Clear Sky Science · de
Generative Adversarial Networks und hyperparameter-optimiertes XGBoost zur verbesserten Vorhersage von Herzkrankheiten
Warum frühe Herzwarnungen wichtig sind
Herzkrankheiten bleiben die weltweit häufigste Todesursache, doch die meisten Schäden bauen sich über Jahre still und unbemerkt auf. Ärztinnen und Ärzte erfassen bereits große Mengen an Gesundheitsdaten – von Alter und Blutdruck bis zu Schlaf- und Bewegungsgewohnheiten – aber aus diesen unordentlichen, unvollkommenen Daten verlässliche Frühwarnungen zu gewinnen, ist schwierig. Dieses Papier stellt einen neuen computerbasierten Ansatz vor, genannt GAN-XO, der darauf ausgelegt ist, große Gesundheitsbefragungen zu durchsieben und mit bemerkenswerter Genauigkeit zu identifizieren, wer ein hohes Risiko für Herzkrankheiten hat, während er seine Entscheidungen für Klinikerinnen und Kliniker zugleich klarer und vertrauenswürdiger macht.
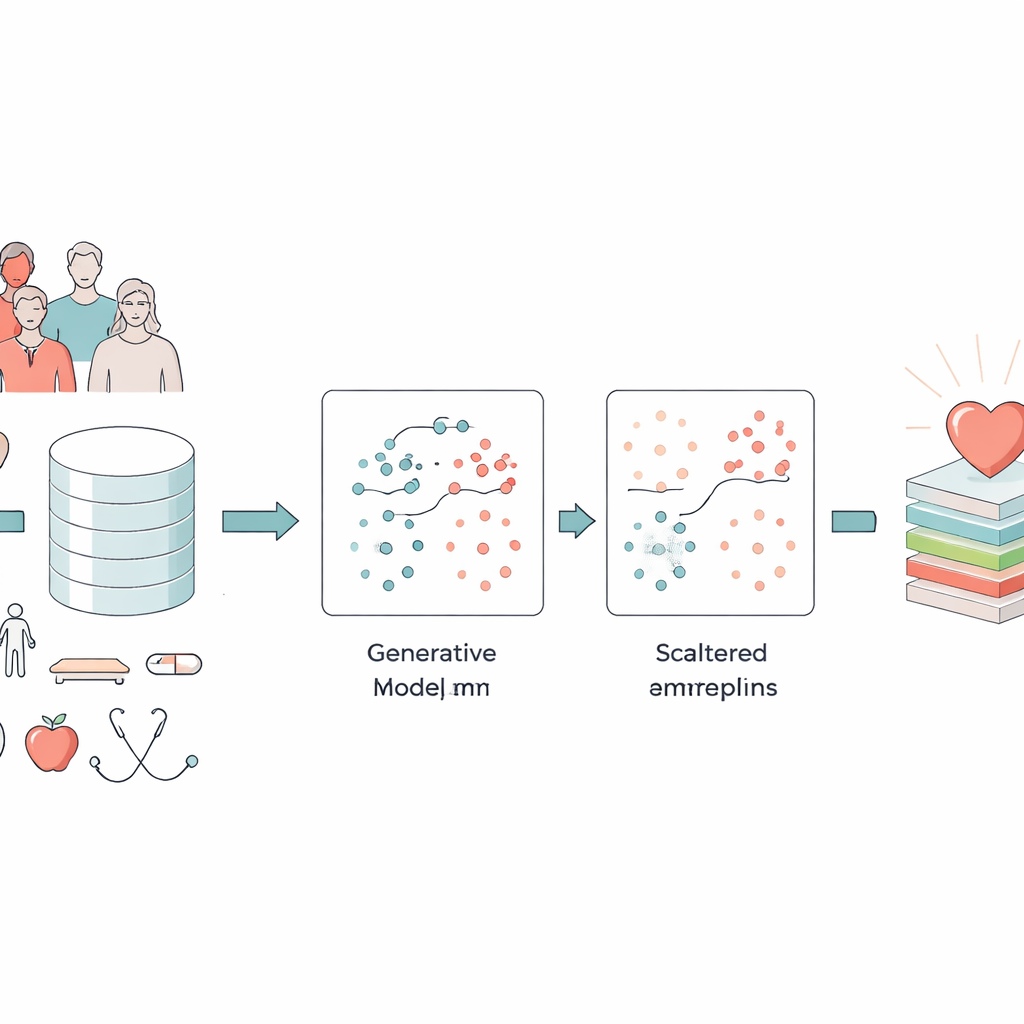
Unordentliche Gesundheitsdaten in etwas Nützliches verwandeln
Die Forschenden konzentrierten sich auf zwei große Datensätze: eine umfangreiche US-Befragung mit mehr als 300.000 Erwachsenen und die langjährige Framingham Heart Study. Diese Sammlungen kombinieren einfache Angaben wie Alter, Geschlecht und Rauchen mit klinischen Messwerten wie Body-Mass-Index, Blutdruck, Blutzucker sowie selbstberichteter körperlicher und psychischer Gesundheit. Eine zentrale Herausforderung besteht darin, dass nur ein kleiner Bruchteil der Teilnehmenden in solchen Datensätzen tatsächlich Herzkrankheiten hat. Standardmodelle neigen dazu, das „einfache“ Muster zu lernen – dass die meisten Menschen gesund sind – und die deutlich kleinere, aber entscheidende Gruppe der Erkrankten zu übersehen. Hinzu kommen Fehler, extreme Messwerte und fehlende Angaben in Umfragen und Krankenakten, die selbst die besten Algorithmen verwirren können.
Der Maschine beibringen, realistische Patientinnen und Patienten zu erfinden
