Clear Sky Science · it
Migliorare l'adattamento non supervisionato single-shot per la re-identificazione di persone tra telecamere
Perché telecamere più intelligenti contano
Le città moderne fanno affidamento su reti di telecamere di sicurezza per contribuire a mantenere le persone al sicuro, ma quelle telecamere non “si mettono automaticamente d'accordo” su chi sia chi. Una persona può apparire molto diversa da una telecamera all'altra a causa di angolazioni variabili, ombre o affollamento. Questo articolo affronta la sfida di seguire in modo affidabile la stessa persona attraverso molte telecamere senza pesante supervisione umana. Gli autori progettano un nuovo sistema che pulisce e adatta le immagini delle telecamere prima di confrontarle, rendendo la sorveglianza digitale più precisa e sfruttando in modo più efficiente le registrazioni esistenti.
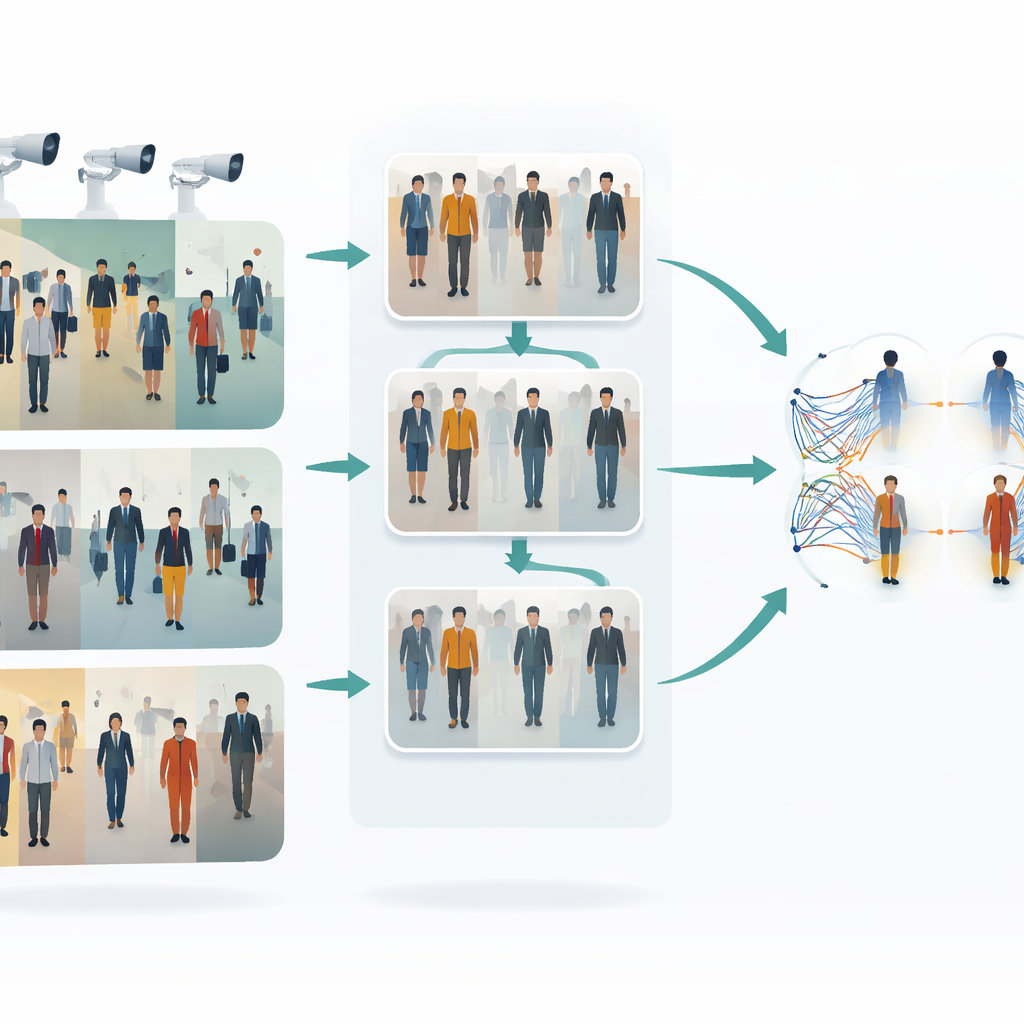
La sfida di seguire le persone tra le telecamere
Quando una persona attraversa una stazione, un centro commerciale o una rete stradale, diverse telecamere la catturano in modi differenti. I vestiti possono sembrare più chiari o più spenti, i volti possono essere parzialmente nascosti e le pose del corpo cambiano continuamente. I metodi tradizionali “single shot” cercano di riconoscere una persona a partire da una singola immagine per telecamera in un unico passaggio rapido, il che è veloce ma spesso fragile: possono fallire quando cambia l'illuminazione, quando qualcuno è parzialmente coperto da altri o quando le impostazioni delle telecamere differiscono. Etichettare migliaia di immagini a mano per addestrare un sistema robusto è costoso e lento, perciò c'è grande interesse per metodi che possano imparare da dati non etichettati pur gestendo questa ampia varietà visiva.
Insegnare alle telecamere a condividere uno stile comune
La prima idea chiave in questo lavoro è rendere le immagini provenienti da telecamere diverse più simili prima di tentare qualsiasi confronto. Gli autori usano un tipo di traduttore immagine-a-immagine chiamato CycleGAN per prendere immagini di una telecamera e restilarle come se provenissero da un'altra, senza bisogno di esempi perfettamente abbinati. Questo crea molte nuove varianti realistiche di ogni persona, che riflettono differenti punti di vista, illuminazione e sfondi. Bilanciando e fondendo gli stili tra le telecamere, il sistema riduce il “gap” visivo tra di esse. Di conseguenza, l'algoritmo di apprendimento vede un insieme di addestramento più ricco e uniforme che rappresenta meglio ciò che accade realmente in una rete di sorveglianza multi-camera.
