Clear Sky Science · ru
Сеть с двойной ветвью внимания, глубокой раздельной сверткой и многомерными трансформерами для сегментации медицинских изображений
Более четкие изображения для врачей
Современные сканирования способны выявлять опухоли, закупоренные сосуды и поврежденные органы в поразительной детализации, но перевод этих серо‑белых изображений в четкие контуры, понятные компьютеру, по-прежнему непростая задача. Врачам нужны точные границы органов и пораженной ткани для планирования операций, мониторинга лечения и предотвращения ошибок. В этой работе представлен новый искусственный интеллект под названием D3T-Net, который проводит такие границы точнее и надежнее многих ведущих методов, что потенциально снижает нагрузку на радиологов и повышает уверенность в диагнозе.
Почему проведение линий по медицинским снимкам так сложно
Когда радиолог смотрит на КТ или рентгеновский снимок, он мысленно разделяет перекрывающиеся структуры, отбрасывает шум и восполняет недостающие края. Традиционные компьютерные методы с этим справляются плохо, особенно когда форма органов варьируется у разных людей или граница опухоли размыта. Ранние системы на основе сверточных нейронных сетей хорошо улавливали локальные текстуры и края, но обычно анализировали лишь небольшое окружение. Это заставляло их терять более широкий контекст, необходимый, например, чтобы отличить слабую границу опухоли от нормальной ткани. С другой стороны, более новые модели «трансформеры» умеют захватывать дальние взаимосвязи по всему изображению, но часто упускают мелкие детали, такие как крошечные очаги или тонкие границы.
Два дополняющих взгляда
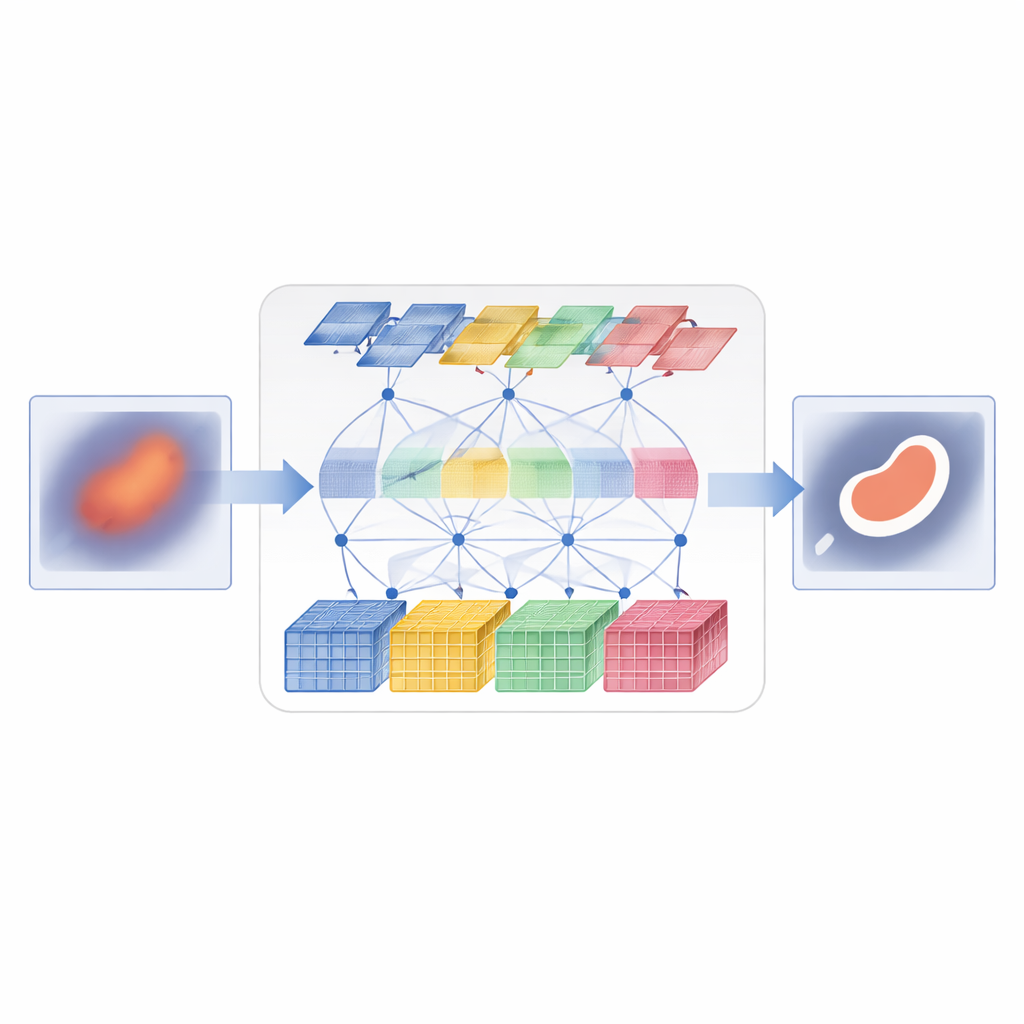
D3T-Net решает эту задачу, объединяя оба подхода в одной, плотно согласованной сети. Одна ветвь действует как традиционный анализатор изображения, фокусируясь на небольших патчах, чтобы уловить тонкие текстуры и четкие края. Она использует стратегию «глубокого разбиения»: входные признаки изображения разделяются на несколько параллельных потоков, обрабатываются отдельно, а затем объединяются с помощью механизма внимания, который решает, какие потоки несут наиболее полезную структурную информацию. Другая ветвь выполняет роль глобального наблюдателя, применяя внимание в стиле трансформера для сравнения удаленных участков изображения и понимания взаимосвязей между регионами. Она смотрит не только по плоскости изображения, но и по каналам признаков, что позволяет уловить, где находятся объекты и как согласованы их паттерны внешности.
Как заставить обе ветви сотрудничать