Um das Imbalancierungsproblem anzugehen, setzte das Team auf eine Art künstlicher Intelligenz namens Generative Adversarial Network (GAN). Statt bestehende Datensätze einfach zu kopieren oder zu vermischen, lernt ein GAN, vollständig neue, realistisch wirkende „synthetische“ Patientinnen und Patienten zu erzeugen, die denjenigen mit Herzkrankheit ähneln. Das konkret verwendete Modell ist ein conditional GAN, dem vorgegeben wird, welche Klasse es nachahmen soll (Krankheit oder keine Krankheit), sodass es gezielt glaubwürdigere Hochrisikobeispiele erzeugen kann. Die Autorinnen und Autoren überprüften, dass diese synthetischen Patientendaten wichtige Zusammenhänge bewahrten – etwa die Beziehung zwischen Alter und Blutdruck oder zwischen Diabetes und Blutzucker – statt unmögliche Kombinationen zu erfinden. Dieser Schritt bereicherte die für das Vorhersagemodell verfügbare Datenmenge erheblich, ohne Klinikerinnen und Kliniker dazu zu zwingen, mehr reale Proben zu erheben.
Schlechte Daten vor der Vorhersage bereinigen
Allerdings können synthetische Daten auch Auffälligkeiten einführen, etwa biologisch unmögliche Körpergewichte oder widersprüchliche Gesundheitsprofile. Auch reale Befragungen und Krankenakten leiden an ähnlichen Problemen. Das GAN-XO-Framework ergänzt daher eine ungewöhnlich strenge Datenbereinigungsstufe. Mit zwei gängigen statistischen Werkzeugen – dem z-Score und dem Interquartilsabstand – markiert und entfernt es Werte, die weit außerhalb medizinisch vernünftiger Bereiche liegen für Messgrößen wie Body-Mass-Index, Anzahl schlechter Gesundheitstage pro Monat, Schlafdauer, Blutdruck und Glukosespiegel. Wichtig ist, dass die Autoren überprüften, dass dieser Prozess nicht bevorzugt Personen mit Herzkrankheit entfernte; der Anteil Erkrankter und Gesunder, die gelöscht wurden, blieb nahezu unverändert gegenüber den Originaldaten. Das Ergebnis ist eine kleinere, aber weitaus vertrauenswürdigere Sammlung von Datensätzen, auf denen das Modell trainiert werden kann.
