Clear Sky Science · pl
Sieć uwagi z dwiema gałęziami z głęboką konwolucją rozdzielającą i wielowymiarowymi transformatorami do segmentacji obrazów medycznych
Wyraźniejsze obrazy dla lekarzy
Współczesne skany potrafią ujawnić guzy, zatkane naczynia i uszkodzone narządy z oszałamiającą szczegółowością, ale przekształcenie tych szaro‑białych obrazów w wyraźne kontury zrozumiałe dla komputera wciąż bywa zaskakująco trudne. Lekarze potrzebują precyzyjnych granic wokół narządów i tkanek chorobowych, aby planować operacje, śledzić leczenie i unikać błędów. W badaniu zaprezentowano nowy system sztucznej inteligencji, nazwany D3T‑Net, który wyznacza te granice dokładniej i bardziej niezawodnie niż wiele czołowych metod, co może odciążyć radiologów i zwiększyć pewność diagnostyczną.
Dlaczego rysowanie linii na skanach medycznych jest takie trudne
Kiedy radiolog ogląda obraz CT lub rentgenowski, mentalnie oddziela nakładające się struktury, ignoruje szumy i wnioskuje brakujące krawędzie. Tradycyjne programy komputerowe mają z tym kłopot, szczególnie gdy kształty narządów różnią się między pacjentami lub gdy granica guza jest rozmyta. Wcześniejsze systemy oparte na sieciach konwolucyjnych świetnie rozpoznawały lokalne tekstury i krawędzie, ale zwykle widziały tylko niewielkie sąsiedztwo. Łatwo więc im było przegapić szerszy kontekst potrzebny do rozróżnienia na przykład słabej krawędzi guza od normalnej tkanki. Z kolei nowsze modele typu Transformer dobrze chwytają zależności na dużą skalę w całym obrazie, lecz często pomijają drobne detale, takie jak małe ogniska czy cienkie granice.
Dwa komplementarne sposoby widzenia
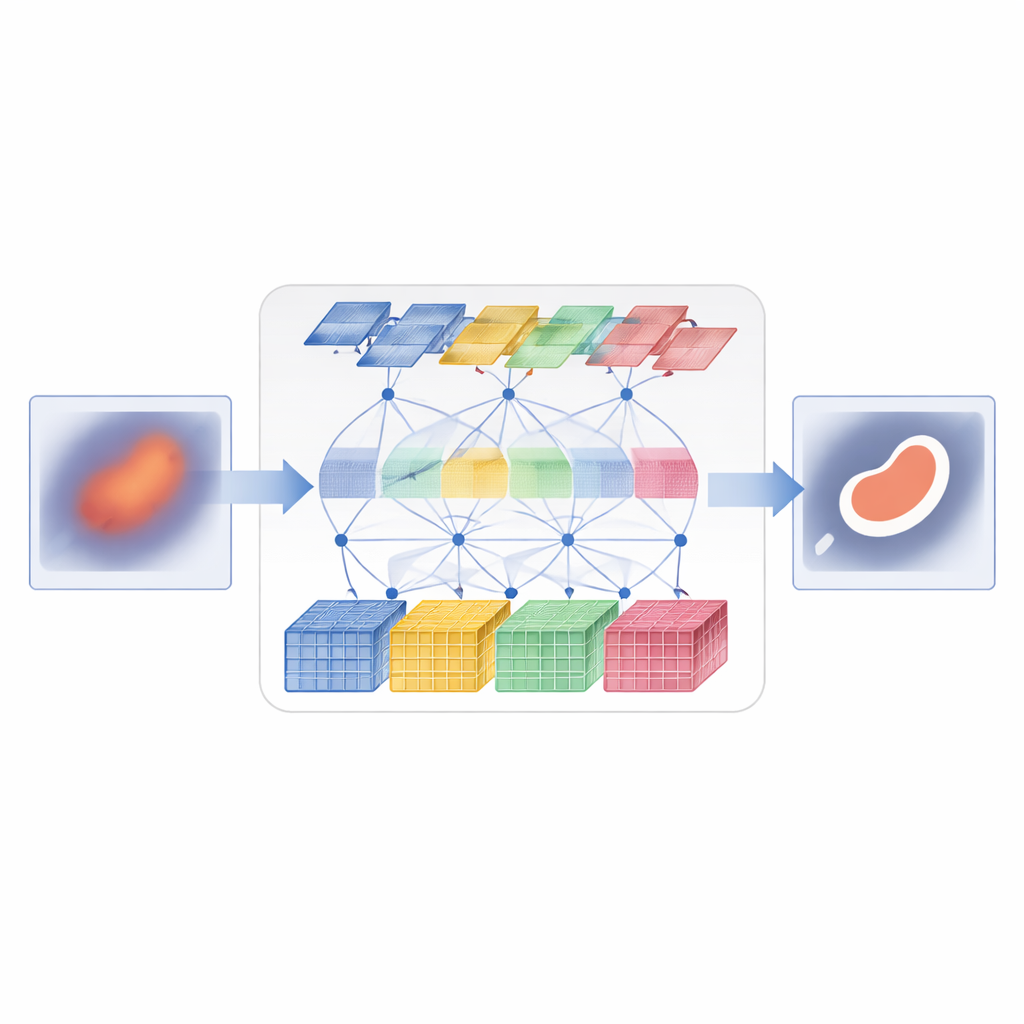
D3T‑Net stawia czoła temu wyzwaniu, łącząc oba sposoby widzenia w jednej, ściśle skoordynowanej sieci. Jedna gałąź zachowuje się jak tradycyjny analizator obrazu, koncentrując się na małych fragmentach, aby uchwycić drobne tekstury i ostre krawędzie. Wykorzystuje strategię „głębokiego rozdzielania”: wejściowe cechy obrazu dzielone są na wiele równoległych strumieni, przetwarzane osobno, a następnie łączone mechanizmem uwagi, który decyduje, które strumienie niosą najbardziej użyteczne informacje strukturalne. Druga gałąź działa bardziej jak obserwator globalny, używając uwagi w stylu Transformera do porównywania odległych części obrazu i rozumienia, jak regiony się ze sobą odnoszą. Ocenia ona nie tylko rozmieszczenie w płaszczyźnie obrazu, lecz także zależności między kanałami cech, co pozwala uchwycić zarówno miejsce występowania struktur, jak i wzorce ich wyglądu.
