Clear Sky Science · de
Verbesserung der einmaligen unbeaufsichtigten Domänenanpassung für die personenübergreifende Re-Identifikation über Kameras
Warum klügere Kameras wichtig sind
Moderne Städte verlassen sich auf Netzwerke von Sicherheitskameras, um Menschen zu schützen, doch diese Kameras „stimmen“ nicht automatisch darin überein, wer wer ist. Dieselbe Person kann von einer Kamera zur nächsten sehr unterschiedlich aussehen, etwa wegen wechselnder Blickwinkel, Schatten oder dichter Menschenmengen. Dieses Papier behandelt die Herausforderung, dieselbe Person über viele Kameras hinweg zuverlässig zu verfolgen, ohne aufwändige menschliche Aufsicht. Die Autorinnen und Autoren entwickeln ein neues System, das Kamerabilder vor dem Vergleich bereinigt und anpasst, sodass digitale Beobachtung genauer wird und vorhandenes Filmmaterial effizienter genutzt werden kann.
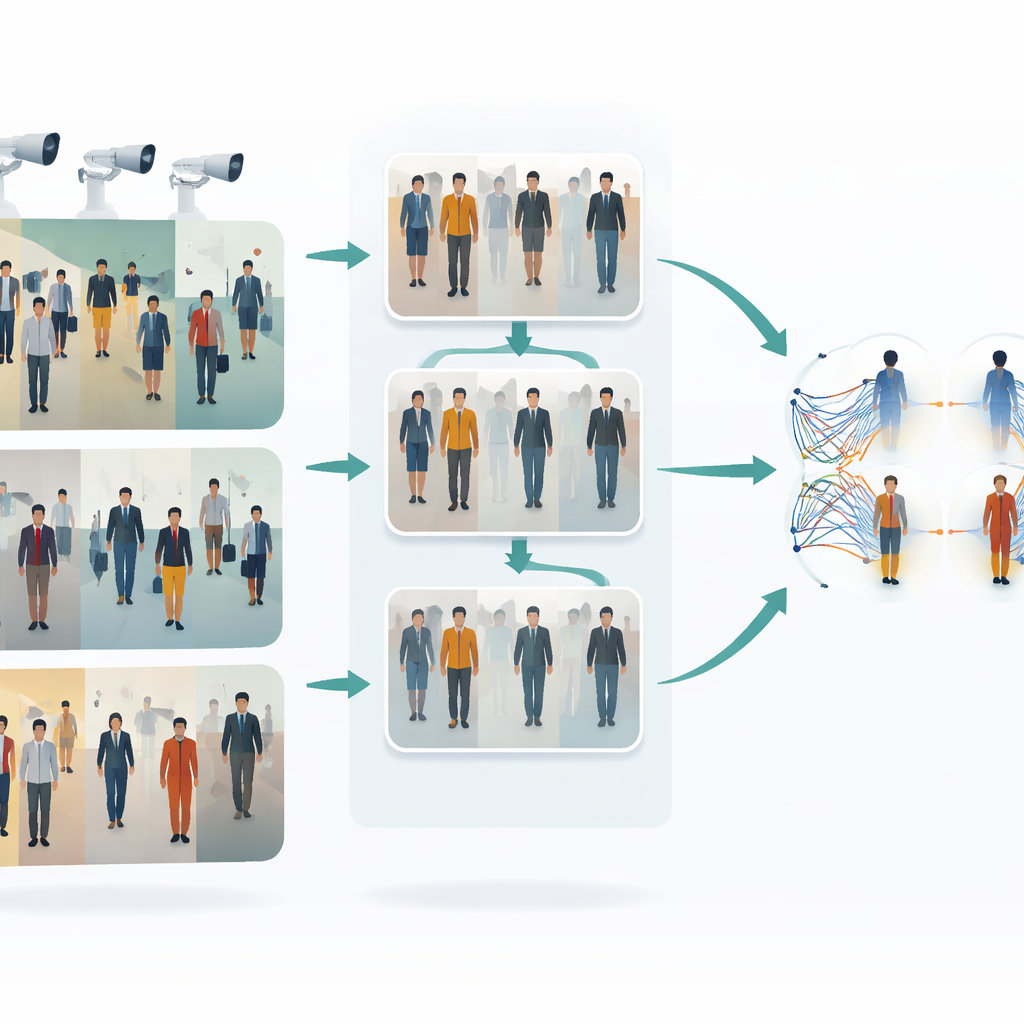
Die Schwierigkeit, Personen über Kameras hinweg zu verfolgen
Wenn jemand durch einen Bahnhof, ein Einkaufszentrum oder ein Straßennetz läuft, erfassen verschiedene Kameras unterschiedliche Ausschnitte. Kleidung kann heller oder dunkler wirken, Gesichter teilweise verdeckt sein und Körperhaltungen sich ständig ändern. Traditionelle „Single-Shot“-Methoden versuchen, eine Person anhand eines einzelnen Bildes pro Kamera in einem schnellen Durchgang zu erkennen; das ist zwar schnell, aber oft anfällig: Sie versagen bei Lichtwechseln, wenn Personen teilweise verdeckt sind oder wenn Kameraeinstellungen variieren. Tausende Bilder manuell zu labeln, um ein robustes System zu trainieren, ist teuer und zeitaufwändig, daher besteht großes Interesse an Methoden, die aus unlabeled Daten lernen können und dennoch mit dieser visuellen Vielfalt zurechtkommen.
