Clear Sky Science · nl
Generatieve adversariële netwerken en hyperparameter-geoptimaliseerde XGBoost voor verbeterde voorspelling van hartziekten
Waarom vroege hartwaarschuwingen ertoe doen
Hartziekten blijven 's werelds belangrijkste doodsoorzaak, terwijl het grootste deel van de schade zich jarenlang stil ophoopt. Artsen verzamelen al grote hoeveelheden gezondheidsgegevens — van leeftijd en bloeddruk tot slaap- en bewegingsgewoonten — maar van die rommelige, onvolmaakte data betrouwbare vroege waarschuwingen maken is moeilijk. Dit artikel presenteert een nieuwe computergebaseerde aanpak, genoemd GAN-XO, die ontworpen is om grote gezondheidsenquêtes te doorzoeken en nauwkeurig te identificeren wie een hoog risico op hartziekten heeft, terwijl de beslissingen ook helderder en betrouwbaarder worden voor clinici.
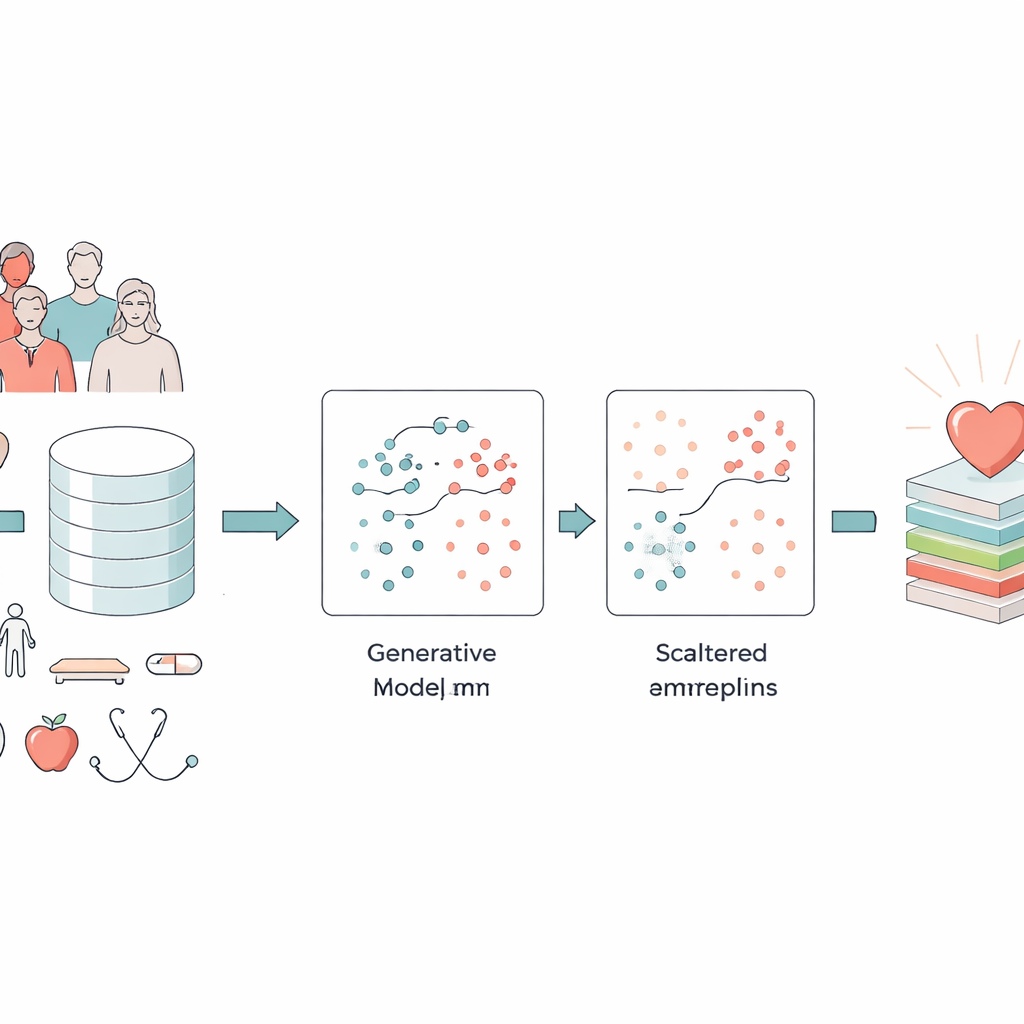
Rommelige gezondheidsdata omzetten in iets bruikbaars
De onderzoekers concentreerden zich op twee grote datasets: een omvangrijke Amerikaanse enquête van meer dan 300.000 volwassenen en de veeljarige Framingham Heart Study. Deze verzamelingen combineren eenvoudige gegevens zoals leeftijd, geslacht en roken met klinische metingen zoals body mass index, bloeddruk, bloedsuiker en zelfgerapporteerde fysieke en mentale gezondheid. Een belangrijke uitdaging is dat slechts een klein aandeel van de mensen in zulke datasets daadwerkelijk hartziekte heeft. Standaard computermodellen leren vaak het "gemakkelijke" patroon — dat de meeste mensen gezond zijn — en negeren de veel kleinere maar cruciale groep die ziek is. Bovendien bevatten enquêtes en medische dossiers fouten, extreme waarden en ontbrekende stukken die zelfs de beste algoritmen kunnen verwarren.
