Clear Sky Science · fr
Réseaux antagonistes génératifs et XGBoost optimisé par hyperparamètres pour une meilleure prédiction des maladies cardiaques
Pourquoi les alertes précoces pour le cœur sont importantes
Les maladies cardiaques restent la première cause de décès dans le monde, pourtant la plupart des lésions se développent silencieusement sur des années. Les médecins recueillent déjà d’importantes quantités d’informations de santé — de l’âge et la tension artérielle aux habitudes de sommeil et d’exercice — mais transformer ces données désordonnées et imparfaites en alertes précoces fiables est difficile. Cet article présente une nouvelle approche informatique, baptisée GAN-XO, conçue pour analyser de larges enquêtes de santé et identifier avec une précision remarquable les personnes à haut risque de maladie cardiaque, tout en rendant ses décisions plus claires et plus fiables pour les cliniciens.
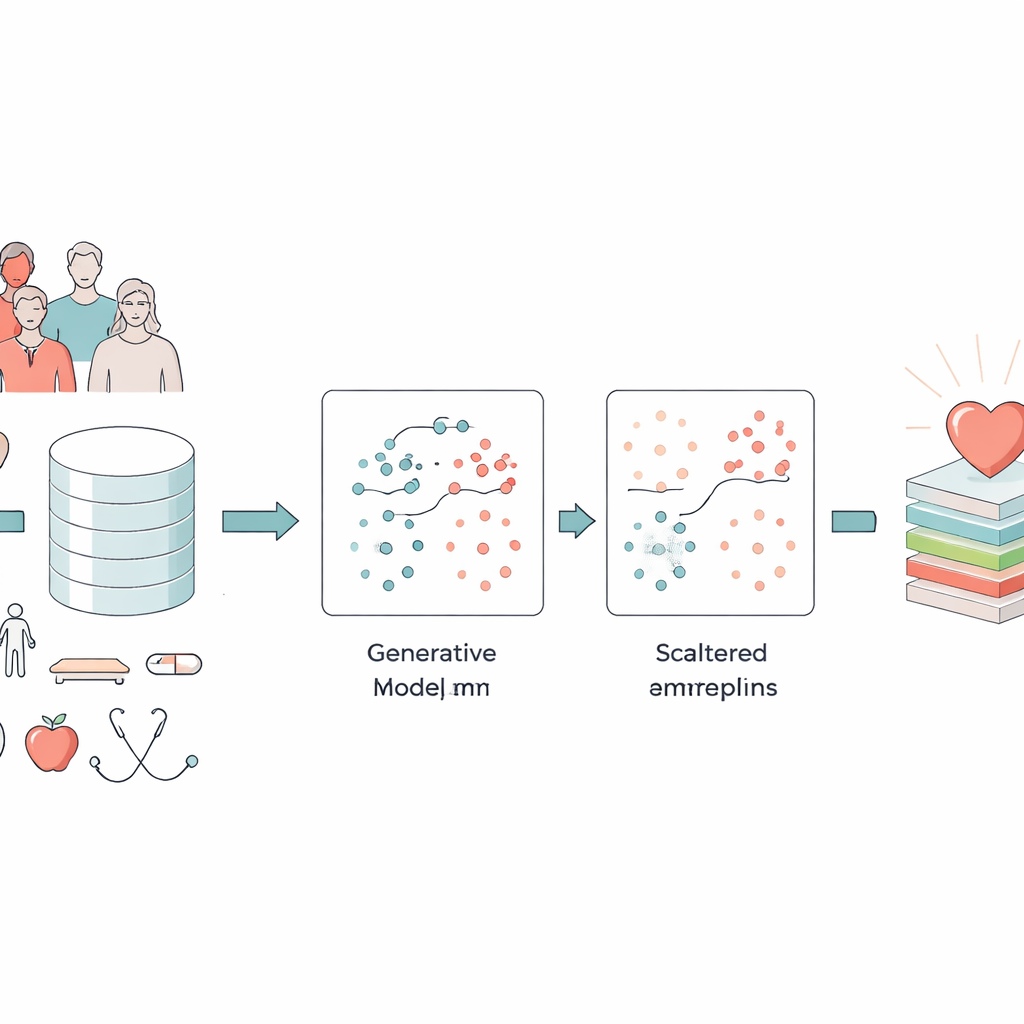
Transformer des données de santé désordonnées en ressources utiles
Les chercheurs se sont concentrés sur deux jeux de données majeurs : une vaste enquête américaine de plus de 300 000 adultes et la longue étude de Framingham sur le cœur. Ces ensembles mélangent des informations simples comme l’âge, le sexe et le tabagisme avec des mesures cliniques telles que l’indice de masse corporelle, la tension artérielle, la glycémie et l’auto-évaluation de la santé physique et mentale. Un défi central est que seule une petite fraction des personnes présentes dans ces jeux de données souffre réellement de maladie cardiaque. Les modèles informatiques standard apprennent souvent le schéma « facile » — que la plupart des gens sont en bonne santé — et négligent le groupe beaucoup plus restreint mais crucial des malades. De plus, les enquêtes et dossiers médicaux contiennent des erreurs, des mesures extrêmes et des données manquantes qui peuvent embrouiller même les meilleurs algorithmes.
