Clear Sky Science · es
Redes generativas antagónicas y XGBoost optimizado por hiperparámetros para mejorar la predicción de enfermedades cardíacas
Por qué importan las alertas tempranas cardíacas
La enfermedad cardíaca sigue siendo la principal causa de muerte en el mundo, pero la mayor parte del daño se acumula silenciosamente durante años. Los médicos ya recogen enormes cantidades de información de salud —desde la edad y la presión arterial hasta hábitos de sueño y ejercicio—, pero convertir esos datos desordenados e imperfectos en alertas tempranas fiables es difícil. Este artículo presenta un nuevo enfoque informático, llamado GAN-XO, diseñado para tamizar grandes encuestas de salud y detectar quién tiene alto riesgo de enfermedad cardíaca con notable precisión, al tiempo que hace sus decisiones más claras y confiables para los clínicos.
Convertir datos sanitarios desordenados en algo útil
Los investigadores se centraron en dos grandes conjuntos de datos: una enorme encuesta estadounidense de más de 300.000 adultos y el prolongado Estudio del Corazón de Framingham. Estas colecciones mezclan detalles sencillos como edad, sexo y tabaquismo con medidas clínicas como índice de masa corporal, presión arterial, glucemia y salud física y mental autoinformada. Un desafío central es que solo una pequeña fracción de las personas en estos conjuntos realmente tiene enfermedad cardíaca. Los modelos informáticos estándar tienden a aprender el patrón “fácil”, es decir, que la mayoría está sana, y pasan por alto el grupo mucho menor pero crucial que está enfermo. Además, las encuestas y los registros médicos contienen errores, mediciones extremas y datos faltantes que pueden confundir incluso a los mejores algoritmos.
Enseñar a una máquina a imaginar pacientes realistas
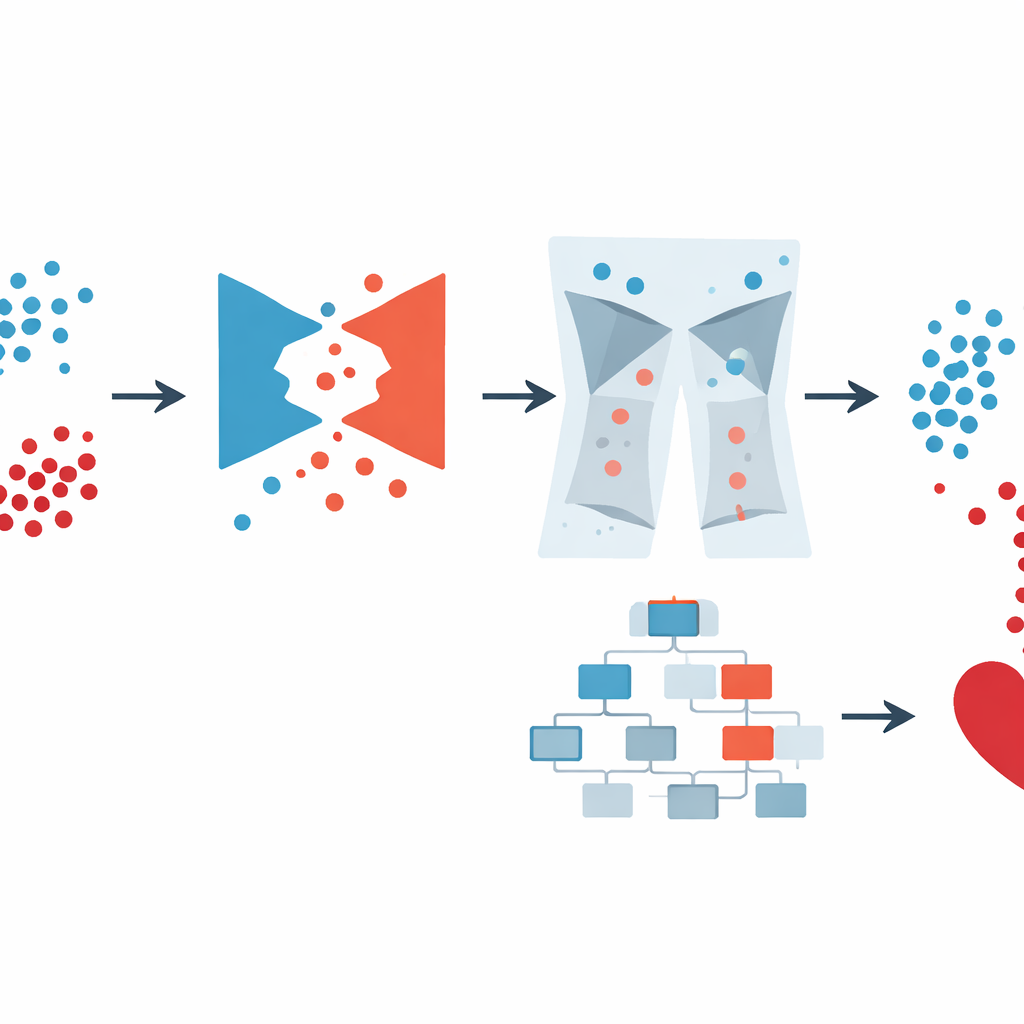
Para abordar el problema de desequilibrio, el equipo recurrió a un tipo de inteligencia artificial conocido como Red Generativa Antagónica (GAN). En lugar de copiar o mezclar registros existentes, una GAN aprende a crear nuevos «pacientes sintéticos» realistas que se parecen a los que tienen enfermedad cardíaca. El diseño específico, una GAN condicional, recibe información sobre la clase que debe imitar (enfermedad o no enfermedad), de modo que puede generar deliberadamente ejemplos de alto riesgo más verosímiles. Los autores verificaron que estos pacientes sintéticos preservaban relaciones importantes —como el vínculo entre edad y presión arterial o entre diabetes y glucemia— en lugar de inventar combinaciones imposibles. Este paso enriqueció en gran medida los datos disponibles para el modelo de predicción sin exigir a los clínicos recopilar más muestras del mundo real.