Een machine leren realistische patiënten te bedenken
Om het ongebalanceerde probleem aan te pakken, gebruikte het team een type kunstmatige intelligentie dat bekendstaat als een Generative Adversarial Network (GAN). In plaats van bestaande dossiers simpelweg te kopiëren of te vermengen, leert een GAN volledig nieuwe, realistische "synthetische" patiënten te creëren die lijken op degenen met hartziekte. Het specifieke ontwerp, een conditionele GAN, krijgt te horen welke klasse hij moet nabootsen (ziekte of geen ziekte), zodat hij opzettelijk meer geloofwaardige hoog-risicovoorbeelden kan genereren. De auteurs controleerden dat deze synthetische patiënten belangrijke verbanden bewaarden — zoals de relatie tussen leeftijd en bloeddruk of tussen diabetes en bloedsuiker — in plaats van onmogelijke combinaties te verzinnen. Deze stap verrijkte de data die beschikbaar waren voor het voorspellingsmodel aanzienlijk, zonder dat clinici meer echte monsters hoefden te verzamelen.
Slechte data verwijderen voordat voorspellingen worden gedaan
Toch kan synthetische data ook eigenaardigheden introduceren, zoals biologisch onmogelijke lichaamsgewichten of tegenstrijdige gezondheidsprofielen. Ook echte enquêtes en ziekenhuisdossiers kampen met soortgelijke problemen. Het GAN-XO-kader voegt daarom een ongewoon strikte stap voor gegevensopschoning toe. Met twee gangbare statistische hulpmiddelen — de z-score en de interkwartielafstand — markeert en verwijdert het waarden die ver buiten medisch redelijke bereiken vallen voor metingen zoals body mass index, aantal slechte gezondheidsdagen per maand, slaapduur, bloeddruk en glucosewaarden. Cruciaal is dat de auteurs controleerden dat dit proces niet selectief mensen met hartziekte verwijderde; het aandeel verwijderde zieken en gezonde personen bleef vrijwel hetzelfde als in de oorspronkelijke data. Het resultaat is een kleinere maar veel betrouwbaardere verzameling dossiers om op te trainen.
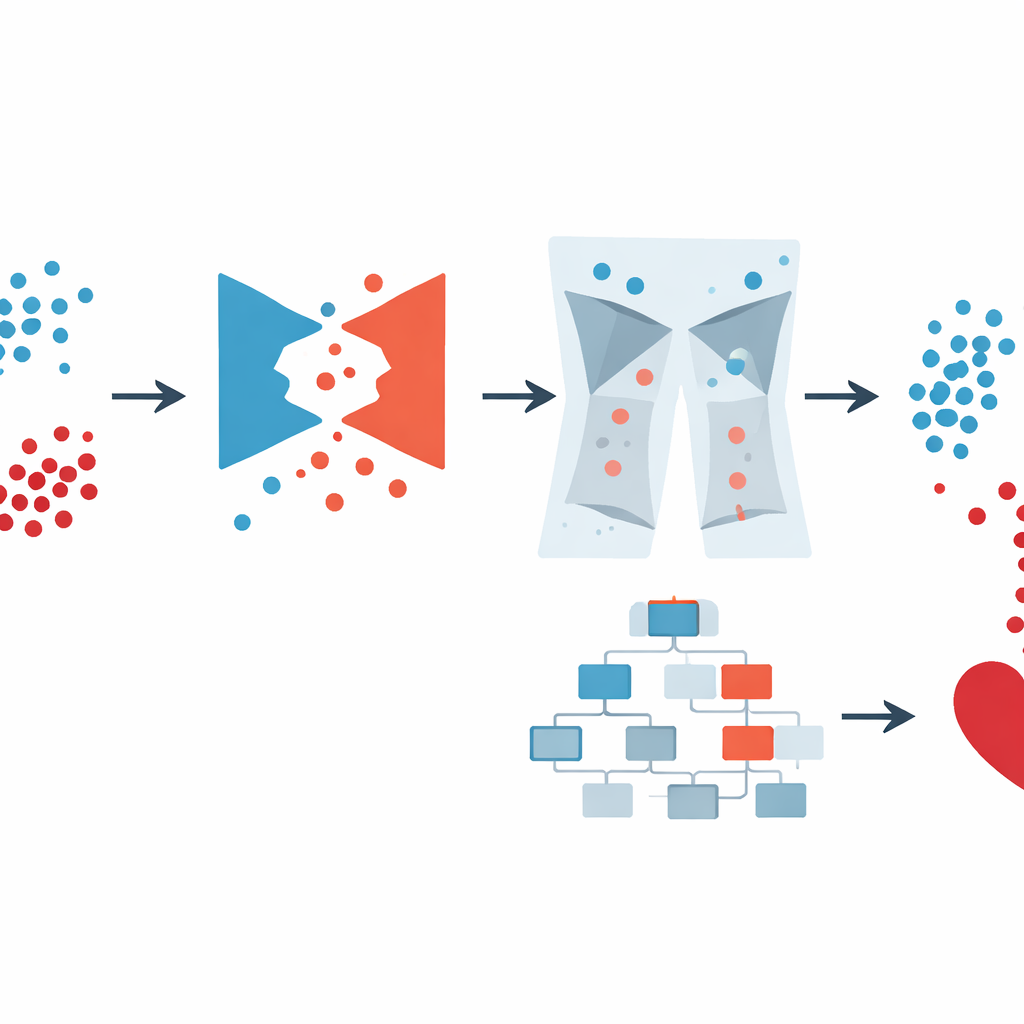
Slimme data combineren met een krachtig voorspellingsmodel
Nadat de data in balans waren gebracht en opgeschoond, gebruikten de auteurs XGBoost, een populair machine-learningmethod dat een ensemble van beslisbomen bouwt, om de uiteindelijke voorspelling te doen. In plaats van handmatig veel instellingen te tunen, vertrouwden ze op Optuna, een geautomatiseerd zoeksysteem dat verschillende combinaties van modelparameters probeert en die bewaart die de prestaties verbeteren. Ze vergeleken meerdere versies: gewone XGBoost, XGBoost met eenvoudigere balansmethoden en de volledige GAN-XO-pijplijn met en zonder uitschieterverwijdering. In de grote Amerikaanse enquête behaalde het complete GAN-XO-systeem ongeveer 96,6% nauwkeurigheid en een vergelijkbaar hoge F1-score, waarmee het eerdere gepubliceerde methoden overtrof. Even belangrijk was dat het verwijderen van uitschieters de kloof tussen training- en testresultaten verkleinde, wat aantoont dat het model echte patronen leerde in plaats van ruis te memoriseren.