Jak sprawić, by obie gałęzie współpracowały
Uruchomienie dwóch gałęzi równolegle nie wystarczy; muszą się one wymieniać informacjami w inteligentny sposób. W części enkodera D3T‑Net specjalny moduł interakcji analizuje wzorce w wielu kierunkach na obrazie, używając poolingów i mechanizmów uwagi, aby uwypuklić najbardziej informatywne struktury—takie jak kontury narządów czy jądra zmian—i dzielić to podkreślenie między gałęzią lokalną i globalną. W dekoderze, gdzie składana jest ostateczna mapa segmentacji, mechanizm cross‑attention uczy się łączyć zdobytą przez każdą gałąź wiedzę, reorganizując cechy tak, by kontekst globalny wyostrzał lokalne krawędzie, a lokalne detale dopracowywały szeroką globalną perspektywę. Wieloskalowe połączenia skip carry przekazują informacje z wczesnych, wysokorozdzielczych etapów przetwarzania bezpośrednio do późniejszych, pomagając systemowi śledzić małe obiekty i delikatne granice, które w przeciwnym razie mogłyby zostać utracone.
Testy na narządach, skórze i płucach
Autorzy przetestowali D3T‑Net w trzech bardzo różnych zadaniach medycznych: wyznaczaniu konturów narządów brzusznych na skanach CT, obrysowywaniu zmian skórnych na zdjęciach klinicznych oraz segmentacji płuc na prześwietleniach klatki piersiowej. W standardowych miarach dokładności i ostrości granic D3T‑Net konsekwentnie przewyższał szerokie spektrum najnowocześniejszych systemów, w tym znane warianty U‑Net i hybrydy oparte na Transformerach. Szczególnie dobrze radził sobie z utrzymywaniem ciągłości konturów narządów, poprawnym oddzielaniem sąsiednich struktur oraz wychwytywaniem małych lub o niskim kontraście celów, takich jak pęcherzyk żółciowy czy nieregularne zmiany skórne. Co ważne, te korzyści osiągnięto bez ekstremalnego wzrostu kosztu obliczeniowego: koszty przetwarzania modelu pozostały porównywalne z wieloma powszechnie używanymi sieciami, co czyni go realnym do wdrożenia klinicznego.
Co to oznacza dla pacjentów i klinicystów
Mówiąc wprost, badanie pokazuje, że pozwolenie algorytmowi „myśleć” jednocześnie lokalnie i globalnie daje czyściejsze kontury narządów i schorzeń na obrazach medycznych. Dzięki starannej koordynacji gałęzi zorientowanej na detale i gałęzi świadomej kontekstu, D3T‑Net potrafi dokładniej odróżnić tkankę zdrową od chorobowej niż wiele istniejących narzędzi. Choć nie zastąpi radiologów, może służyć jako potężny asystent—automatycznie wstępnie segmentując skany, oznaczając subtelne zmiany i dostarczając bardziej wiarygodne maski do zadań dalszych, takich jak planowanie 3D czy monitorowanie leczenia. W miarę zastosowań podobnych konstrukcji z podwójnym widzeniem w innych problemach obrazowania, pacjenci mogą zyskać szybszą, bardziej spójną i bardziej spersonalizowaną opiekę.
Cytowanie: Li, D., Yuan, C., Yao, Y. et al. Dual-branch attention network with deep split convolution and multi-dimensional transformers for medical image segmentation. Sci Rep 16, 14238 (2026). https://doi.org/10.1038/s41598-026-44413-8
Słowa kluczowe: segmentacja obrazów medycznych, uczenie głębokie, sieci Transformer, analiza wątroby i narządów, komputerowo wspomagana diagnostyka