Clear Sky Science · en
Generative adversarial networks and hyperparameter-optimized XGBoost for enhanced heart disease prediction
Why early heart warnings matter
Heart disease remains the world’s leading killer, yet most of its damage builds up silently over years. Doctors already collect huge amounts of health information—from age and blood pressure to sleep and exercise habits—but turning this messy, imperfect data into reliable early warnings is difficult. This paper presents a new computer-based approach, called GAN-XO, designed to sift through large health surveys and pick out who is at high risk of heart disease with remarkable accuracy, while also making its decisions clearer and more trustworthy for clinicians.
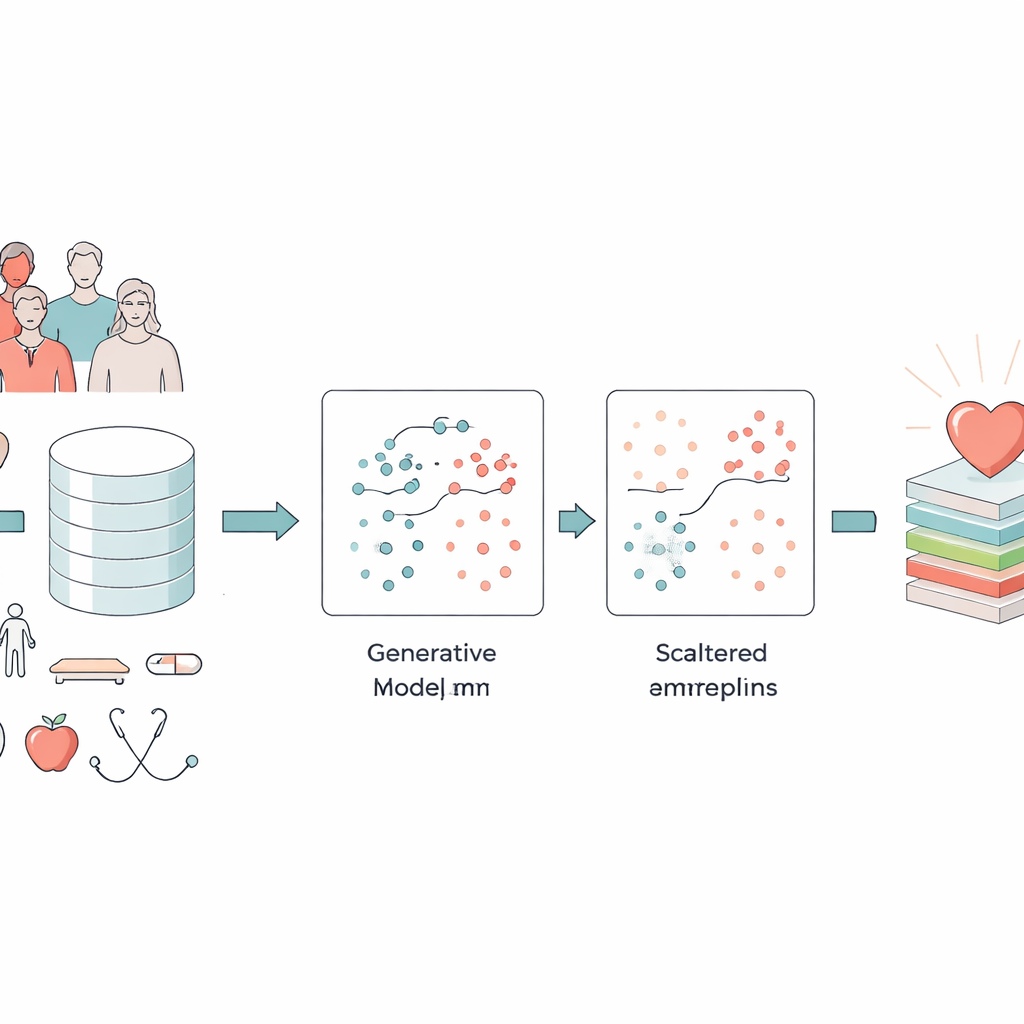
Turning messy health data into something useful
The researchers focused on two major datasets: a massive U.S. survey of more than 300,000 adults, and the long-running Framingham Heart Study. These collections mix simple details like age, sex, and smoking with clinical measures such as body mass index, blood pressure, blood sugar, and self-reported physical and mental health. A central challenge is that only a small fraction of people in such datasets actually have heart disease. Standard computer models tend to learn the “easy” pattern—that most people are healthy—and overlook the much smaller but crucial group who are sick. On top of that, survey and medical records contain errors, extreme measurements, and missing pieces that can confuse even the best algorithms.
