Clear Sky Science · it
Reti generative antagoniste e XGBoost ottimizzato sui iperparametri per migliorare la previsione delle malattie cardiache
Perché contano gli avvisi precoci sul cuore
Le malattie cardiache restano la principale causa di morte a livello mondiale, eppure la maggior parte dei danni si accumula silenziosamente nel corso degli anni. I medici raccolgono già grandi quantità di informazioni sulla salute — dall'età e dalla pressione arteriosa a abitudini di sonno e attività fisica — ma trasformare questi dati disordinati e imperfetti in avvisi precoci affidabili è difficile. Questo articolo presenta un nuovo approccio informatico, chiamato GAN-XO, progettato per setacciare grandi indagini sulla salute e individuare chi è ad alto rischio di malattia cardiaca con notevole accuratezza, rendendo inoltre le sue decisioni più chiare e attendibili per i clinici.
Trasformare dati sanitari disordinati in qualcosa di utile
I ricercatori si sono concentrati su due grandi insiemi di dati: una massiccia indagine statunitense su oltre 300.000 adulti e il lungo studio di Framingham. Queste raccolte mescolano dettagli semplici come età, sesso e fumo con misure cliniche quali indice di massa corporea, pressione arteriosa, glicemia e autovalutazioni della salute fisica e mentale. Una sfida centrale è che solo una piccola frazione delle persone in tali dataset ha effettivamente una malattia cardiaca. I modelli computazionali standard tendono a imparare il «pattern» più semplice — che la maggior parte delle persone è sana — e trascurano il gruppo molto più piccolo ma cruciale di individui malati. Inoltre, indagini e cartelle cliniche contengono errori, misurazioni estreme e dati mancanti che possono confondere anche i migliori algoritmi.
Insegnare a una macchina a immaginare pazienti realistici
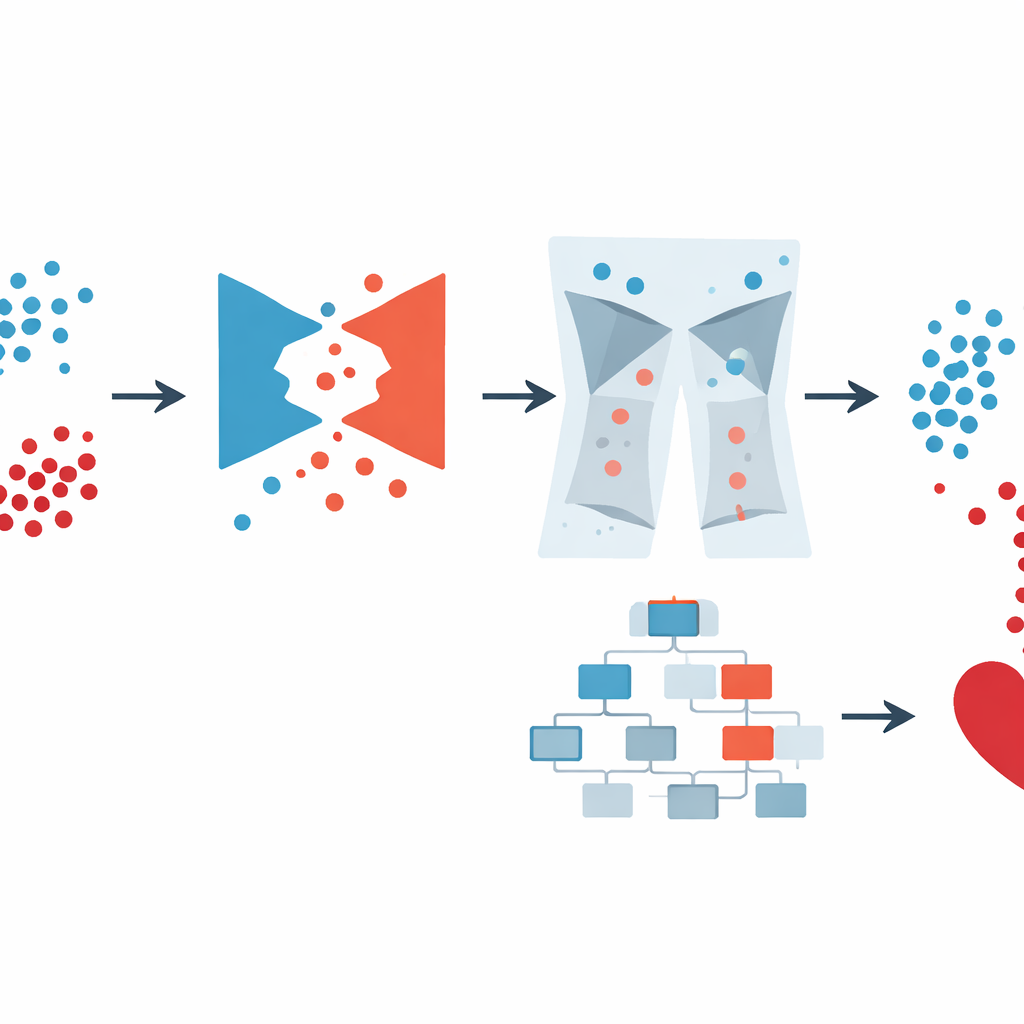
Per affrontare il problema dello sbilanciamento, il team si è rivolto a un tipo di intelligenza artificiale noto come rete generativa antagonista (GAN). Invece di limitarsi a copiare o mescolare record esistenti, una GAN impara a creare nuovi «pazienti» sintetici realistici che somigliano a quelli con malattia cardiaca. Il progetto specifico, una GAN condizionale, viene istruito sulla classe che deve imitare (malattia o assenza di malattia), così da poter generare deliberatamente esempi ad alto rischio più credibili. Gli autori hanno verificato che questi pazienti sintetici preservassero relazioni importanti — come il legame tra età e pressione arteriosa o tra diabete e glicemia — anziché inventare combinazioni impossibili. Questo passaggio ha notevolmente arricchito i dati disponibili per il modello predittivo senza richiedere ai clinici di raccogliere più campioni reali.
