Clear Sky Science · ru
Генеративные состязательные сети и XGBoost с оптимизацией гиперпараметров для улучшенного прогнозирования сердечных заболеваний
Почему важны ранние предупреждения о состоянии сердца
Сердечные заболевания остаются ведущей причиной смерти в мире, хотя большая часть их вреда накапливается бесшумно годами. Врачи уже собирают огромные массивы медицинской информации — от возраста и артериального давления до привычек сна и физической активности — но превратить эти беспорядочные и несовершенные данные в надежные ранние предупреждения непросто. В этой работе представлен новый компьютерный подход под названием GAN-XO, предназначенный для обработки крупных медицинских опросов и выявления людей с высоким риском сердечных заболеваний с впечатляющей точностью, а также для повышения прозрачности и доверия к решениям модели со стороны клиницистов.
Превращение нестройных медицинских данных в полезный ресурс
Исследователи сосредоточились на двух основных наборах данных: крупном опросе в США с более чем 300 000 взрослых и давнем исследовании Framingham Heart Study. Эти коллекции объединяют простые сведения — возраст, пол, курение — с клиническими измерениями, такими как индекс массы тела, артериальное давление, уровень сахара в крови и самооценка физического и психического здоровья. Центральная проблема в том, что в таких наборах лишь небольшая доля людей фактически страдает сердечными заболеваниями. Стандартные модели склонны усваивать «простой» шаблон — что большинство людей здоровы — и пропускать гораздо меньшую, но критически важную группу больных. Кроме того, опросы и медицинские записи содержат ошибки, экстремальные показания и пропуски, которые могут запутать даже лучшие алгоритмы.
Обучение машины «представлять» реалистичных пациентов
Чтобы решить проблему несбалансированности, команда обратилась к типу искусственного интеллекта, известному как генеративная состязательная сеть (GAN). Вместо простого копирования или смешивания существующих записей, GAN учится создавать полностью новых, реалистичных «синтетических» пациентов, похожих на тех, кто болеет сердечными заболеваниями. Специфическая конструкция — условный GAN — получает указание, какой класс имитировать (болен или здоров), поэтому он целенаправленно генерирует более правдоподобные примеры с высоким риском. Авторы проверяли, что эти синтетические пациенты сохраняют важные взаимосвязи — например, связь между возрастом и давлением или между диабетом и уровнем сахара — а не придумывают невозможные комбинации. Этот шаг существенно обогатил данные для модели прогнозирования без необходимости дополнительного сбора реальных образцов клиницистами.
Очистка плохих данных перед прогнозированием
Однако синтетические данные также могут вносить странности, такие как биологически невозможный вес или противоречивые профили здоровья. Реальные опросы и больничные записи страдают от тех же проблем. Поэтому в рамках GAN-XO добавлен особенно строгий этап очистки данных. С помощью двух стандартных статистических инструментов — z-оценки и межквартильного размаха — система отмечает и удаляет значения, сильно выходящие за медицински разумные пределы для таких показателей, как индекс массы тела, количество дней плохого самочувствия в месяце, продолжительность сна, артериальное давление и уровень глюкозы. Важно, что авторы проверили: этот процесс не приводил к преимущественному удалению людей с сердечными заболеваниями; доля удалённых больных и здоровых оставалась почти такой же, как в исходных данных. В результате получилась меньшая, но гораздо более надёжная коллекция записей для обучения.