Teaching a machine to imagine realistic patients
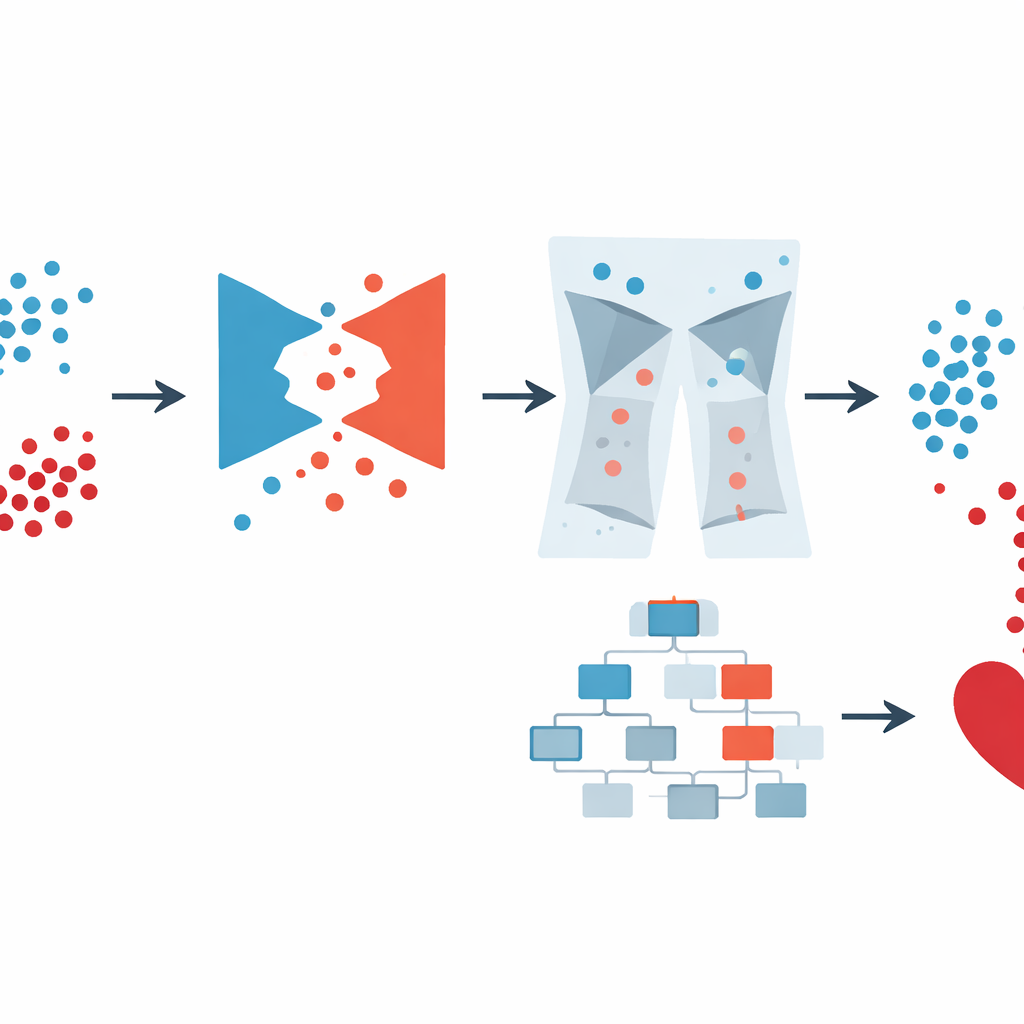
To tackle the imbalance problem, the team turned to a type of artificial intelligence known as a Generative Adversarial Network (GAN). Instead of simply copying or mixing existing records, a GAN learns to create entirely new, realistic “synthetic” patients who resemble those with heart disease. The specific design, a conditional GAN, is told which class it should mimic (disease or no disease), so it can deliberately generate more credible high-risk examples. The authors checked that these synthetic patients preserved important relationships—such as the link between age and blood pressure or diabetes and blood sugar—rather than inventing impossible combinations. This step greatly enriched the data available to the prediction model without asking clinicians to collect more real-world samples.
