Clear Sky Science · sv
Generativa adversariella nätverk och hyperparameter‑optimerad XGBoost för förbättrad prognos av hjärtsjukdom
Varför tidiga varningar om hjärtproblem spelar roll
Hjärtsjukdom är fortfarande världens största dödsorsak, men det mesta av skadan byggs upp tyst under många år. Läkare samlar redan in stora mängder hälsodata — från ålder och blodtryck till sömn‑ och träningsvanor — men att omvandla dessa röriga, ofullständiga uppgifter till tillförlitliga tidiga varningar är svårt. Denna artikel presenterar ett nytt datorbaserat tillvägagångssätt, kallat GAN‑XO, utformat för att sålla genom stora hälsoundersökningar och identifiera vilka som löper hög risk för hjärtsjukdom med anmärkningsvärd noggrannhet, samtidigt som det gör sina beslut tydligare och mer tillförlitliga för kliniker.
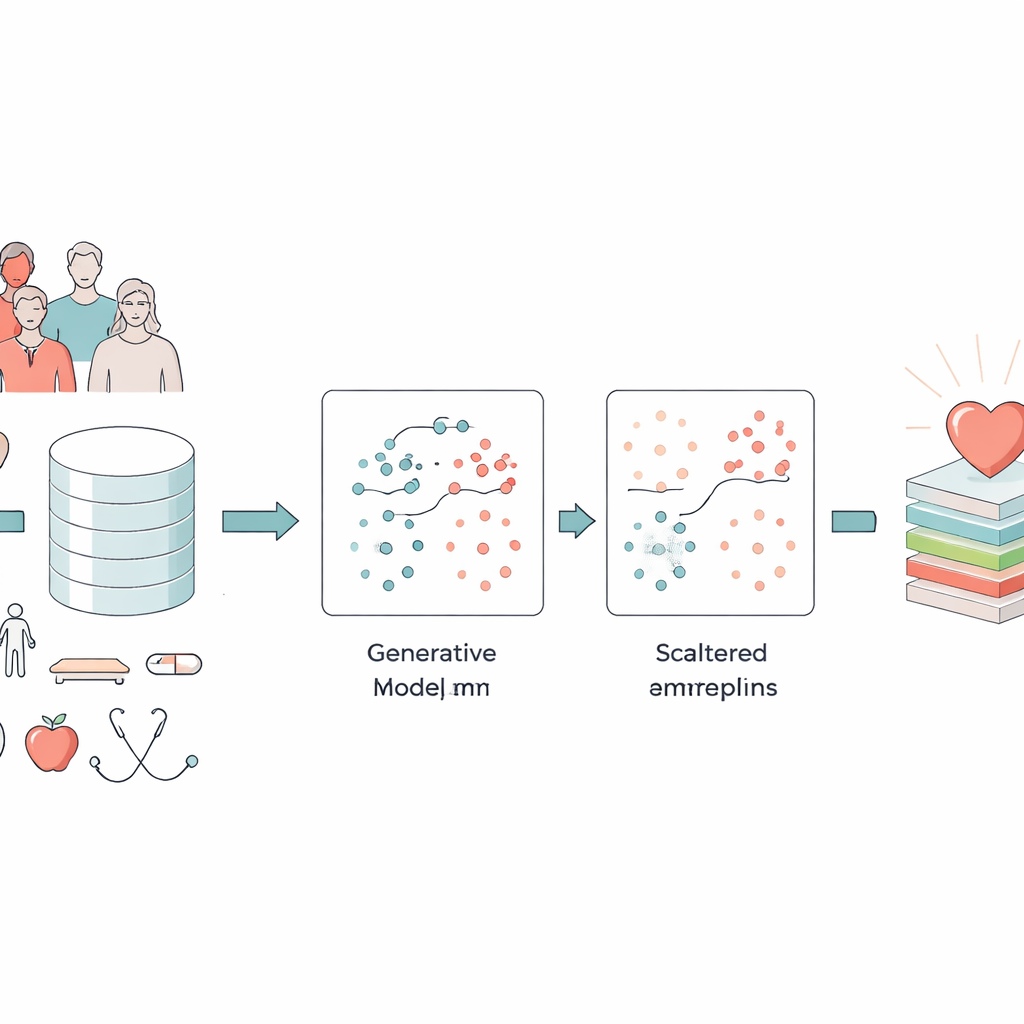
Att omvandla röriga hälsodata till något användbart
Forskarna koncentrerade sig på två stora datamängder: en massiv amerikansk undersökning med mer än 300 000 vuxna och den långvariga Framingham Heart Study. Dessa samlingar blandar enkla uppgifter som ålder, kön och rökning med kliniska mått såsom kroppsmassaindex, blodtryck, blodsocker samt självrapporterad fysisk och psykisk hälsa. En central utmaning är att endast en liten andel av personerna i sådana dataset faktiskt har hjärtsjukdom. Standardmodeller tenderar att lära sig det ”lätta” mönstret — att de flesta är friska — och förbiser den mycket mindre men avgörande gruppen som är sjuka. Utöver det innehåller undersökningar och journaler fel, extrema mätvärden och saknade uppgifter som kan förvirra även de bästa algoritmerna.