Pulire i dati errati prima di fare previsioni
Tuttavia, i dati sintetici possono anche introdurre anomalie, come pesi corporei biologicamente impossibili o profili di salute contraddittori. Anche le indagini reali e le cartelle ospedaliere presentano problemi simili. Il framework GAN-XO aggiunge quindi una fase di pulizia dei dati particolarmente rigorosa. Utilizzando due strumenti statistici standard — lo z-score e l'intervallo interquartile — segnala e rimuove valori che si collocano ben al di fuori degli intervalli ragionevoli dal punto di vista medico per misure come indice di massa corporea, giorni di cattiva salute in un mese, ore di sonno, pressione arteriosa e livelli di glucosio. È cruciale che gli autori abbiano verificato che questo processo non eliminasse preferenzialmente le persone con malattia cardiaca; la proporzione di individui malati e sani rimossi è rimasta quasi la stessa dei dati originali. Il risultato è una raccolta più piccola ma molto più affidabile di record su cui addestrare il modello.
Combinare dati intelligenti e un predittore potente
Una volta che i dati sono stati bilanciati e puliti, gli autori hanno usato XGBoost, un metodo di machine learning popolare che costruisce un insieme di alberi decisionali, per effettuare la previsione finale. Invece di regolare manualmente le molte impostazioni, si sono affidati a Optuna, un sistema di ricerca automatizzato che prova diverse combinazioni di parametri del modello e conserva quelle che migliorano le prestazioni. Hanno confrontato diverse versioni: XGBoost semplice, XGBoost con metodi di bilanciamento più elementari e l'intera pipeline GAN-XO con e senza rimozione degli outlier. Sull'ampia indagine statunitense, il sistema GAN-XO completo ha raggiunto circa il 96,6% di accuratezza e un F1-score similmente elevato, superando metodi pubblicati in precedenza. Altrettanto importante, la rimozione degli outlier ha ridotto la distanza tra risultati di addestramento e test, dimostrando che il modello stava apprendendo pattern reali invece di memorizzare rumore.
Rendere le predizioni di una scatola nera più comprensibili
Poiché le decisioni mediche devono essere spiegabili, gli autori hanno anche esaminato come il modello arrivasse alle sue conclusioni. Hanno utilizzato due strumenti di interpretazione popolari, SHAP e LIME, per mostrare quali fattori spingevano maggiormente le predizioni verso «malattia cardiaca» o «assenza di malattia cardiaca» sia per gruppi di pazienti sia per casi individuali. Quando addestrato su dati ancora contenenti outlier, le spiegazioni del modello erano instabili e a volte si fondavano su combinazioni strane di caratteristiche. Dopo la pulizia, l'importanza di fattori di rischio conosciuti — come età, stato di salute generale, peso corporeo, fumo e precedenti di ictus o diabete — è diventata più chiara e coerente. Questo ha fornito una maggiore sensazione che il ragionamento del modello corrispondesse alla comprensione clinica, e non solo a stranezze statistiche.
Cosa significa per pazienti e medici
In termini semplici, questo studio mostra che una migliore previsione delle malattie cardiache dipende tanto da una gestione accurata dei dati quanto da algoritmi sofisticati. Insegnando prima a un sistema di IA a «immaginare» ulteriori pazienti ad alto rischio realistici, poi filtrando aggressivamente record implausibili e infine ottimizzando un potente motore predittivo, il framework GAN-XO offre sia alta accuratezza sia risultati più interpretabili. Per i pazienti, ciò potrebbe tradursi in avvisi più precoci e più affidabili basati su informazioni sanitarie di routine; per i clinici, offre uno strumento le cui scelte riflettono meglio la logica medica reale. Gli autori sostengono che questa combinazione di controllo della qualità dei dati, sintesi intelligente e predizione trasparente rappresenti un modello promettente per i futuri sistemi di IA in ambito sanitario.
Citazione: Begum, S.S., Swamy, A., Dhanka, S. et al. Generative adversarial networks and hyperparameter-optimized XGBoost for enhanced heart disease prediction. Sci Rep 16, 11326 (2026). https://doi.org/10.1038/s41598-026-40322-y
Parole chiave: previsione delle malattie cardiache, apprendimento automatico in medicina, dati sanitari sintetici, qualità dei dati e outlier, modellazione XGBoost