Clear Sky Science · nl
Verbetering van single shot unsupervised domain adaptation voor inter-camera persoonsherkenning
Waarom slimere camera’s belangrijk zijn
Moderne steden vertrouwen op netwerken van bewakingscamera’s om mensen te beschermen, maar die camera’s “komen niet vanzelf” overeen wie wie is. Iemand kan er per camera heel anders uitzien door veranderende hoeken, schaduwen of drukte. Dit artikel pakt de uitdaging aan van het betrouwbaar volgen van dezelfde persoon over meerdere camera’s zonder veel menselijke supervisie. De auteurs ontwerpen een nieuw systeem dat camerabeelden opschoont en aanpast voordat ze vergeleken worden, waardoor digitale waakzaamheid nauwkeuriger wordt en bestaand beeldmateriaal efficiënter wordt benut.
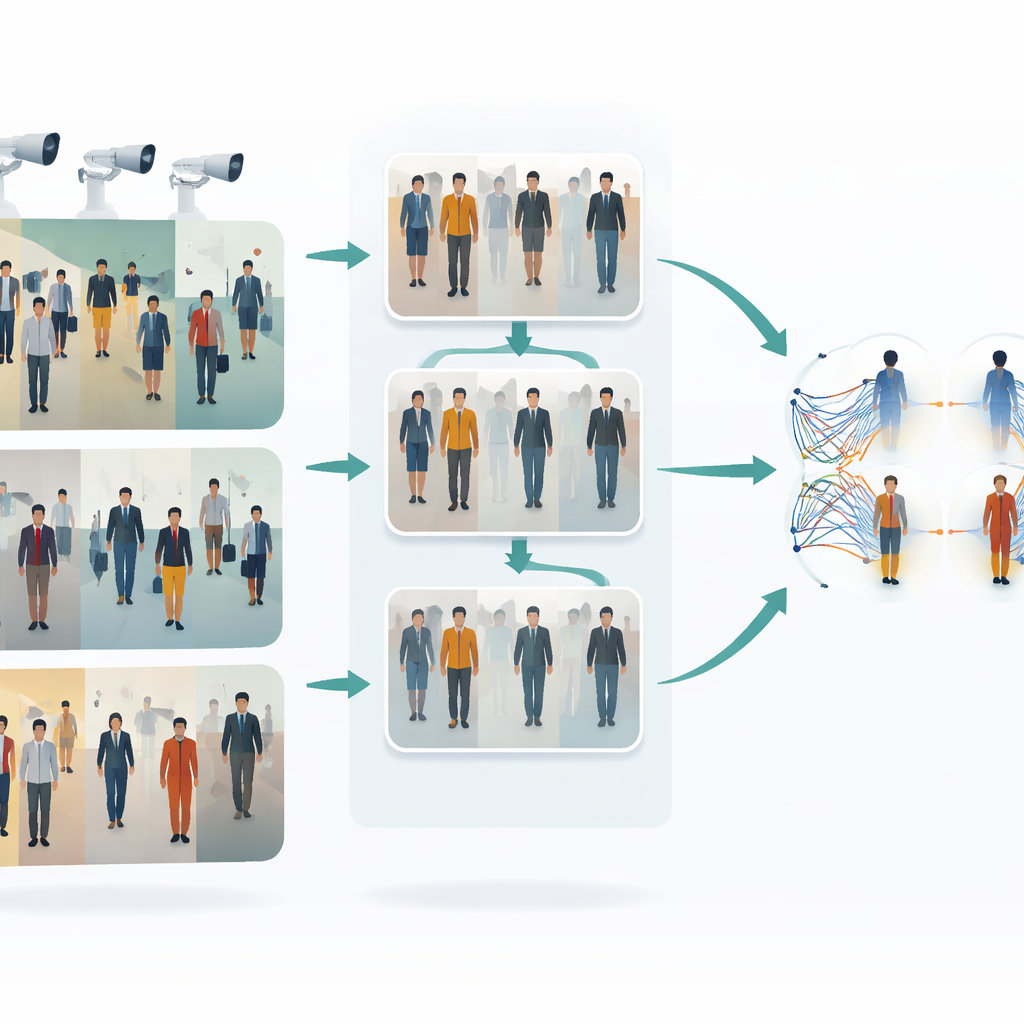
De uitdaging van het volgen van mensen over camera’s
Wanneer iemand door een treinstation, winkelcentrum of straat loopt, leggen verschillende camera’s verschillende fragmenten van die persoon vast. Kleding kan er feller of doffer uitzien, gezichten kunnen deels verborgen zijn en lichaamshoudingen veranderen voortdurend. Traditionele “single shot” methoden proberen een persoon te herkennen aan de hand van één enkele afbeelding per camera in één snelle stap, wat snel maar vaak kwetsbaar is: ze kunnen falen bij veranderend licht, wanneer iemand deels wordt geblokkeerd door anderen of wanneer camerasettings verschillen. Het handmatig labelen van duizenden afbeeldingen om een robuust systeem te trainen is duur en traag, waardoor er veel interesse is in methoden die van ongelabelde data kunnen leren en toch met deze visuele variatie kunnen omgaan.