Att lära en maskin föreställa sig realistiska patienter
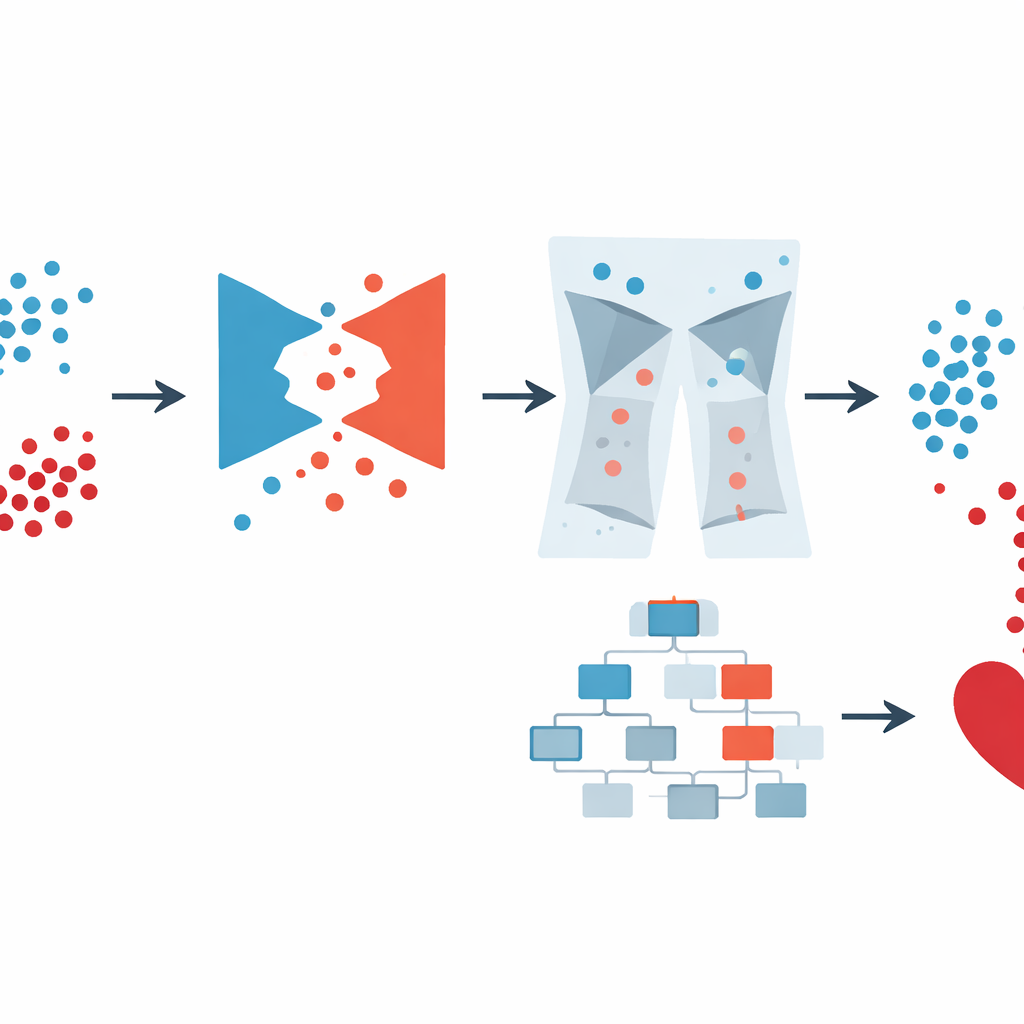
För att ta itu med obalansen vände teamet sig till en typ av artificiell intelligens som kallas Generative Adversarial Network (GAN). Istället för att bara kopiera eller blanda befintliga poster lär sig en GAN att skapa helt nya, realistiska ”syntetiska” patienter som liknar dem med hjärtsjukdom. Den specifika utformningen, en villkorad GAN, får information om vilken klass den ska efterlikna (sjuk eller inte sjuk), så att den medvetet kan generera fler trovärdiga hög‑riskexempel. Författarna kontrollerade att dessa syntetiska patienter bevarade viktiga samband — såsom kopplingen mellan ålder och blodtryck eller diabetes och blodsocker — i stället för att uppfinna omöjliga kombinationer. Detta steg berikade avsevärt den data som fanns tillgänglig för prediktionsmodellen utan att kräva att kliniker samlade in fler verkliga prover.
