Clear Sky Science · sv
Förbättring av enkelbilds osuperviserad domänanpassning för personåteridentifiering mellan kameror
Varför smartare kameror spelar roll
Moderna städer förlitar sig på nätverk av säkerhetskameror för att bidra till människors säkerhet, men dessa kameror är inte automatiskt överens om vem som är vem. En person kan se väldigt annorlunda ut från en kamera till en annan på grund av skiftande vinklar, skuggor eller trängsel. Denna artikel tar sig an utmaningen att pålitligt följa samma person över många kameror utan omfattande mänsklig övervakning. Författarna utformar ett nytt system som rensar och anpassar kamerabilder innan de jämförs, vilket gör den digitala uppsikten mer träffsäker samtidigt som befintligt material används mer effektivt.
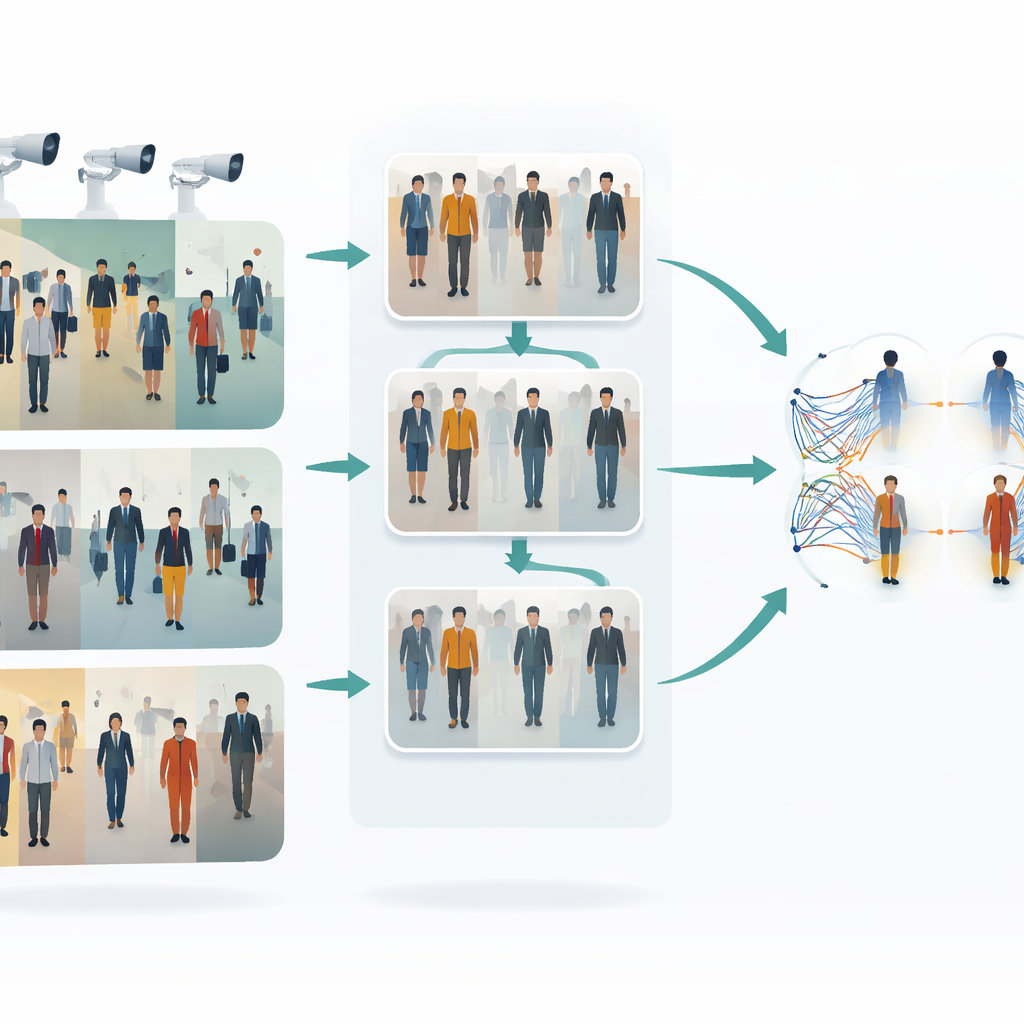
Utmaningen att följa personer över kameror
När en person går genom en tågstation, ett köpcentrum eller ett gatunät fångar olika kameror olika glimtar av hen. Kläder kan se ljusare eller mattare ut, ansikten kan vara delvis dolda och kroppsställningar förändras ständigt. Traditionella ”single shot”-metoder försöker känna igen en person från en enda bild per kamera i ett snabbt svep, vilket är snabbt men ofta bräckligt: de kan misslyckas när ljusförhållanden förändras, när någon delvis blockeras av andra eller när kamerainställningar skiljer sig åt. Att märka tusentals bilder för hand för att träna ett robust system är dyrt och långsamt, så det finns ett stort intresse för metoder som kan lära sig från omarkerade data samtidigt som de hanterar all denna visuella variation.
