Clear Sky Science · pt
Redes adversariais generativas e XGBoost otimizado por hiperparâmetros para previsão aprimorada de doenças cardíacas
Por que avisos precoces sobre o coração importam
As doenças cardíacas continuam sendo a principal causa de morte no mundo, mas grande parte do dano se acumula silenciosamente ao longo de anos. Médicos já coletam enormes quantidades de informações de saúde — desde idade e pressão arterial até sono e hábitos de exercício —, mas transformar esses dados confusos e imperfeitos em avisos precoces confiáveis é difícil. Este artigo apresenta uma nova abordagem computacional, chamada GAN-XO, projetada para vasculhar grandes levantamentos de saúde e identificar quem está em alto risco de doença cardíaca com notável precisão, ao mesmo tempo em que torna suas decisões mais claras e confiáveis para os clínicos.
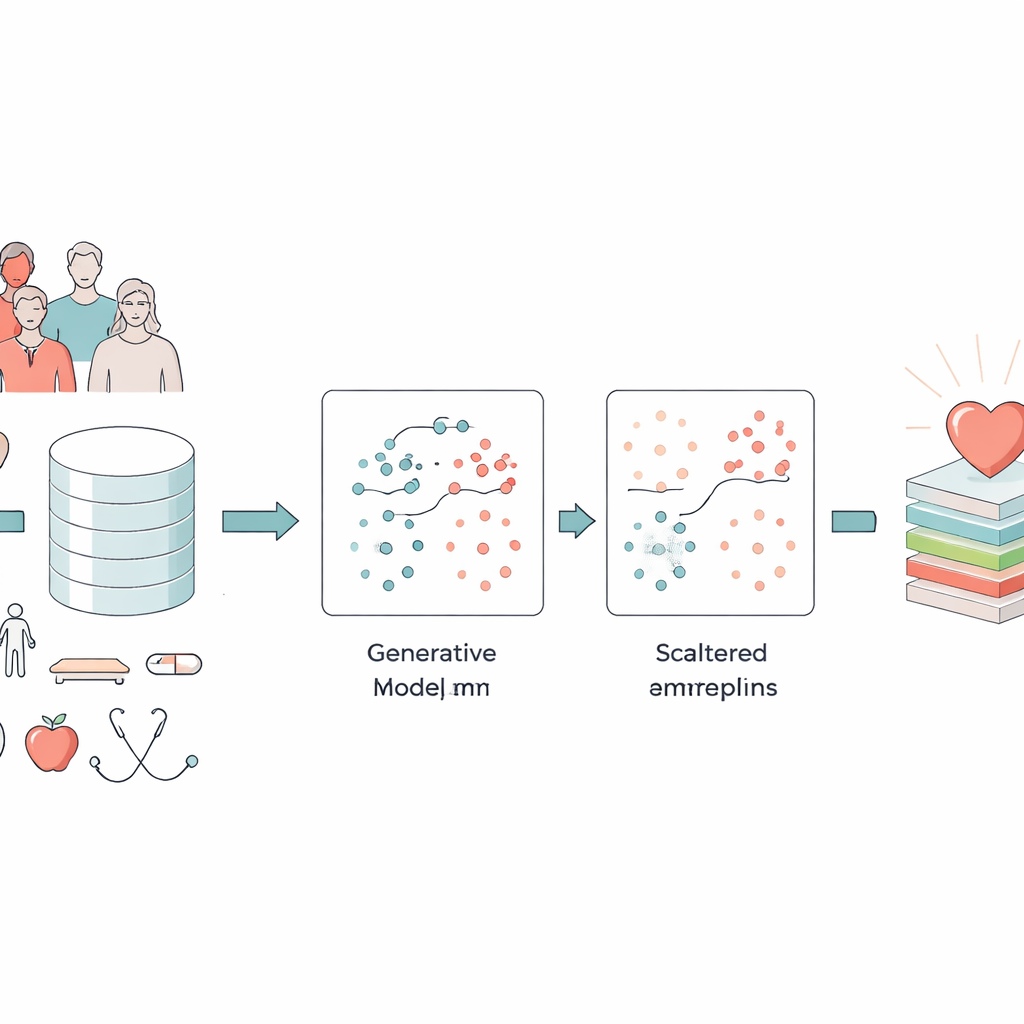
Transformando dados de saúde bagunçados em algo útil
Os pesquisadores focaram em dois grandes conjuntos de dados: uma pesquisa massiva nos EUA com mais de 300.000 adultos e o duradouro Estudo do Coração de Framingham. Essas coleções misturam detalhes simples como idade, sexo e tabagismo com medidas clínicas, como índice de massa corporal, pressão arterial, glicemia e saúde física e mental autorreferidas. Um desafio central é que apenas uma pequena fração das pessoas nesses conjuntos realmente tem doença cardíaca. Modelos computacionais padrão tendem a aprender o padrão “fácil” — que a maioria das pessoas é saudável — e negligenciam o grupo muito menor, mas crucial, que está doente. Além disso, pesquisas e prontuários médicos contêm erros, medições extremas e dados faltantes que podem confundir até os melhores algoritmos.
