Clear Sky Science · pt
Melhorando a adaptação de domínio não supervisionada em único disparo para reidentificação de pessoas entre câmeras
Por que câmeras mais inteligentes importam
Cidades modernas dependem de redes de câmeras de segurança para ajudar a manter as pessoas seguras, mas essas câmeras não “concordam” automaticamente sobre quem é quem. Uma pessoa pode parecer muito diferente de uma câmera para outra por causa de ângulos, sombras ou aglomerações. Este artigo enfrenta o desafio de acompanhar de forma confiável a mesma pessoa através de muitas câmeras sem supervisão humana intensa. Os autores projetam um novo sistema que limpa e adapta as imagens das câmeras antes de compará-las, tornando a vigilância digital mais precisa e usando as filmagens existentes de forma mais eficiente.
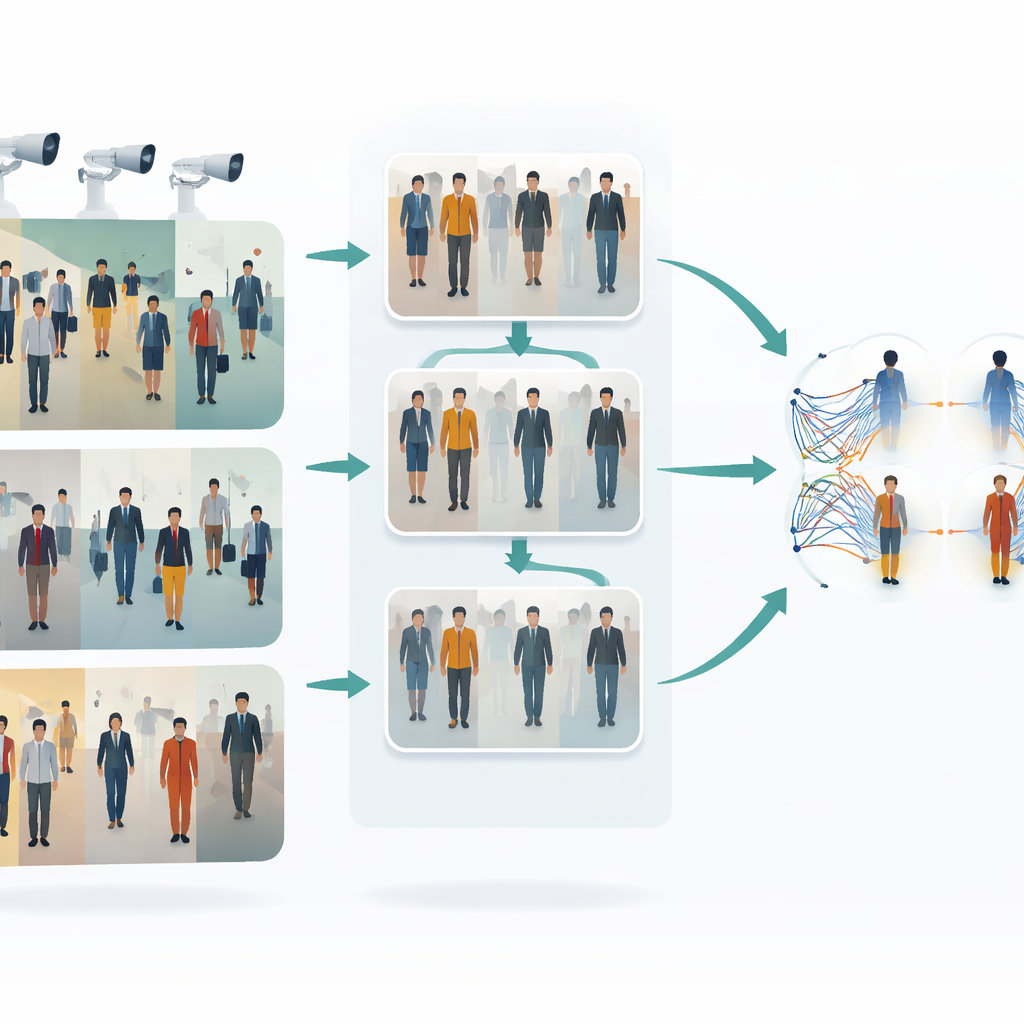
O desafio de seguir pessoas entre câmeras
Quando uma pessoa atravessa uma estação de trem, um shopping ou uma rede de ruas, diferentes câmeras captam vislumbres distintos dela. Roupas podem parecer mais claras ou mais escuras, rostos podem ficar parcialmente ocultos e posturas corporais mudam constantemente. Métodos tradicionais de “single shot” tentam reconhecer uma pessoa a partir de uma única imagem por câmera em uma única passada, o que é rápido, mas frequentemente frágil: eles podem falhar quando a iluminação muda, quando alguém está parcialmente bloqueado por outras pessoas ou quando as configurações das câmeras diferem. Rotular milhares de imagens manualmente para treinar um sistema robusto é caro e lento, portanto há grande interesse em métodos que aprendam a partir de dados não rotulados e que ainda assim consigam lidar com toda essa variedade visual.