Camera’s leren een gemeenschappelijke stijl te delen
Het eerste kernidee in dit werk is om beelden van verschillende camera’s meer op elkaar te laten lijken voordat er enige matching plaatsvindt. De auteurs gebruiken een type image-to-image vertaler genaamd CycleGAN om foto’s van de ene camera te herstylen alsof ze van een andere camera komen, zonder perfecte gepaarde voorbeelden te hoeven. Dit creëert vele nieuwe, realistische varianten van elke persoon, die verschillende gezichtspunten, belichting en achtergronden weerspiegelen. Door stijlen over camera’s te mengen en te herbalanceren, vermindert het systeem de visuele “kloof” ertussen. Als gevolg ziet het leeralgoritme een rijkere, meer uniforme trainingsset die beter vertegenwoordigt wat er werkelijk gebeurt in een multicamera-bewakingsnetwerk.
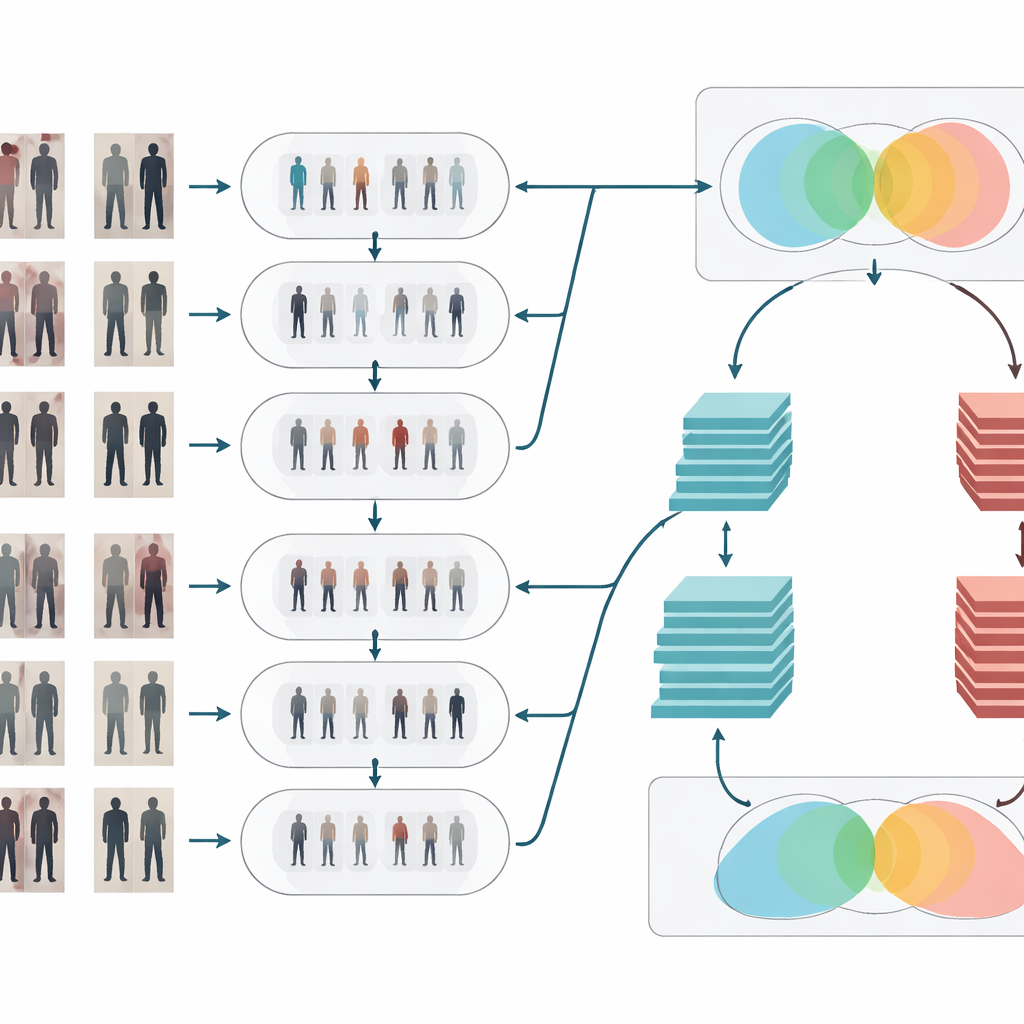
Het visuele signaal opschonen en verduidelijken
Na stijladaptatie ondergaan de beelden twee klassieke schoonmaakstappen. Ten eerste verwijdert een mediaanfilter kleine, vlekkerige ruis—zoals sensorfouten of compressieartefacten—terwijl belangrijke randen zoals lichaamscontouren en kledingpatronen scherp blijven. Ten tweede past histogramgelijkmaking (histogram equalization) de helderheidsverdeling aan zodat donkere gebieden worden opgelicht en overbelichte delen worden afgezwakt, wat het contrast verbetert. Samen zorgen deze bewerkingen ervoor dat vormen en texturen van mensen duidelijker en consistenter uitkomen over camera’s, wat de herkenningsfase helpt om zich te richten op betekenisvolle visuele details in plaats van verstoord te raken door slechte belichting of ruisende pixels.
Twee breinen die samen nadenken
Om te beslissen of twee afbeeldingen dezelfde persoon tonen, gebruikt het systeem een Siamese netwerk—in wezen twee identieke neurale netwerken die gewichten delen en elk beeld parallel verwerken. Dit artikel versterkt dat idee door het Siamese ontwerp twee “takken” met verschillende dieptes te geven. De ene tak is gebaseerd op een relatief ondiep model (ResNet-50) dat mid-level cues vastlegt zoals algemene kledingzones en de globale lichaamssilhouet. De andere gebruikt een dieper model (ResNet-152) dat fijnere details oppikt, zoals subtiele plooien, texturen