Ensinando uma máquina a imaginar pacientes realistas
Para enfrentar o problema do desbalanceamento, a equipe recorreu a um tipo de inteligência artificial conhecido como Rede Adversarial Generativa (GAN). Em vez de simplesmente copiar ou misturar registros existentes, uma GAN aprende a criar “pacientes” sintéticos inteiramente novos e realistas que se assemelham àqueles com doença cardíaca. O projeto específico, uma GAN condicional, é instruído sobre qual classe deve imitar (doença ou ausência de doença), para que possa gerar deliberadamente exemplos de alto risco mais críveis. Os autores verificaram que esses pacientes sintéticos preservavam relações importantes — como o vínculo entre idade e pressão arterial ou entre diabetes e glicemia — em vez de inventar combinações impossíveis. Essa etapa enriqueceu muito os dados disponíveis para o modelo de previsão sem solicitar aos clínicos mais amostras do mundo real.
Eliminando dados ruins antes de fazer previsões
No entanto, dados sintéticos também podem introduzir anomalias, como pesos corporais biologicamente impossíveis ou perfis de saúde contraditórios. Pesquisas reais e registros hospitalares apresentam problemas semelhantes. O framework GAN-XO, portanto, adiciona uma etapa de limpeza de dados incomumente rigorosa. Usando duas ferramentas estatísticas padrão — o z-score e a amplitude interquartil — ele sinaliza e remove valores que estão muito fora de intervalos medicamente razoáveis para medições como índice de massa corporal, dias de saúde ruim no mês, tempo de sono, pressão arterial e níveis de glicose. Crucialmente, os autores verificaram que esse processo não excluiu preferencialmente pessoas com doença cardíaca; a proporção de indivíduos doentes e saudáveis removidos permaneceu quase a mesma do dado original. O resultado é um conjunto menor, mas muito mais confiável, de registros para treinar.
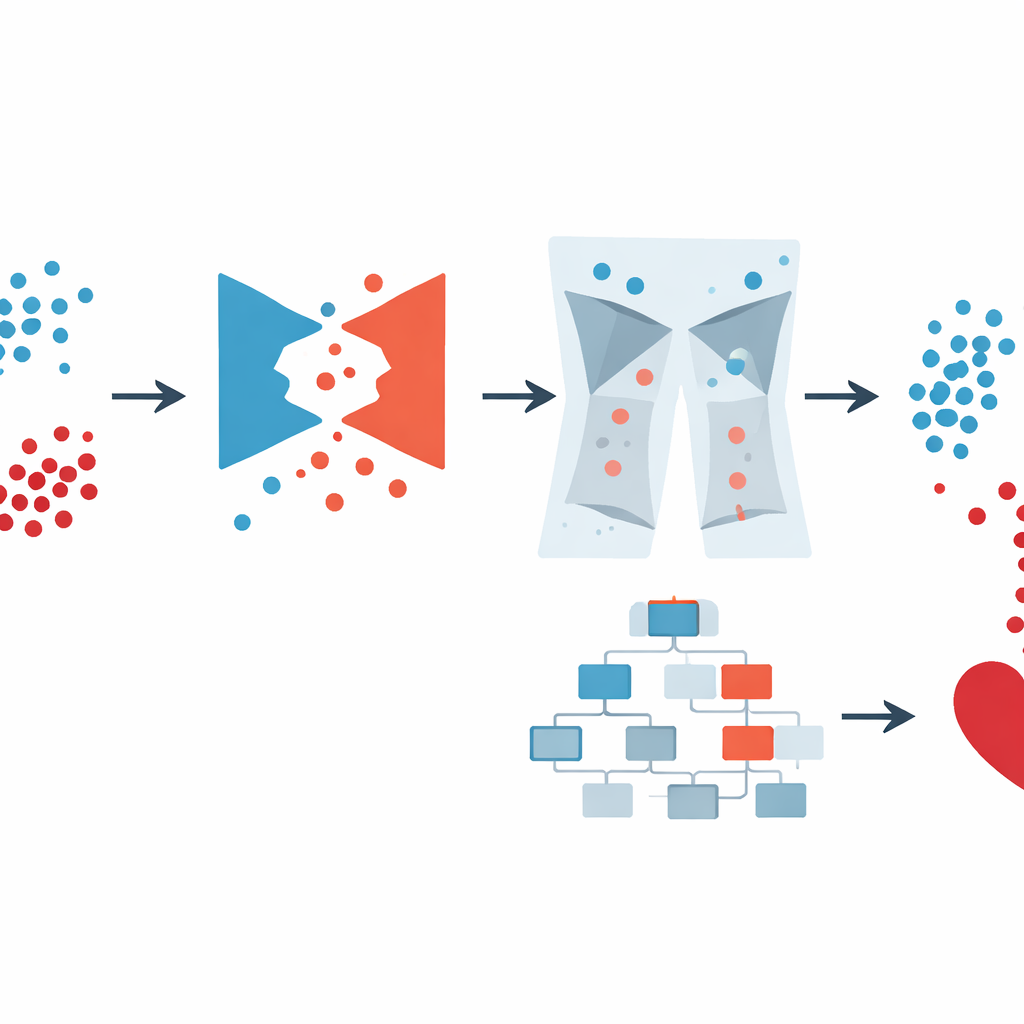
Combinando dados inteligentes e um preditor poderoso
Uma vez que os dados foram balanceados e limpos, os autores usaram o XGBoost, um método popular de aprendizado de máquina que constrói um conjunto de árvores de decisão, para fazer a predição final. Em vez de ajustar manualmente suas muitas configurações, confiaram no Optuna, um sistema de busca automatizado que testa diferentes combinações de parâmetros do modelo e mantém aquelas que melhoram o desempenho. Eles compararam várias versões: XGBoost simples, XGBoost com métodos de balanceamento mais simples e o pipeline completo GAN-XO com e sem remoção de outliers. Na grande pesquisa dos EUA, o sistema GAN-XO completo alcançou cerca de 96,6% de acurácia e uma pontuação F1 igualmente alta, superando métodos publicados anteriormente. Tão importante quanto, a remoção de outliers reduziu a diferença entre os resultados de treinamento e teste, mostrando que o modelo estava aprendendo padrões genuínos em vez de memorizar ruído.
