Clear Sky Science · fr
Amélioration de l’adaptation de domaine non supervisée en prise unique pour la ré-identification de personnes inter-caméras
Pourquoi des caméras plus intelligentes comptent
Les villes modernes s’appuient sur des réseaux de caméras de sécurité pour contribuer à la sûreté des personnes, mais ces caméras ne « s’accordent » pas automatiquement sur l’identité des individus. Une même personne peut sembler très différente d’une caméra à l’autre en raison des angles, des ombres ou de la densité de la foule. Cet article aborde le défi de suivre de façon fiable une même personne à travers plusieurs caméras sans supervision humaine importante. Les auteurs conçoivent un nouveau système qui nettoie et adapte les images des caméras avant de les comparer, rendant la surveillance numérique plus précise tout en exploitant plus efficacement les séquences existantes.
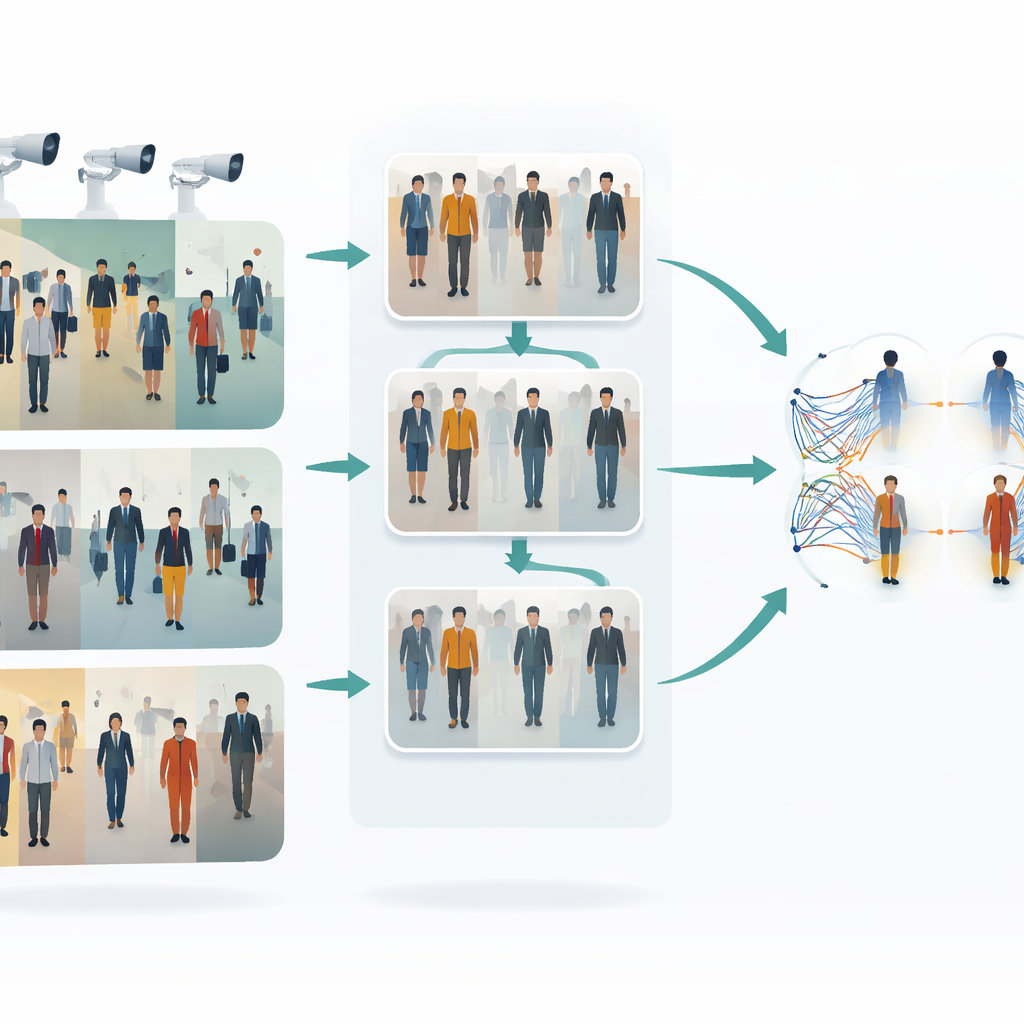
Le défi de suivre des personnes à travers des caméras
Lorsqu’une personne traverse une gare, un centre commercial ou un réseau de rues, différentes caméras n’en capturent que des aperçus variés. Les vêtements peuvent paraître plus clairs ou plus ternes, les visages partiellement masqués et les postures corporelles changent en permanence. Les méthodes « prise unique » traditionnelles essaient de reconnaître une personne à partir d’une seule image par caméra en une passe rapide, ce qui est rapide mais souvent fragile : elles peuvent échouer quand l’éclairage change, lorsqu’une personne est partiellement occultée ou lorsque les réglages des caméras diffèrent. Annoter des milliers d’images manuellement pour entraîner un système robuste est coûteux et long, d’où un fort intérêt pour des méthodes capables d’apprendre à partir de données non étiquetées tout en gérant cette grande variabilité visuelle.