Ensinando as câmeras a compartilhar um estilo comum
A primeira ideia-chave deste trabalho é fazer com que as imagens de diferentes câmeras pareçam mais semelhantes antes de qualquer comparação. Os autores usam um tipo de tradutor de imagem para imagem chamado CycleGAN para transformar fotos de uma câmera e reestilizá-las como se viessem de outra, sem necessidade de exemplos perfeitamente pareados. Isso cria muitas variantes realistas de cada pessoa, refletindo diferentes pontos de vista, iluminações e fundos. Ao misturar e reequilibrar estilos entre câmeras, o sistema reduz a “lacuna” visual entre elas. Como resultado, o algoritmo de aprendizado vê um conjunto de treinamento mais rico e mais uniforme, que representa melhor o que realmente acontece em uma rede de vigilância multi-câmera.
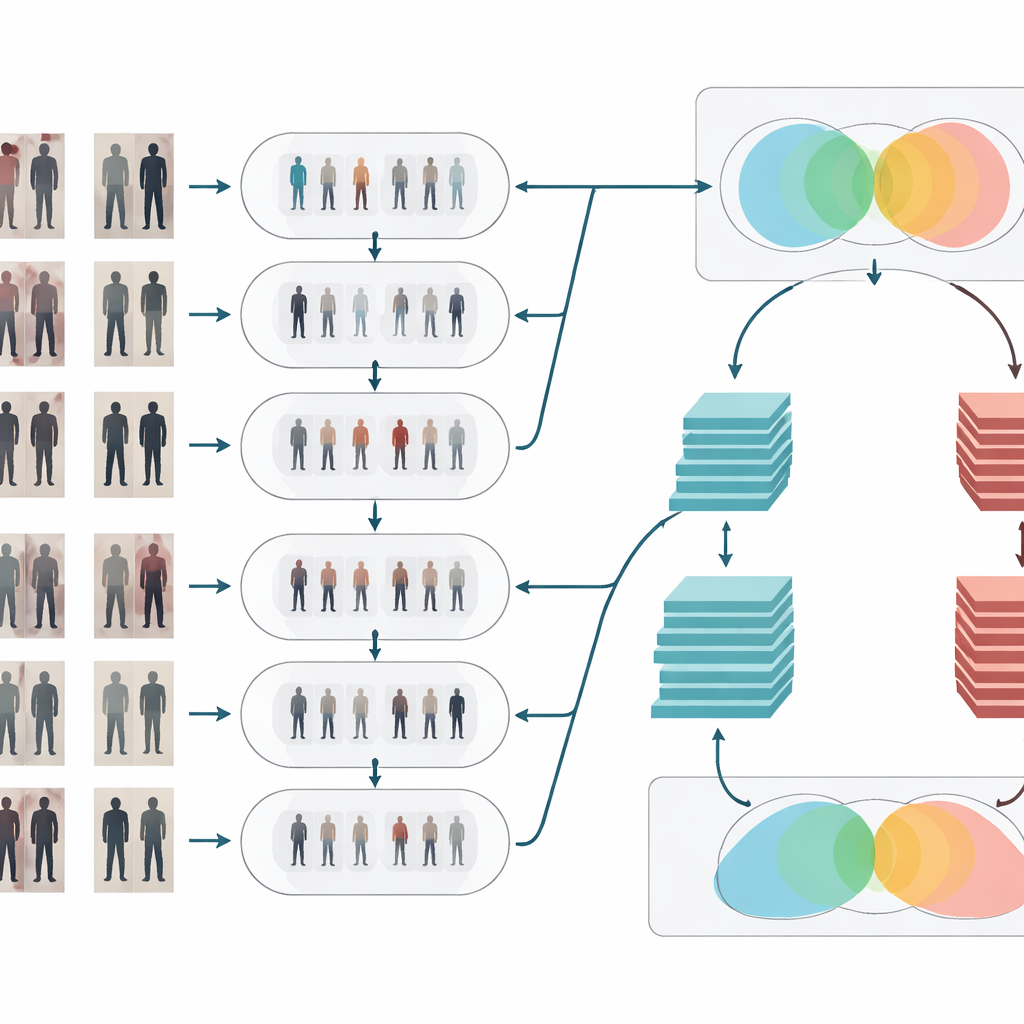
Limpeza e clarificação do sinal visual
Após a adaptação de estilo, as imagens passam por dois passos clássicos de limpeza. Primeiro, um filtro mediano remove ruído pequeno e pontual — como artefatos do sensor ou falhas de compressão — mantendo bordas importantes como contornos do corpo e padrões de roupa nítidos. Em segundo lugar, a equalização de histograma ajusta a distribuição de brilho para que regiões escuras sejam clareadas e áreas excessivamente claras sejam atenuadas, melhorando o contraste. Em conjunto, essas operações fazem com que as formas e texturas das pessoas se destaquem de forma mais clara e consistente entre câmeras, o que ajuda a etapa de reconhecimento a focar em detalhes visuais relevantes em vez de se confundir com iluminação ruim ou pixels ruidosos.
Dois cérebros que pensam juntos
Para decidir se duas imagens mostram a mesma pessoa, o sistema usa uma rede Siamese — essencialmente duas redes neurais idênticas que compartilham pesos e processam cada imagem em paralelo. Este artigo fortalece essa ideia ao dar ao design Siamese dois “ramos” com profundidades diferentes. Um ramo baseia-se em um modelo relativamente raso (ResNet-50) que captura pistas de nível médio, como regiões gerais de roupa e formato corporal global. O outro usa um modelo mais profundo (ResNet-152) que capta detalhes mais finos, como dobras sutis, texturas e