Tornando previsões de caixa-preta mais compreensíveis
Como decisões médicas precisam ser explicáveis, os autores também examinaram como o modelo chegava às suas conclusões. Eles usaram duas ferramentas populares de interpretação, SHAP e LIME, para mostrar quais fatores pressionavam mais fortemente as previsões para “doença cardíaca” ou “sem doença cardíaca” tanto para grupos de pacientes quanto para casos individuais. Quando treinado em dados que ainda continham outliers, as explicações do modelo eram instáveis e às vezes se apoiavam em combinações estranhas de características. Após a limpeza, a importância de fatores de risco familiares — como idade, saúde geral, peso corporal, tabagismo e histórico de AVC ou diabetes — tornou-se mais clara e consistente. Isso deu uma impressão mais forte de que o raciocínio do modelo correspondia ao entendimento clínico, e não apenas a peculiaridades estatísticas.
O que isso significa para pacientes e médicos
Em termos simples, este estudo mostra que melhorar a previsão de doenças cardíacas depende tanto de um manuseio cuidadoso dos dados quanto de algoritmos sofisticados. Ao primeiro ensinar um sistema de IA a “imaginar” pacientes de alto risco adicionais e realistas, depois filtrar agressivamente registros implausíveis e, finalmente, ajustar um motor de predição poderoso, o framework GAN-XO entrega tanto alta precisão quanto resultados mais interpretáveis. Para os pacientes, isso pode significar avisos mais precoces e mais confiáveis baseados em informações de saúde rotineiras; para os clínicos, oferece uma ferramenta cujas escolhas refletem melhor a lógica médica real. Os autores argumentam que essa combinação de controle de qualidade dos dados, síntese inteligente e predição transparente é um roteiro promissor para futuros sistemas de IA na saúde.
Citação: Begum, S.S., Swamy, A., Dhanka, S. et al. Generative adversarial networks and hyperparameter-optimized XGBoost for enhanced heart disease prediction. Sci Rep 16, 11326 (2026). https://doi.org/10.1038/s41598-026-40322-y
Palavras-chave: previsão de doenças cardíacas, aprendizado de máquina médico, dados de saúde sintéticos, qualidade de dados e outliers, modelagem XGBoost