Apprendre à une machine à imaginer des patients réalistes
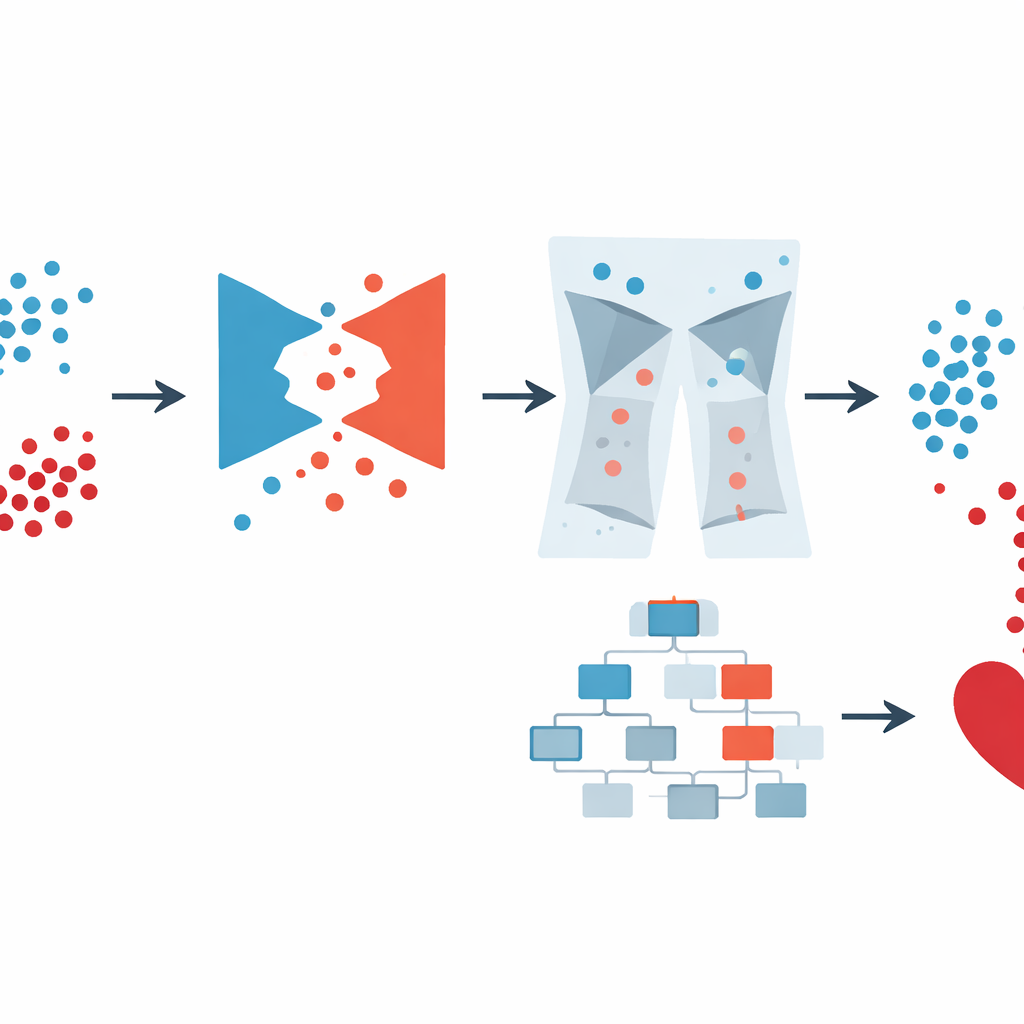
Pour traiter le problème de déséquilibre, l’équipe a eu recours à un type d’intelligence artificielle appelé réseau antagoniste génératif (GAN). Plutôt que de simplement copier ou mélanger des dossiers existants, un GAN apprend à créer de nouveaux « patients » synthétiques réalistes qui ressemblent à ceux souffrant de maladie cardiaque. La conception spécifique, un GAN conditionnel, reçoit l’information sur la classe qu’il doit reproduire (malade ou non), ce qui lui permet de générer délibérément davantage d’exemples crédibles à haut risque. Les auteurs ont vérifié que ces patients synthétiques préservaient des relations importantes — comme le lien entre âge et tension artérielle ou entre diabète et glycémie — plutôt que d’inventer des combinaisons impossibles. Cette étape a considérablement enrichi les données disponibles pour le modèle de prédiction sans demander aux cliniciens de collecter davantage d’échantillons réels.
