Clear Sky Science · en
Enhancing single shot unsupervised domain adaptation for inter-camera person re-identification
Why smarter cameras matter
Modern cities rely on networks of security cameras to help keep people safe, but those cameras don’t automatically “agree” on who is who. A person may look very different from one camera to the next because of changing angles, shadows, or crowding. This paper tackles the challenge of reliably following the same person across many cameras without heavy human supervision. The authors design a new system that cleans and adapts camera images before comparing them, making digital watchfulness more accurate while using existing footage more efficiently.
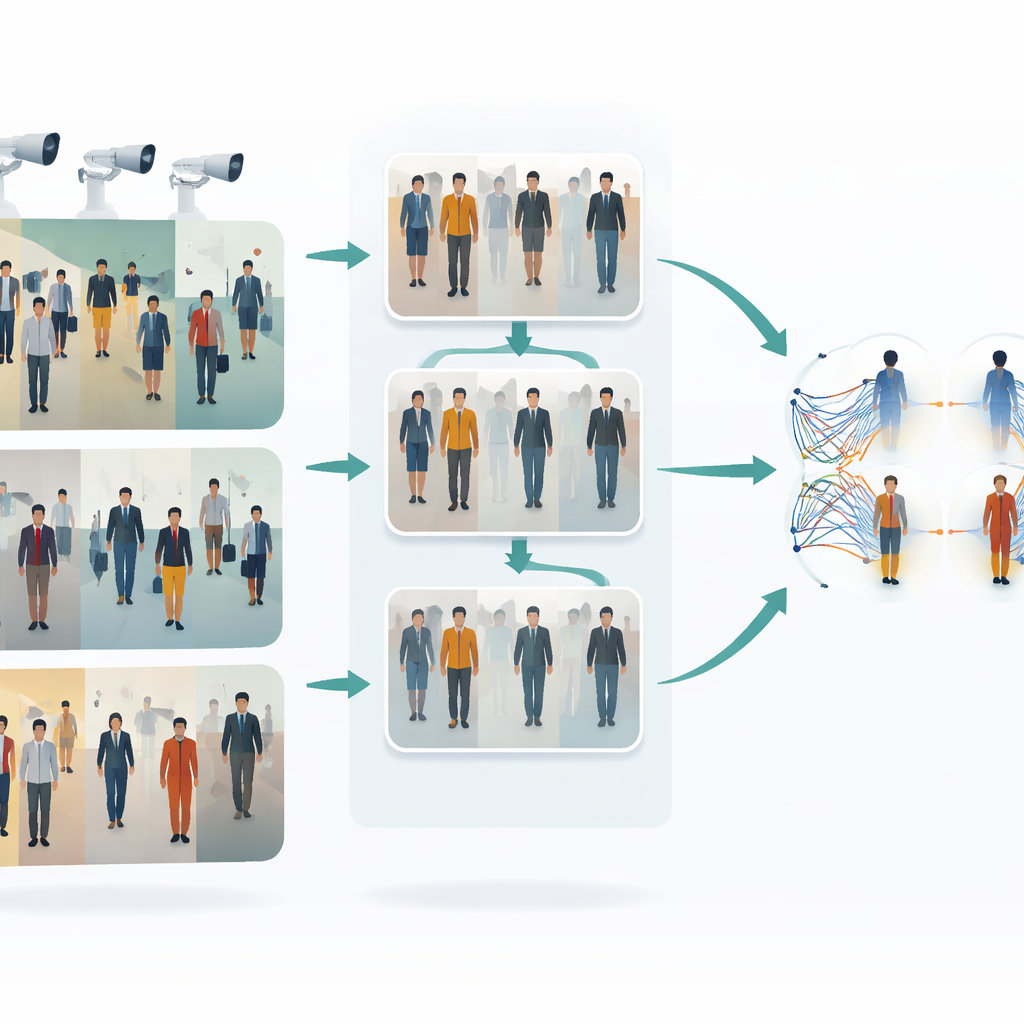
The challenge of following people across cameras
When a person walks through a train station, a shopping mall, or a street network, different cameras catch different glimpses of them. Clothes can look brighter or duller, faces can be half hidden, and body poses change constantly. Traditional “single shot” methods try to recognize a person from a single image per camera in one quick pass, which is fast but often brittle: they may fail when lighting changes, when someone is partly blocked by others, or when camera settings differ. Labeling thousands of images by hand to train a robust system is expensive and slow, so there is strong interest in methods that can learn from unlabeled data while still coping with all this visual variety.
Teaching cameras to share a common style
The first key idea in this work is to make images from different cameras look more alike before any matching is attempted. The authors use a type of image-to-image translator called CycleGAN to take pictures from one camera and re-style them as if they came from another, without needing perfectly paired examples. This creates many new, realistic variants of each person, reflecting different viewpoints, lighting, and backgrounds. By blending and rebalancing styles across cameras, the system reduces the visual “gap” between them. As a result, the learning algorithm sees a richer, more uniform training set that better represents what actually happens in a multi-camera surveillance network.