Apprendre aux caméras à partager un style commun
La première idée clé de ce travail est d’homogénéiser l’apparence des images issues de caméras différentes avant toute tentative d’appariement. Les auteurs utilisent un type de traducteur image-à-image appelé CycleGAN pour prendre des images d’une caméra et les re-styliser comme si elles provenaient d’une autre, sans nécessiter d’exemples parfaitement appariés. Cela génère de nombreuses variantes réalistes de chaque personne, reflétant différents points de vue, éclairages et arrière-plans. En mélangeant et en rééquilibrant les styles entre caméras, le système réduit le « fossé » visuel qui les sépare. En conséquence, l’algorithme d’apprentissage voit un jeu d’entraînement plus riche et plus uniforme, mieux représentatif de ce qui se produit réellement dans un réseau de vidéosurveillance multi-caméras.
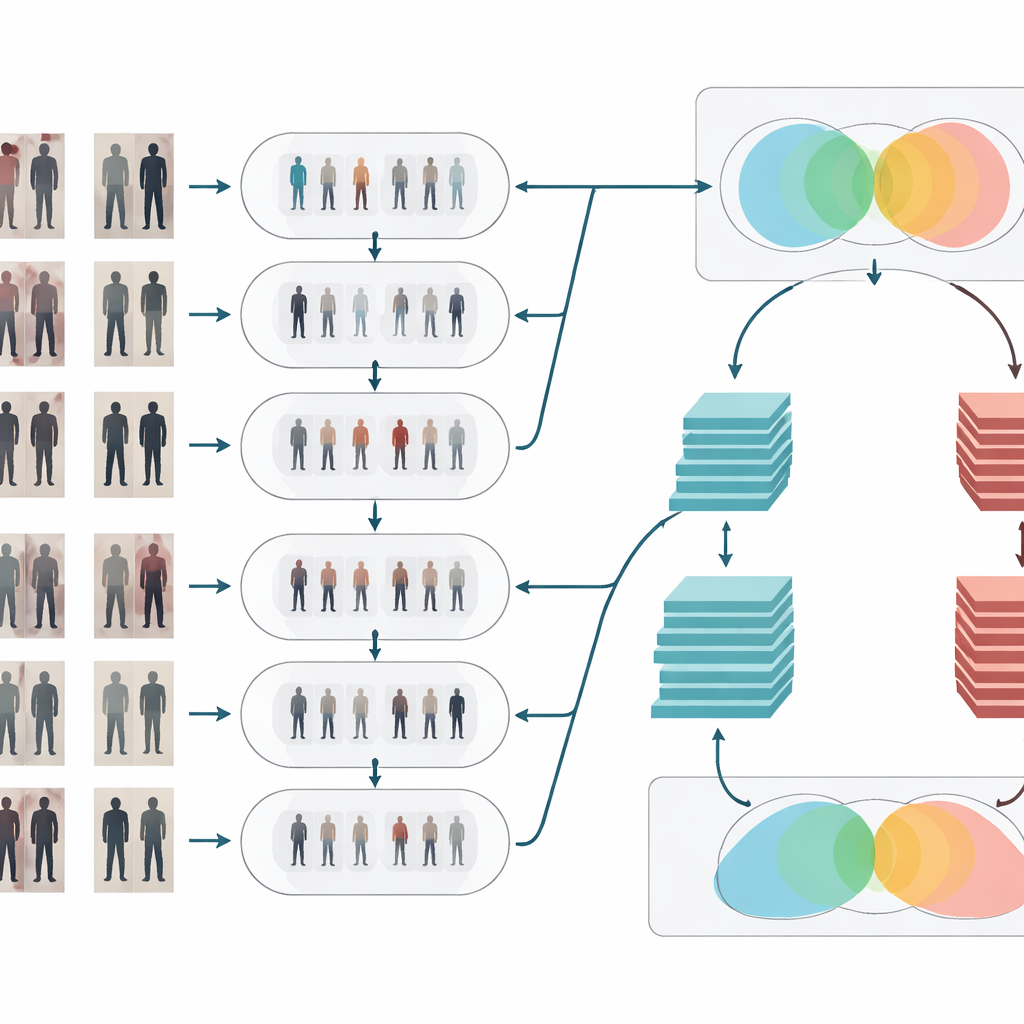
Nettoyer et clarifier le signal visuel
Après l’adaptation de style, les images passent par deux étapes classiques de nettoyage. D’abord, un filtre médian supprime les petites nuisances ponctuelles — telles que des artefacts du capteur ou des défauts de compression — tout en préservant les contours importants comme les silhouettes et les motifs de vêtements. Ensuite, une égalisation d’histogramme ajuste la distribution de la luminosité pour relever les zones sombres et atténuer les régions excessivement claires, améliorant ainsi le contraste. Ensemble, ces opérations font ressortir plus clairement et de manière plus cohérente la forme et la texture des personnes entre caméras, ce qui aide l’étape de reconnaissance à se concentrer sur des détails visuels significatifs plutôt que d’être perturbée par un mauvais éclairage ou des pixels bruités.
Deux cerveaux qui réfléchissent ensemble
Pour décider si deux images montrent la même personne, le système utilise un réseau siamois — essentiellement deux réseaux de neurones identiques partageant les mêmes poids et traitant chaque image en parallèle. Cet article renforce cette idée en dotant la structure siamoise de deux « branches » de profondeurs différentes. Une branche repose sur un modèle relativement peu profond (ResNet-50) qui capture des indices de niveau moyen tels que les régions générales de vêtements et la silhouette globale. L’autre utilise un modèle plus profond (ResNet-152) qui saisit des détails plus fins comme de subtiles plis, textures et petits accessoires. Leurs cartes de caractéristiques sont soigneusement agrégées puis combinées, de sorte que la représentation finale mêle structure générale et apparence détaillée. Le réseau calcule ensuite un score de similarité, indiquant si deux aperçus provenant de caméras différentes appartiennent probablement au même individu.