Att få kameror att dela en gemensam stil
Den första nyckelidén i detta arbete är att få bilder från olika kameror att likna varandra mer innan någon matchning försöks. Författarna använder en typ av bild-till-bild-översättare kallad CycleGAN för att ta bilder från en kamera och omstylas som om de kom från en annan, utan att behöva perfekta parvisa exempel. Detta skapar många nya, realistiska varianter av varje person som speglar olika synvinklar, belysning och bakgrunder. Genom att blanda och ombalansera stilar över kameror minskar systemet den visuella ”klyftan” mellan dem. Som en följd ser inlärningsalgoritmen en rikare, mer enhetlig träningsuppsättning som bättre representerar vad som faktiskt händer i ett multi-kameraövervakningsnätverk.
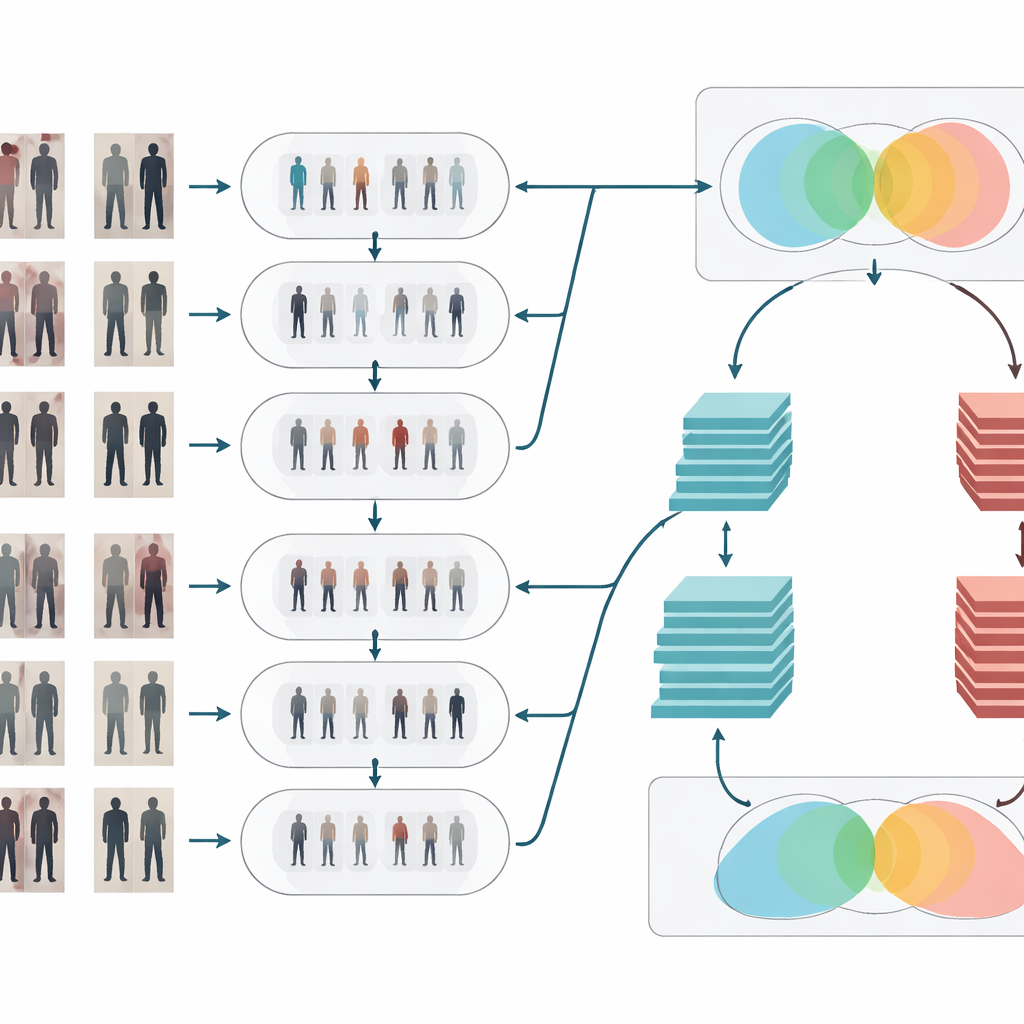
Rensa och förtydliga den visuella signalen
Efter stilanpassningen går bilderna igenom två klassiska rengöringssteg. Först tar ett medianfilter bort små, fläckvisa brus — såsom sensorartefakter eller komprimeringsfel — samtidigt som viktiga kanter som kroppskonturer och klädmönster hålls skarpa. Sedan justerar histogramutjämning ljusfördelningen så att mörka områden lyfts och alltför ljusa partier tonas ner, vilket förbättrar kontrasten. Tillsammans gör dessa operationer att människors former och texturer framträder tydligare och mer konsekvent över kameror, vilket hjälper igenkänningssteget att fokusera på meningsfulla visuella detaljer istället för att förvirras av dålig belysning eller brusiga pixlar.
Två hjärnor som tänker tillsammans
För att avgöra om två bilder visar samma person använder systemet ett Siamesiskt nätverk — i praktiken två identiska neurala nätverk som delar vikter och bearbetar varje bild parallellt. Denna artikel förstärker idén genom att ge den siamesiska designen två ”grenar” med olika djup. Den ena grenen bygger på en relativt grund modell (ResNet-50) som fångar mellannivåledtrådar såsom allmänna klädområden och kroppens övergripande form. Den andra använder en djupare modell (ResNet-152) som plockar upp finare detaljer som subtila veck, texturer och små accessoarer. Deras feature-mappar poolas noggrant och kombineras sedan, så att den slutliga representationen blandar bred struktur med finfördelat utseende. Nätverket beräknar därefter en likhetspoäng som anger om två glimtar från olika kameror sannolikt tillhör samma individ.