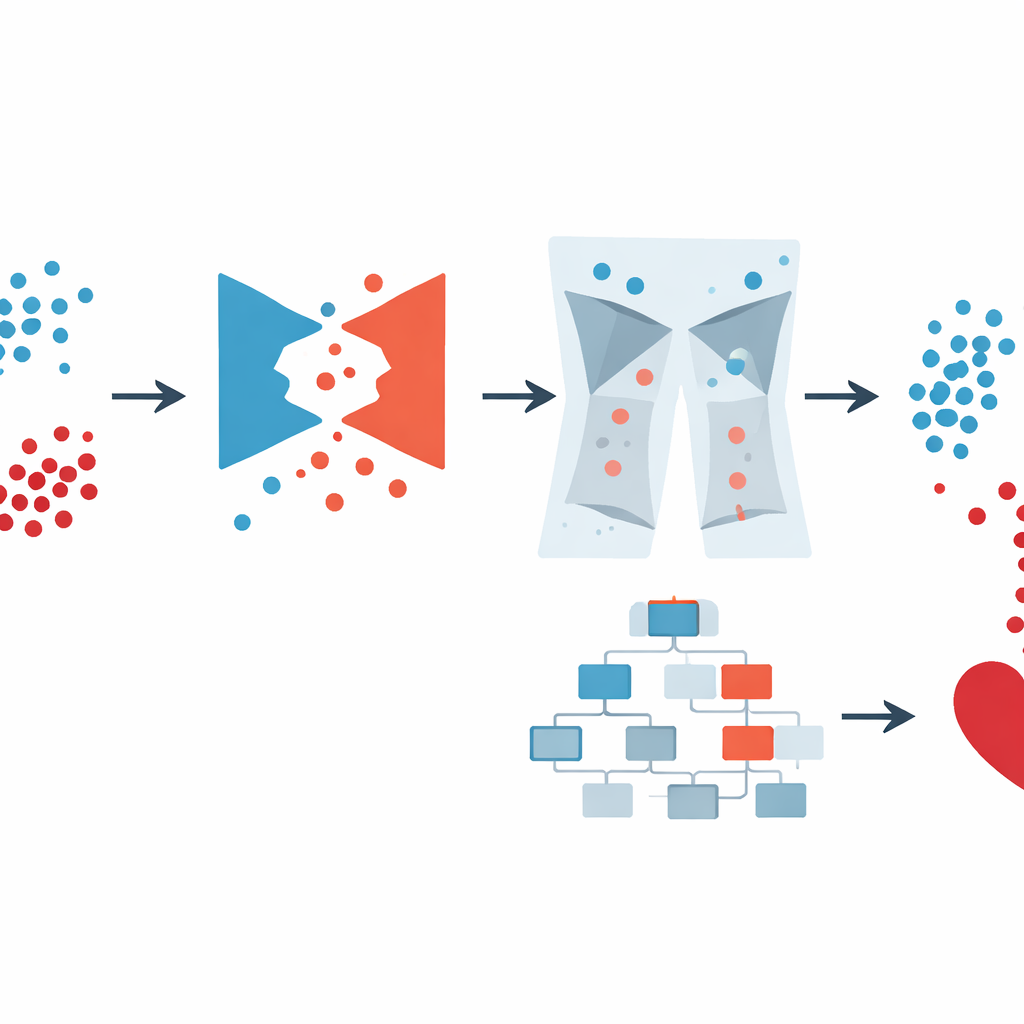
Intelligente Daten mit einem leistungsstarken Prädiktor kombinieren
Sobald die Daten ausgeglichen und bereinigt waren, setzten die Autorinnen und Autoren XGBoost ein, eine verbreitete Machine-Learning-Methode, die ein Ensemble aus Entscheidungsbäumen baut, um die finale Vorhersage zu treffen. Anstatt die vielen Einstellungen manuell zu optimieren, nutzten sie Optuna, ein automatisiertes Suchsystem, das verschiedene Kombinationen von Modellparametern ausprobiert und die auswählt, die die Leistung verbessern. Sie verglichen mehrere Varianten: schlichtes XGBoost, XGBoost mit einfacheren Balancierungsverfahren und die komplette GAN-XO-Pipeline mit und ohne Ausreißerentfernung. In der großen US-Befragung erreichte das vollständige GAN-XO-System etwa 96,6 % Genauigkeit und einen ähnlich hohen F1-Score und übertraf damit zuvor veröffentlichte Methoden. Ebenso wichtig: Durch das Entfernen von Ausreißern verringerte sich die Lücke zwischen Trainings- und Testergebnissen, was darauf hindeutet, dass das Modell echte Muster lernte und nicht nur Rauschen auswendig lernte.