Évaluer la méthode
Les auteurs évaluent leur cadre sur un jeu de données de référence largement utilisé, composé d’images de piétons capturées par plusieurs caméras. Ils comparent leur approche à plusieurs méthodes existantes performantes, qui se concentrent soit sur le contexte caméra, des techniques de clustering ingénieuses, soit sur des conceptions siamoises classiques. Sur de nombreuses mesures de réussite — telles que la précision, la justesse et la sensibilité — le nouveau système arrive systématiquement en tête, atteignant ou dépassant parfois 99 % de précision selon certaines partitions d’entraînement et de test. Des expériences détaillées montrent également que chaque composant compte : supprimer l’augmentation par CycleGAN, le nettoyage d’image ou la conception à double branche fait chuter les performances, confirmant que les gains proviennent du fonctionnement conjoint de l’ensemble de la chaîne.
Ce que cela signifie pour la surveillance en conditions réelles
En termes concrets, cette recherche montre comment rendre les réseaux de caméras beaucoup meilleurs pour suivre des personnes dans des espaces complexes, même lorsque les conditions changent et qu’on n’a pas le temps d’annoter les données manuellement. En harmonisant l’apparence des images, en les nettoyant, puis en les comparant via un réseau jumeau soigneusement conçu, le système proposé peut reconnaître les individus de façon plus fiable à travers de nombreuses vues. Cela pourrait contribuer à des espaces publics plus sûrs et à une surveillance plus efficace, tout en soulignant l’importance d’une utilisation réfléchie et respectueuse de la vie privée de ces puissants outils d’identification.
Citation: Vidhyalakshmi, M.K., Neduncheliyan, S., Hemlathadhevi, A. et al. Enhancing single shot unsupervised domain adaptation for inter-camera person re-identification. Sci Rep 16, 11247 (2026). https://doi.org/10.1038/s41598-026-37168-9
Mots-clés: ré-identification de personnes, caméras de surveillance, apprentissage non supervisé, vision par ordinateur, réseaux de neurones profonds