arte, incluse varianti note di U-Net e ibridi basati su Transformer. È stato particolarmente efficace nel mantenere continui i contorni degli organi, separare correttamente strutture adiacenti e catturare obiettivi piccoli o a basso contrasto come la cistifellea o lesioni cutanee irregolari. Importante: questi miglioramenti non sono arrivati con un aumento estremo del tempo di calcolo: il costo di elaborazione del modello è rimasto comparabile a molte reti ampiamente usate, rendendone plausibile l’adozione clinica.
Cosa significa per pazienti e clinici
In termini semplici, lo studio mostra che permettere a un algoritmo di “pensare” sia localmente sia globalmente allo stesso tempo porta a contorni più puliti di organi e patologie nelle immagini mediche. Coordinando con cura un ramo orientato al dettaglio con uno attento al contesto, D3T-Net può separare tessuto sano e malato più accuratamente rispetto a molti strumenti esistenti. Pur non sostituendo i radiologi, può servire come potente assistente—pre-segmentando automaticamente le scansioni, segnalando lesioni sottili e fornendo maschere più affidabili per compiti a valle come la pianificazione 3D o il monitoraggio del trattamento. Man mano che design a doppia visuale simili verranno applicati ad altri problemi d’imaging, i pazienti potrebbero beneficiare di cure più rapide, più coerenti e più personalizzate.
Citazione: Li, D., Yuan, C., Yao, Y. et al. Dual-branch attention network with deep split convolution and multi-dimensional transformers for medical image segmentation. Sci Rep 16, 14238 (2026). https://doi.org/10.1038/s41598-026-44413-8
Parole chiave: segmentazione di immagini mediche, apprendimento profondo, reti transformer, analisi del fegato e degli organi, diagnosi assistita dal computer