Kameras beibringen, einen gemeinsamen Stil zu teilen
Die erste Schlüsselidee dieser Arbeit ist, Bilder verschiedener Kameras vor dem Abgleich einander ähnlicher zu machen. Die Autorinnen und Autoren verwenden einen Bild-zu-Bild-Übersetzer des Typs CycleGAN, um Aufnahmen einer Kamera so umzustylen, als kämen sie von einer anderen, ohne perfekt gepaarte Beispiele zu benötigen. Das erzeugt viele neue, realistische Varianten jeder Person, die unterschiedliche Blickwinkel, Beleuchtungen und Hintergründe widerspiegeln. Durch das Mischen und Ausbalancieren von Stilen zwischen Kameras verringert das System die visuelle „Lücke“ zwischen ihnen. Infolgedessen sieht der Lernalgorithmus einen reichhaltigeren, einheitlicheren Trainingssatz, der besser abbildet, was in einem Multi-Kamera-Überwachungsnetz tatsächlich vorkommt.
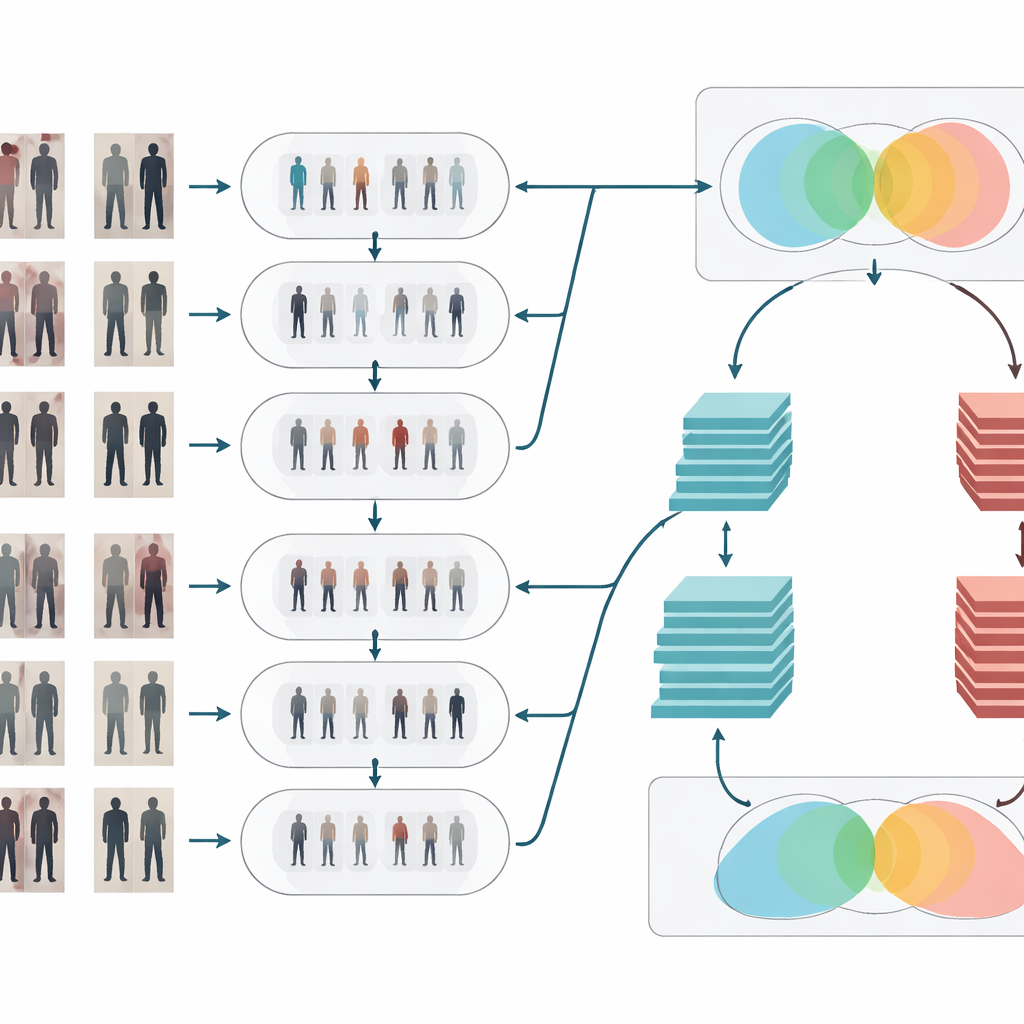
Den visuellen Signalfluss säubern und klären
Nach der Stiladaptation durchlaufen die Bilder zwei klassische Bereinigungsschritte. Zuerst entfernt ein Medianfilter kleine, punktartige Störungen—etwa Sensorartefakte oder Kompressionsfehler—während wichtige Kanten wie Körperkonturen und Muster in der Kleidung scharf bleiben. Danach gleicht die Histogrammkorrektur die Helligkeitsverteilung an, sodass zu dunkle Bereiche aufgehellt und überbelichtete Partien abgeschwächt werden, was den Kontrast verbessert. Zusammen lassen diese Operationen Formen und Texturen von Personen klarer und konstanter über Kameras hinweg hervortreten, wodurch die Erkennungsphase sich auf sinnvolle visuelle Details konzentrieren kann statt von schlechtem Licht oder verrauschten Pixeln verwirrt zu werden.