en kleine accessoires. Hun featuremaps worden zorgvuldig gepooled en daarna gecombineerd, zodat de uiteindelijke representatie brede structuur en fijnkorrelige verschijningskenmerken mengt. Het netwerk berekent vervolgens een gelijkenheidsscore die aangeeft of twee fragmenten uit verschillende camera’s waarschijnlijk tot dezelfde persoon behoren.
De methode op de proef stellen
De auteurs evalueren hun raamwerk op een veelgebruikt benchmark-dataset van voetgangersbeelden vastgelegd door meerdere camera’s. Ze vergelijken hun aanpak met verschillende sterke bestaande methoden die zich richten op camera-context, slimme clustering of traditionele Siamese ontwerpen. Over veel succesmaatstaven—zoals nauwkeurigheid, precisie en sensitiviteit—komt het nieuwe systeem consequent als winnaar uit de bus en bereikt het in sommige train–test-splitsingen bijna of meer dan 99% nauwkeurigheid. Gedetailleerde experimenten tonen ook aan dat elk onderdeel van belang is: het weglaten van CycleGAN-augmentatie, de beeldopschoning of het tweetak-ontwerp laat de prestaties dalen, wat bevestigt dat de winst voortkomt uit de volledige pijplijn die samenwerkt.
Wat dit betekent voor surveillance in de praktijk
In dagelijkse termen laat dit onderzoek zien hoe cameranetwerken veel beter kunnen worden in het volgen van mensen terwijl ze door complexe ruimtes bewegen, zelfs als omstandigheden veranderen en er niemand tijd heeft om data met de hand te labelen. Door het uiterlijk van beelden te harmoniseren, ze op te schonen en daarna te vergelijken met een zorgvuldig ontworpen tweeling-netwerk, kan het voorgestelde systeem individuen betrouwbaarder herkennen over veel camerabeelden. Dit kan bijdragen aan veiligere openbare ruimten en efficiëntere bewaking, terwijl het ook het belang benadrukt van doordacht en privacybewust gebruik van zulke krachtige identificatietechnologieën.
Bronvermelding: Vidhyalakshmi, M.K., Neduncheliyan, S., Hemlathadhevi, A. et al. Enhancing single shot unsupervised domain adaptation for inter-camera person re-identification. Sci Rep 16, 11247 (2026). https://doi.org/10.1038/s41598-026-37168-9
Trefwoorden: person re-identification, surveillance cameras, unsupervised learning, computer vision, deep neural networks