Éliminer les mauvaises données avant de prédire
Toutefois, les données synthétiques peuvent aussi introduire des anomalies, comme des poids corporels biologiquement impossibles ou des profils de santé contradictoires. Les enquêtes réelles et les dossiers hospitaliers présentent des problèmes similaires. Le cadre GAN-XO ajoute donc une étape de nettoyage des données particulièrement rigoureuse. En utilisant deux outils statistiques standard — le score z et l’étendue interquartile — il signale et supprime les valeurs se situant très en dehors des plages médicalement raisonnables pour des mesures telles que l’indice de masse corporelle, les jours de mauvaise santé par mois, le temps de sommeil, la tension artérielle et les niveaux de glucose. De manière cruciale, les auteurs ont vérifié que ce processus n’éliminait pas préférentiellement les personnes atteintes de maladie cardiaque ; la proportion de sujets malades et sains supprimés est restée presque identique à celle des données d’origine. Le résultat est une collection de dossiers plus petite mais beaucoup plus fiable sur laquelle entraîner le modèle.
Combiner des données intelligentes et un prédicteur puissant
Une fois les données équilibrées et nettoyées, les auteurs ont utilisé XGBoost, une méthode d’apprentissage automatique populaire qui construit un ensemble d’arbres de décision, pour effectuer la prédiction finale. Plutôt que d’ajuster manuellement ses nombreux paramètres, ils se sont appuyés sur Optuna, un système de recherche automatisé qui essaie différentes combinaisons de paramètres et retient celles qui améliorent les performances. Ils ont comparé plusieurs versions : XGBoost simple, XGBoost avec des méthodes d’équilibrage plus simples, et le pipeline complet GAN-XO avec et sans suppression des valeurs aberrantes. Sur la grande enquête américaine, le système GAN-XO complet a atteint environ 96,6 % de précision et un score F1 également élevé, surpassant des méthodes publiées antérieurement. Tout aussi important, la suppression des valeurs aberrantes a resserré l’écart entre les résultats d’entraînement et de test, montrant que le modèle apprenait des schémas réels plutôt que de mémoriser du bruit.
Rendre les prédictions de la boîte noire plus compréhensibles
Parce que les décisions médicales doivent être explicables, les auteurs ont également examiné comment le modèle parvenait à ses conclusions. Ils ont utilisé deux outils d’interprétation populaires, SHAP et LIME, pour montrer quels facteurs poussaient le plus les prédictions vers « maladie cardiaque » ou « pas de maladie cardiaque » pour des groupes de patients et des cas individuels. Lorsqu’il était entraîné sur des données contenant encore des valeurs aberrantes, les explications du modèle étaient instables et s’appuyaient parfois sur des combinaisons de caractéristiques étranges. Après le nettoyage, l’importance de facteurs de risque familiers — tels que l’âge, l’état de santé général, le poids corporel, le tabagisme et les antécédents d’accident vasculaire cérébral ou de diabète — est devenue plus claire et plus cohérente. Cela a renforcé l’impression que le raisonnement du modèle correspondait à la compréhension clinique, et non à des bizarreries statistiques.
Ce que cela signifie pour les patients et les médecins
En termes simples, cette étude montre que de meilleures prédictions des maladies cardiaques dépendent autant d’une gestion soigneuse des données que d’algorithmes sophistiqués. En apprenant d’abord à un système d’IA à « imaginer » des patients supplémentaires réalistes et à haut risque, puis en filtrant agressivement les dossiers peu plausibles, et enfin en optimisant un moteur de prédiction puissant, le cadre GAN-XO offre à la fois une grande précision et des résultats plus interprétables. Pour les patients, cela pourrait signifier des alertes plus précoces et plus fiables basées sur des informations de santé de routine ; pour les cliniciens, cela fournit un outil dont les choix reflètent mieux la logique médicale réelle. Les auteurs soutiennent que ce mélange de contrôle de la qualité des données, de synthèse intelligente et de prédiction transparente est une feuille de route prometteuse pour les futurs systèmes d’IA en santé.
Citation: Begum, S.S., Swamy, A., Dhanka, S. et al. Generative adversarial networks and hyperparameter-optimized XGBoost for enhanced heart disease prediction. Sci Rep 16, 11326 (2026). https://doi.org/10.1038/s41598-026-40322-y
Mots-clés: prévision des maladies cardiaques, apprentissage automatique médical, données de santé synthétiques, qualité des données et valeurs aberrantes, modélisation XGBoost