Zwei Gehirne, die zusammendenken
Um zu entscheiden, ob zwei Bilder dieselbe Person zeigen, verwendet das System ein Siamese-Netzwerk—im Grunde zwei identische neuronale Netze, die Gewichte teilen und jedes Bild parallel verarbeiten. Diese Arbeit stärkt die Idee, indem das Siamese-Design zwei „Zweige“ mit unterschiedlicher Tiefe erhält. Ein Zweig basiert auf einem relativ flachen Modell (ResNet-50), das mittlere Hinweise wie allgemeine Kleidungsregionen und die grobe Körperform erfasst. Der andere nutzt ein tieferes Modell (ResNet-152), das feinere Details wie subtile Falten, Texturen und kleine Accessoires aufnimmt. Deren Merkmalmaps werden sorgfältig gepoolt und dann kombiniert, sodass die finale Repräsentation breite Struktur mit feingranulärem Erscheinungsbild verbindet. Das Netzwerk berechnet anschließend einen Ähnlichkeitswert, der angibt, ob zwei Aufnahmen aus verschiedenen Kameras wahrscheinlich zur selben Person gehören.
Das Verfahren auf die Probe stellen
Die Autorinnen und Autoren evaluieren ihr Framework an einem weit verbreiteten Benchmark-Datensatz von Pedestrian-Bildern, die von mehreren Kameras aufgenommen wurden. Sie vergleichen ihren Ansatz mit mehreren starken bestehenden Methoden, die sich entweder auf Kamerakontext, clevere Clusterbildung oder traditionelle Siamese-Designs konzentrieren. Über viele Erfolgsmaße hinweg—wie Genauigkeit, Präzision und Sensitivität—schneidet das neue System durchgängig am besten ab und erreicht je nach Train–Test-Aufteilung teils nahezu oder über 99% Genauigkeit. Detaillierte Experimente zeigen außerdem, dass jede Komponente eine Rolle spielt: Das Entfernen der CycleGAN-Augmentierung, der Bildbereinigung oder des Dual-Branch-Designs verringert die Performance und bestätigt, dass die Verbesserungen aus dem Zusammenwirken der gesamten Pipeline resultieren.
Was das für die reale Überwachung bedeutet
Alltagsnah zeigt diese Forschung, wie Kameranetze deutlich besser darin werden können, Personen beim Bewegen durch komplexe Räume zu verfolgen, selbst wenn sich Bedingungen ändern und niemand Zeit hat, Daten manuell zu labeln. Indem die Optik der Bilder harmonisiert, bereinigt und dann mit einem sorgfältig gestalteten Zwillingsnetz verglichen wird, kann das vorgeschlagene System Individuen über viele Kameras hinweg verlässlicher erkennen. Das könnte zu sichereren öffentlichen Räumen und effizienterer Überwachung beitragen, weist aber zugleich auf die Bedeutung eines durchdachten, datenschutzbewussten Einsatzes dieser leistungsstarken Identifikationswerkzeuge hin.
Zitation: Vidhyalakshmi, M.K., Neduncheliyan, S., Hemlathadhevi, A. et al. Enhancing single shot unsupervised domain adaptation for inter-camera person re-identification. Sci Rep 16, 11247 (2026). https://doi.org/10.1038/s41598-026-37168-9
Schlüsselwörter: Personenre-Identifikation, Überwachungskameras, unüberwachtes Lernen, Computer Vision, tiefe neuronale Netze