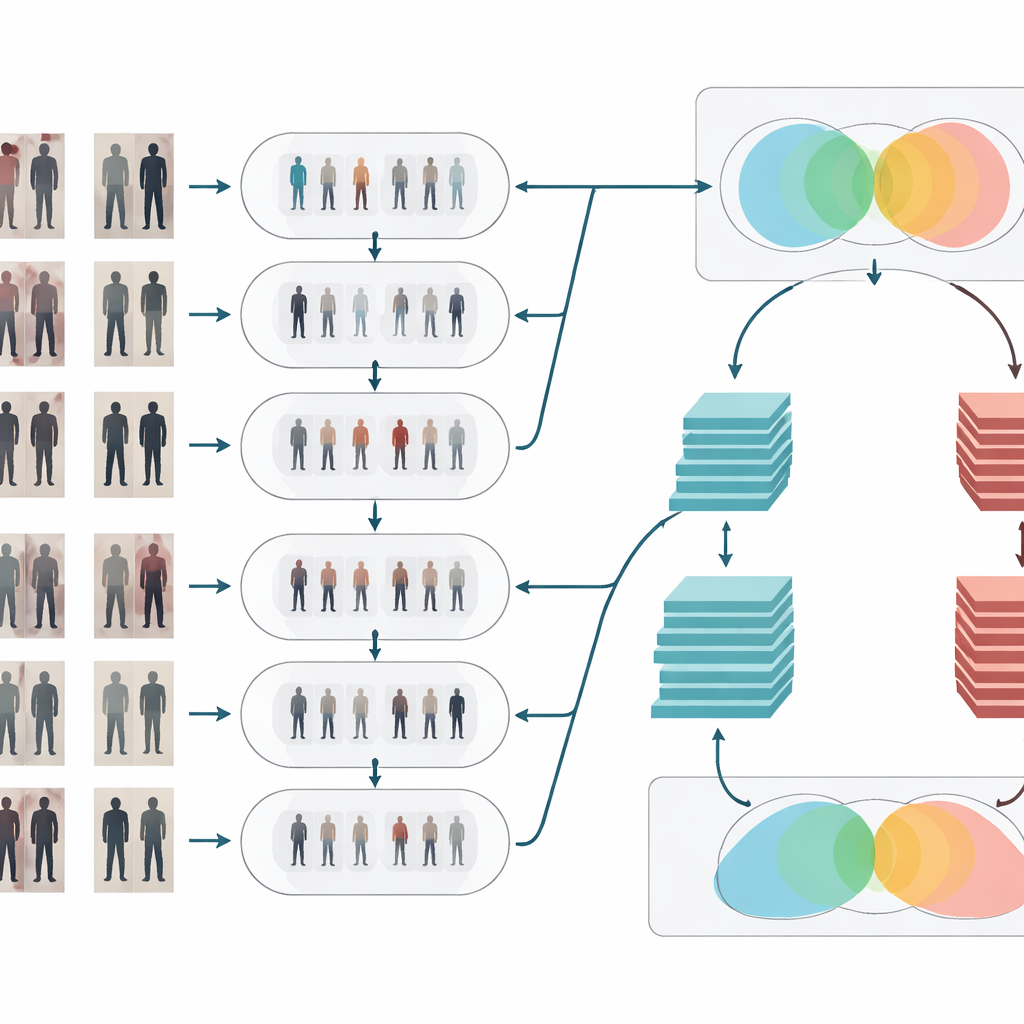
Cleaning and clarifying the visual signal
After style adaptation, the images go through two classic cleanup steps. First, a median filter removes small, spotty noise—such as sensor artifacts or compression glitches—while keeping important edges like body outlines and clothing patterns sharp. Second, histogram equalization adjusts the brightness distribution so that dark regions are lifted and overly bright areas are toned down, improving contrast. Together, these operations make people’s shapes and textures stand out more clearly and more consistently across cameras, which helps the recognition stage focus on meaningful visual details instead of being confused by poor lighting or noisy pixels.
Two brains that think together
To decide whether two images show the same person, the system uses a Siamese network—essentially two identical neural networks that share weights and process each image in parallel. This paper strengthens that idea by giving the Siamese design two “branches” with different depths. One branch is based on a relatively shallow model (ResNet-50) that captures mid-level cues such as general clothing regions and overall body shape. The other uses a deeper model (ResNet-152) that picks up finer details like subtle folds, textures, and small accessories. Their feature maps are carefully pooled and then combined, so the final representation blends broad structure with fine-grained appearance. The network then computes a similarity score, indicating whether two glimpses from different cameras likely belong to the same individual.
Putting the method to the test
The authors evaluate their framework on a widely used benchmark dataset of pedestrian images captured by multiple cameras. They compare their approach with several strong existing methods that either focus on camera context, clever clustering, or traditional Siamese designs. Across many measures of success—such as accuracy, precision, and sensitivity—the new system consistently comes out on top, approaching or exceeding 99% accuracy under some train–test splits. Detailed experiments also show that each component matters: removing the CycleGAN augmentation, the image cleanup, or the dual-branch design makes performance drop, confirming that the gains come from the full pipeline working together.
What this means for real-world surveillance
In everyday terms, this research shows how to make camera networks much better at tracking people as they move through complex spaces, even when conditions change and no one has time to label data by hand. By harmonizing the look of images, cleaning them, and then comparing them with a carefully designed twin-network, the proposed system can recognize individuals more reliably across many camera views. This could support safer public spaces and more efficient monitoring, while also highlighting the importance of thoughtful, privacy-aware use of such powerful identification tools.
Citation: Vidhyalakshmi, M.K., Neduncheliyan, S., Hemlathadhevi, A. et al. Enhancing single shot unsupervised domain adaptation for inter-camera person re-identification. Sci Rep 16, 11247 (2026). https://doi.org/10.1038/s41598-026-37168-9
Keywords: person re-identification, surveillance cameras, unsupervised learning, computer vision, deep neural networks