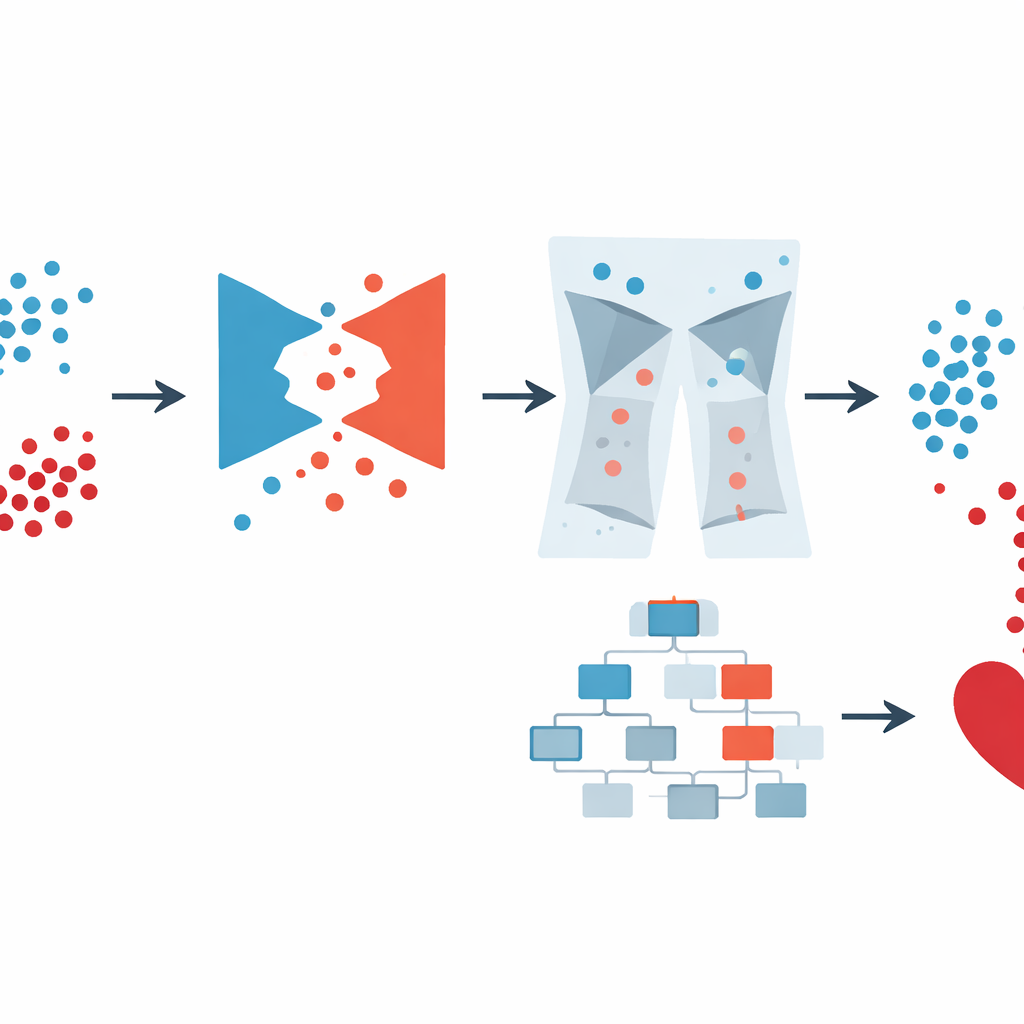
Сочетание умных данных и мощного предиктора
После выравнивания и очистки данных авторы использовали XGBoost, популярный метод машинного обучения, строящий ансамбль деревьев решений, для окончательного прогноза. Вместо ручной настройки множества параметров они прибегли к Optuna — системе автоматического поиска, которая тестирует различные комбинации настроек модели и сохраняет те, что улучшают производительность. Они сравнили несколько вариантов: простой XGBoost, XGBoost с более простыми методами балансировки и полный конвейер GAN-XO с удалением выбросов и без. В крупном американском опросе полный GAN-XO достиг примерно 96,6 % точности и сопоставимо высокого F1-метрика, превзойдя ранее опубликованные методы. Не менее важно, что удаление выбросов сократило разрыв между результатами на обучении и тестировании, что указывает на то, что модель усваивала реальные закономерности, а не запоминала шум.
Делая предсказания «чёрного ящика» более понятными
Поскольку медицинские решения должны быть объяснимыми, авторы также изучили, как модель приходит к своим выводам. Они использовали два популярных инструмента интерпретации — SHAP и LIME — чтобы показать, какие факторы сильнее всего сдвигают прогноз в сторону «сердечного заболевания» или «отсутствия сердечного заболевания» для групп пациентов и отдельных случаев. При обучении на данных с выбросами объяснения модели были нестабильны и иногда опирались на странные комбинации признаков. После очистки важность знакомых факторов риска — таких как возраст, общее состояние здоровья, масса тела, курение и перенесённые инсульты или диабет — стала более явной и последовательной. Это усилило ощущение того, что рассуждения модели соответствуют клиническому пониманию, а не лишь статистическим особенностям.
Что это значит для пациентов и врачей
Проще говоря, это исследование показывает, что улучшение прогнозирования сердечных заболеваний зависит не меньше от тщательной работы с данными, чем от сложных алгоритмов. Сначала обучив ИИ «представлять» дополнительные реалистичные примеры пациентов высокого риска, затем агрессивно отфильтровав неправдоподобные записи и, наконец, настроив мощный механизм прогнозирования, фреймворк GAN-XO обеспечивает и высокую точность, и более интерпретируемые результаты. Для пациентов это может означать более ранние и надёжные предупреждения на основе рутинной медицинской информации; для врачей — инструмент, чьи решения лучше отражают реальную медицинскую логику. Авторы утверждают, что такое сочетание контроля качества данных, умного синтеза и прозрачного прогнозирования является перспективным планом для будущих систем ИИ в здравоохранении.
Цитирование: Begum, S.S., Swamy, A., Dhanka, S. et al. Generative adversarial networks and hyperparameter-optimized XGBoost for enhanced heart disease prediction. Sci Rep 16, 11326 (2026). https://doi.org/10.1038/s41598-026-40322-y
Ключевые слова: прогнозирование сердечных заболеваний, медицинское машинное обучение, синтетические медицинские данные, качество данных и выбросы, моделирование XGBoost