pequenos acessórios. Seus mapas de características são cuidadosamente agregados e então combinados, de modo que a representação final mistura estrutura ampla com aparência de alta resolução. A rede então calcula uma pontuação de similaridade, indicando se dois vislumbres de câmeras diferentes provavelmente pertencem ao mesmo indivíduo.
Colocando o método à prova
Os autores avaliam sua estrutura em um conjunto de dados de referência amplamente usado de imagens de pedestres capturadas por múltiplas câmeras. Eles comparam sua abordagem com vários métodos fortes existentes que se concentram em contexto de câmera, agrupamento inteligente ou desenhos Siamese tradicionais. Em várias medidas de sucesso — como acurácia, precisão e sensibilidade — o novo sistema consistentemente se destaca, aproximando-se ou excedendo 99% de acurácia em algumas divisões treino–teste. Experimentos detalhados também mostram que cada componente importa: remover a augmentação CycleGAN, a limpeza da imagem ou o projeto de ramos duplos faz o desempenho cair, confirmando que os ganhos vêm do pipeline completo funcionando em conjunto.
O que isso significa para a vigilância do mundo real
Em termos práticos, esta pesquisa mostra como tornar redes de câmeras muito melhores em rastrear pessoas enquanto elas se movem por espaços complexos, mesmo quando as condições mudam e não há tempo para rotular dados manualmente. Ao harmonizar a aparência das imagens, limpá-las e então compará-las com uma rede gêmea cuidadosamente projetada, o sistema proposto pode reconhecer indivíduos com mais confiabilidade através de muitas vistas de câmera. Isso pode apoiar espaços públicos mais seguros e uma monitoração mais eficiente, ao mesmo tempo em que ressalta a importância do uso ponderado e atento à privacidade dessas poderosas ferramentas de identificação.
Citação: Vidhyalakshmi, M.K., Neduncheliyan, S., Hemlathadhevi, A. et al. Enhancing single shot unsupervised domain adaptation for inter-camera person re-identification. Sci Rep 16, 11247 (2026). https://doi.org/10.1038/s41598-026-37168-9
Palavras-chave: reidentificação de pessoas, câmeras de vigilância, aprendizado não supervisionado, visão computacional, redes neurais profundas