Просто запуск двух ветвей параллельно недостаточен — они должны обмениваться информацией разумным образом. В энкодере D3T-Net специальный модуль взаимодействия анализирует паттерны в нескольких направлениях по изображению, используя пулинг и внимание, чтобы выделить наиболее информативные структуры — такие как контуры органов или ядра очагов — и поделиться этим акцентом между локальной и глобальной ветвями. В декодере, где собирается итоговая карта сегментации, механизм кросс‑внимания учится комбинировать знания каждой ветви, реорганизуя признаки так, чтобы глобальный контекст уточнял локальные края, а локальные детали дорабатывали общую картину. Многоуровневые пропускные связи передают информацию с ранних этапов высокого разрешения прямо на более поздние стадии, помогая системе отслеживать мелкие объекты и тонкие границы, которые иначе могли бы потеряться.
Тестирование на органах, коже и легких
Исследователи протестировали D3T-Net на трех существенно разных медицинских задачах: выделение органов брюшной полости на КТ, трассировка кожных поражений на клинических фотографиях и сегментация легких на рентгеновских снимках грудной клетки. По стандартным метрикам точности и четкости границ D3T-Net последовательно превосходил широкий круг современных систем, включая известные варианты U‑Net и гибриды на основе трансформеров. Особенно хорошо он справлялся с сохранением непрерывности контуров органов, корректным разделением соседних структур и захватом небольших или низкоконтрастных целей, таких как желчный пузырь или нерегулярные кожные поражения. Важно, что эти улучшения достигались без резкого роста вычислительных затрат: стоимость обработки модели оставалась сопоставимой со многими широко используемыми сетями, что делает ее реалистичным кандидатом для клинического применения.
Что это значит для пациентов и клиницистов
Проще говоря, исследование показывает, что позволить алгоритму «думать» одновременно локально и глобально приводит к более чистым контурам органов и патологии на медицинских изображениях. Тщательно координируя ветвь, ориентированную на детали, с ветвью, учитывающей контекст, D3T-Net может точнее разделять здоровую и пораженную ткань, чем многие существующие инструменты. Хотя он не заменит радиологов, он может стать мощным помощником — автоматически предварительно сегментируя снимки, отмечая тонкие поражения и предоставляя более надежные маски для последующих задач, таких как 3D‑планирование или мониторинг лечения. По мере того как подобные конструкции с двумя взглядами будут применяться к другим задачам визуализации, пациенты могут выиграть от более быстрого, более стабильного и более персонализированного ухода.
Цитирование: Li, D., Yuan, C., Yao, Y. et al. Dual-branch attention network with deep split convolution and multi-dimensional transformers for medical image segmentation. Sci Rep 16, 14238 (2026). https://doi.org/10.1038/s41598-026-44413-8
Ключевые слова: сегментация медицинских изображений, глубокое обучение, сети трансформеров, анализ печени и органов, компьютерная поддержка диагностики