Black-Box-Vorhersagen verständlicher machen
Da medizinische Entscheidungen erklärbar sein müssen, untersuchten die Autorinnen und Autoren auch, wie das Modell zu seinen Ergebnissen gelangte. Sie verwendeten zwei verbreitete Interpretationswerkzeuge, SHAP und LIME, um zu zeigen, welche Faktoren die Vorhersagen in Richtung „Herzkrankheit“ oder „keine Herzkrankheit“ sowohl für Patientengruppen als auch für Einzelfälle am stärksten beeinflussten. Wurden Modelle mit Daten trainiert, die noch Ausreißer enthielten, waren die Erklärungen instabil und stützten sich mitunter auf seltsame Merkmal-Kombinationen. Nach der Bereinigung traten vertraute Risikofaktoren – wie Alter, allgemeiner Gesundheitszustand, Körpergewicht, Rauchen sowie vorangegangener Schlaganfall oder Diabetes – klarer und konsistenter hervor. Das vermittelte stärker das Gefühl, dass die Schlussfolgerungen des Modells der klinischen Einsicht entsprechen und nicht nur statistische Kuriositäten widerspiegeln.
Was das für Patientinnen, Patienten und Ärztinnen und Ärzte bedeutet
Einfach ausgedrückt zeigt diese Studie, dass bessere Vorhersagen zu Herzkrankheiten genauso sehr von sorgfältiger Datenbehandlung wie von ausgefeilten Algorithmen abhängen. Indem ein KI-System zunächst lernt, zusätzliche realistische Hochrisikopatienten „vorzustellen“, dann konsequent implausible Datensätze herausfiltert und schließlich eine leistungsstarke Vorhersage-Engine feinabstimmt, liefert das GAN-XO-Framework sowohl hohe Genauigkeit als auch besser interpretierbare Ergebnisse. Für Patientinnen und Patienten könnte das frühere und verlässlichere Warnungen auf Basis routinemäßiger Gesundheitsinformationen bedeuten; für Klinikerinnen und Kliniker bietet es ein Werkzeug, dessen Entscheidungen stärker der realen medizinischen Logik entsprechen. Die Autorinnen und Autoren argumentieren, dass diese Kombination aus Datenqualitätskontrolle, intelligenter Synthese und transparenter Vorhersage eine vielversprechende Blaupause für künftige KI-Systeme im Gesundheitswesen darstellt.
Zitation: Begum, S.S., Swamy, A., Dhanka, S. et al. Generative adversarial networks and hyperparameter-optimized XGBoost for enhanced heart disease prediction. Sci Rep 16, 11326 (2026). https://doi.org/10.1038/s41598-026-40322-y
Schlüsselwörter: Vorhersage von Herzkrankheiten, medizinisches maschinelles Lernen, synthetische Gesundheitsdaten, Datenqualität und Ausreißer, XGBoost-Modellierung