Eliminar datos erróneos antes de hacer predicciones
No obstante, los datos sintéticos también pueden introducir rarezas, como pesos corporales biológicamente imposibles o perfiles de salud contradictorios. Las encuestas reales y los registros hospitalarios sufren problemas similares. Por ello, el marco GAN-XO añade una etapa de limpieza de datos excepcionalmente estricta. Usando dos herramientas estadísticas estándar —la puntuación z (z-score) y el rango intercuartílico— marca y elimina valores que están muy fuera de los rangos médicamente razonables para medidas como índice de masa corporal, días de mala salud en un mes, tiempo de sueño, presión arterial y niveles de glucosa. De forma crucial, los autores comprobaron que este proceso no eliminó preferentemente a las personas con enfermedad cardíaca; la proporción de individuos enfermos y sanos eliminados se mantuvo casi igual que en los datos originales. El resultado es una colección más pequeña pero mucho más fiable de registros sobre la que entrenar.
Combinar datos inteligentes y un predictor potente
Una vez que los datos estuvieron equilibrados y limpiados, los autores usaron XGBoost, un método de aprendizaje automático popular que construye un ensamblaje de árboles de decisión, para realizar la predicción final. En lugar de ajustar manualmente sus numerosos parámetros, confiaron en Optuna, un sistema de búsqueda automatizado que prueba distintas combinaciones de hiperparámetros y conserva las que mejoran el rendimiento. Compararon varias versiones: XGBoost básico, XGBoost con métodos de balanceo más simples y la canalización completa GAN-XO con y sin eliminación de valores atípicos. En la gran encuesta estadounidense, el sistema completo GAN-XO alcanzó alrededor de un 96,6 % de precisión y una puntuación F1 igualmente alta, superando a métodos publicados anteriormente. Igualmente importante, eliminar los valores atípicos redujo la brecha entre los resultados de entrenamiento y prueba, lo que muestra que el modelo aprendía patrones genuinos en lugar de memorizar ruido.
Hacer las predicciones de caja negra más comprensibles
Dado que las decisiones médicas deben ser explicables, los autores también examinaron cómo el modelo llegaba a sus conclusiones. Utilizaron dos herramientas populares de interpretación, SHAP y LIME, para mostrar qué factores impulsaban con mayor fuerza las predicciones hacia «enfermedad cardíaca» o «sin enfermedad cardíaca» tanto para grupos de pacientes como para casos individuales. Cuando se entrenó con datos que aún contenían valores atípicos, las explicaciones del modelo eran inestables y, a veces, se apoyaban en combinaciones extrañas de rasgos. Tras la limpieza, la importancia de factores de riesgo familiares —como la edad, la salud general, el peso corporal, el tabaquismo y antecedentes de ictus o diabetes— se volvió más clara y consistente. Esto dio una mayor sensación de que el razonamiento del modelo coincidía con la comprensión clínica, no solo con rarezas estadísticas.
Qué significa esto para pacientes y médicos
En términos sencillos, este estudio muestra que una mejor predicción de enfermedades cardíacas depende tanto del manejo cuidadoso de los datos como de algoritmos sofisticados. Primero enseñando a un sistema de IA a «imaginar» pacientes adicionales realistas de alto riesgo, luego filtrando agresivamente los registros implausibles y, finalmente, ajustando un potente motor predictivo, el marco GAN-XO ofrece tanto alta precisión como resultados más interpretables. Para los pacientes, eso podría traducirse en advertencias más tempranas y fiables basadas en información sanitaria de rutina; para los clínicos, ofrece una herramienta cuyas decisiones reflejan mejor la lógica médica real. Los autores sostienen que esta combinación de control de calidad de datos, síntesis inteligente y predicción transparente es un plano prometedor para futuros sistemas de IA en atención sanitaria.
Cita: Begum, S.S., Swamy, A., Dhanka, S. et al. Generative adversarial networks and hyperparameter-optimized XGBoost for enhanced heart disease prediction. Sci Rep 16, 11326 (2026). https://doi.org/10.1038/s41598-026-40322-y
Palabras clave: predicción de enfermedades cardíacas, aprendizaje automático médico, datos sanitarios sintéticos, calidad de datos y valores atípicos, modelado XGBoost