Cleaning out bad data before making predictions
However, synthetic data can also introduce oddities, such as biologically impossible body weights or contradictory health profiles. Real surveys and hospital records suffer from similar issues. The GAN-XO framework therefore adds an unusually strict data-cleaning stage. Using two standard statistical tools—the z-score and the interquartile range—it flags and removes values that sit far outside medically reasonable ranges for measurements like body mass index, days of poor health in a month, sleep time, blood pressure, and glucose levels. Crucially, the authors checked that this process did not preferentially delete people with heart disease; the proportion of sick and healthy individuals removed stayed almost the same as in the original data. The result is a smaller but much more trustworthy collection of records on which to train.
Combining smart data and a powerful predictor
Once the data were balanced and cleaned, the authors used XGBoost, a popular machine-learning method that builds an ensemble of decision trees, to make the final prediction. Instead of hand-tuning its many settings, they relied on Optuna, an automated search system that tries different combinations of model parameters and keeps those that improve performance. They compared several versions: plain XGBoost, XGBoost with simpler balancing methods, and the full GAN-XO pipeline with and without outlier removal. On the large U.S. survey, the complete GAN-XO system reached about 96.6% accuracy and a similarly high F1-score, outperforming earlier published methods. Just as important, removing outliers tightened the gap between training and testing results, showing that the model was learning genuine patterns rather than memorizing noise.
Making black-box predictions more understandable
Because medical decisions must be explainable, the authors also examined how the model reached its conclusions. They used two popular interpretation tools, SHAP and LIME, to show which factors most strongly pushed predictions toward “heart disease” or “no heart disease” for both groups of patients and individual cases. When trained on data that still contained outliers, the model’s explanations were unstable and sometimes leaned on odd combinations of features. After cleaning, the importance of familiar risk factors—such as age, general health, body weight, smoking, and prior stroke or diabetes—became clearer and more consistent. This gave a stronger sense that the model’s reasoning matched clinical understanding, not just statistical quirks.
What this means for patients and doctors
In simple terms, this study shows that better heart-disease prediction depends as much on careful data handling as on sophisticated algorithms. By first teaching an AI system to “imagine” additional realistic high-risk patients, then aggressively filtering out implausible records, and finally tuning a powerful prediction engine, the GAN-XO framework delivers both high accuracy and more interpretable results. For patients, that could mean earlier and more reliable warnings based on routine health information; for clinicians, it offers a tool whose choices better reflect real medical logic. The authors argue that this blend of data quality control, smart synthesis, and transparent prediction is a promising blueprint for future AI systems in healthcare.
Citation: Begum, S.S., Swamy, A., Dhanka, S. et al. Generative adversarial networks and hyperparameter-optimized XGBoost for enhanced heart disease prediction. Sci Rep 16, 11326 (2026). https://doi.org/10.1038/s41598-026-40322-y
Keywords: heart disease prediction, medical machine learning, synthetic health data, data quality and outliers, XGBoost modeling