Sätta metoden på prov
Författarna utvärderar sitt ramverk på en vanligt använd referensdatamängd av fotgängarbilder fångade av flera kameror. De jämför sin metod med flera starka befintliga tillvägagångssätt som antingen fokuserar på kamerasammanhang, smart klustring eller traditionella siamesiska designer. Över många mått på framgång — såsom noggrannhet, precision och känslighet — hamnar det nya systemet konsekvent i topp, och närmar sig eller överstiger 99 % noggrannhet under vissa träningstestuppdelningar. Detaljerade experiment visar också att varje komponent är viktig: att ta bort CycleGAN-augmentering, bildrensningen eller dual-gren-designen sänker prestandan, vilket bekräftar att vinsterna kommer från hela pipelinen som arbetar tillsammans.
Vad detta betyder för verklig övervakning
I vardaglig bemärkelse visar denna forskning hur man kan göra kameranätverk mycket bättre på att spåra människor när de rör sig genom komplexa miljöer, även när förhållanden förändras och ingen har tid att märka data för hand. Genom att harmonisera bilders utseende, rensa dem och sedan jämföra dem med ett omsorgsfullt utformat tvillingnätverk kan det föreslagna systemet känna igen individer mer tillförlitligt över många kameravinklar. Detta kan stödja säkrare offentliga miljöer och mer effektiv övervakning, samtidigt som det betonar vikten av genomtänkt och integritetsmedveten användning av så kraftfulla identifieringsverktyg.
Citering: Vidhyalakshmi, M.K., Neduncheliyan, S., Hemlathadhevi, A. et al. Enhancing single shot unsupervised domain adaptation for inter-camera person re-identification. Sci Rep 16, 11247 (2026). https://doi.org/10.1038/s41598-026-37168-9
Nyckelord: personåteridentifiering, övervakningskameror, osuperviserat lärande, datorseende, djupa neurala nätverk