Rensa bort dåliga data innan prognoser görs
Syntetiska data kan dock också introducera märkligheter, såsom biologiskt omöjliga kroppsvikter eller motsägelsefulla hälsoprofiler. Verkliga undersökningar och journaler lider av liknande problem. GAN‑XO‑ramverket lägger därför till ett ovanligt strikt rengöringssteg. Genom att använda två standardstatistiska verktyg — z‑poäng och interkvartilavstånd — flaggas och tas bort värden som ligger långt utanför medicinskt rimliga intervall för mätningar som kroppsmassaindex, antal dagar med dålig hälsa per månad, sömntid, blodtryck och glukosnivåer. Avgörande var att författarna kontrollerade att denna process inte gynnade borttagning av personer med hjärtsjukdom; andelen sjuka och friska som togs bort förblev nästan densamma som i ursprungsdata. Resultatet blev en mindre men mycket mer pålitlig samling poster att träna på.
Kombinera smart datahantering med en kraftfull prediktor
När data var balanserade och rengjorda använde författarna XGBoost, en populär maskininlärningsmetod som bygger en ensemble av beslutsträd, för den slutliga prediktionen. I stället för att handinställa dess många parametrar använde de Optuna, ett automatiserat söksystem som testar olika kombinationer av modellinställningar och behåller dem som förbättrar prestanda. De jämförde flera varianter: ren XGBoost, XGBoost med enklare balanseringsmetoder och hela GAN‑XO‑pipen med och utan avvikarsrensning. På den stora amerikanska undersökningen uppnådde det kompletta GAN‑XO‑systemet omkring 96,6 % noggrannhet och en liknande hög F1‑poäng, vilket överträffade tidigare publicerade metoder. Lika viktigt var att borttagandet av avvikare minskade gapet mellan träning och testning, vilket visar att modellen lärde sig genuina mönster snarare än att memorera brus.
Göra svartlådeförutsägelser mer begripliga
Där medicinska beslut måste vara förklarliga undersökte författarna också hur modellen kom fram till sina slutsatser. De använde två populära tolkningsverktyg, SHAP och LIME, för att visa vilka faktorer som starkast drev prediktioner mot ”hjärtsjukdom” eller ”ingen hjärtsjukdom” för både patientgrupper och enskilda fall. När modellen tränades på data som fortfarande innehöll avvikare var förklaringarna instabila och lutade ibland mot udda kombinationer av egenskaper. Efter rengöring blev betydelsen av välkända riskfaktorer — såsom ålder, allmän hälsa, kroppsvikt, rökning och tidigare stroke eller diabetes — tydligare och mer konsekvent. Det gav en starkare känsla av att modellens resonemang stämde överens med klinisk förståelse, inte bara statistiska tillfälligheter.
Vad detta betyder för patienter och läkare
Enkelt uttryckt visar denna studie att bättre prognoser för hjärtsjukdom lika mycket beror på noggrann datahantering som på sofistikerade algoritmer. Genom att först lära en AI att ”föreställa sig” ytterligare realistiska hög‑riskpatienter, sedan aggressivt filtrera bort osannolika poster och slutligen finjustera en kraftfull prediktionsmotor levererar GAN‑XO‑ramverket både hög noggrannhet och mer tolkbara resultat. För patienter kan det innebära tidigare och mer tillförlitliga varningar baserat på rutinmässig hälsoinformation; för kliniker erbjuder det ett verktyg vars val i större utsträckning speglar verklig medicinsk logik. Författarna menar att denna blandning av datakvalitetskontroll, smart syntes och transparent prediktion är en lovande mall för framtida AI‑system inom vården.
Citering: Begum, S.S., Swamy, A., Dhanka, S. et al. Generative adversarial networks and hyperparameter-optimized XGBoost for enhanced heart disease prediction. Sci Rep 16, 11326 (2026). https://doi.org/10.1038/s41598-026-40322-y
Nyckelord: prediktion av hjärtsjukdom, medicinsk maskininlärning, syntetiska hälsodata, datakvalitet och avvikare, XGBoost‑modellering