Zwart‑doosvoorspellingen beter begrijpelijk maken
Aangezien medische beslissingen verklaarbaar moeten zijn, onderzochten de auteurs ook hoe het model tot zijn conclusies kwam. Ze gebruikten twee veelgebruikte interpretatietools, SHAP en LIME, om te laten zien welke factoren de voorspellingen richting "hartziekte" of "geen hartziekte" duwden, zowel voor groepen patiënten als voor individuele gevallen. Wanneer het model werd getraind op data die nog uitschieters bevatten, waren de verklaringen onstabiel en leunden ze soms op vreemde combinatie van kenmerken. Na opschoning werden de belangrijkheid van vertrouwde risicofactoren — zoals leeftijd, algemene gezondheid, lichaamsgewicht, roken en eerder doorgemaakte beroerte of diabetes — duidelijker en consistenter. Dit gaf een sterker gevoel dat de redenering van het model overeenkwam met klinisch begrip, en niet alleen met statistische eigenaardigheden.
Wat dit betekent voor patiënten en artsen
In eenvoudige bewoordingen toont deze studie aan dat betere voorspelling van hartziekten net zozeer afhangt van zorgvuldig databeheer als van geavanceerde algoritmen. Door eerst een AI-systeem te leren extra realistische hoog-risicopatiënten te "bedenken", vervolgens implausibele dossiers agressief te filteren en tenslotte een krachtig voorspellingssysteem te optimaliseren, levert het GAN-XO-kader zowel hoge nauwkeurigheid als beter interpreteerbare resultaten. Voor patiënten kan dat betekenen dat er vroeger en betrouwbaarder waarschuwingen op basis van routinematige gezondheidsinformatie mogelijk zijn; voor clinici biedt het een hulpmiddel waarvan de keuzes beter overeenkomen met echte medische logica. De auteurs betogen dat deze combinatie van kwaliteitscontrole van data, slimme synthese en transparante voorspelling een veelbelovend blauwdruk is voor toekomstige AI-systemen in de gezondheidszorg.
Bronvermelding: Begum, S.S., Swamy, A., Dhanka, S. et al. Generative adversarial networks and hyperparameter-optimized XGBoost for enhanced heart disease prediction. Sci Rep 16, 11326 (2026). https://doi.org/10.1038/s41598-026-40322-y
Trefwoorden: voorspelling van hartziekten, medische machine learning, synthetische gezondheidsgegevens, gegevenskwaliteit en uitschieters, XGBoost-modellering