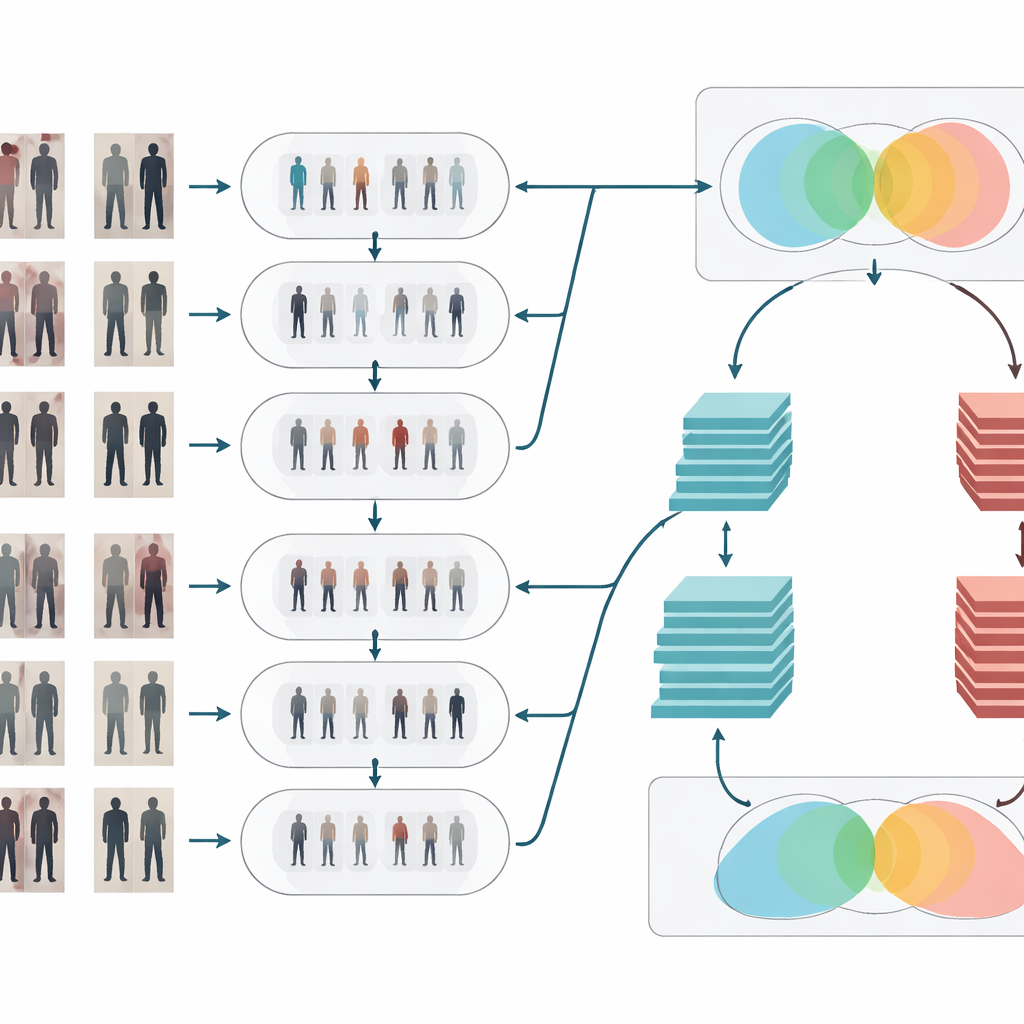
Pulire e chiarificare il segnale visivo
Dopo l'adattamento dello stile, le immagini passano attraverso due classiche fasi di pulizia. Primo, un filtro mediano rimuove piccoli rumori a macchia—come artefatti del sensore o problemi di compressione—mantenendo però nitidi i bordi importanti come i contorni del corpo e i pattern degli abiti. Secondo, l'egualizzazione dell'istogramma regola la distribuzione di luminosità in modo che le regioni scure vengano illuminate e le aree eccessivamente chiare vengano attenuate, migliorando il contrasto. Insieme, queste operazioni fanno risaltare forme e texture delle persone in modo più chiaro e coerente tra le telecamere, aiutando la fase di riconoscimento a concentrarsi sui dettagli visivi significativi invece di essere confusa da scarsa illuminazione o pixel rumorosi.
Due cervelli che ragionano insieme
Per decidere se due immagini mostrano la stessa persona, il sistema utilizza una rete Siamese—essenzialmente due reti neurali identiche che condividono pesi e processano ciascuna immagine in parallelo. Questo articolo rafforza quell'idea dotando il design Siamese di due “rami” con profondità diverse. Un ramo si basa su un modello relativamente poco profondo (ResNet-50) che cattura indizi di livello medio come regioni generali dei vestiti e forma complessiva del corpo. L'altro utilizza un modello più profondo (ResNet-152) che coglie dettagli più fini come pieghe sottili, texture e piccoli accessori. Le loro mappe di caratteristiche vengono accuratamente poolate e poi combinate, così la rappresentazione finale fonde struttura ampia e aspetto fine. La rete calcola quindi un punteggio di similarità, che indica se due istantanee provenienti da telecamere diverse probabilmente appartengono allo stesso individuo.
Mettere il metodo alla prova
Gli autori valutano il loro framework su un dataset di riferimento ampiamente usato di immagini di pedoni catturate da più telecamere. Confrontano il loro approccio con diversi metodi consolidati che si concentrano sul contesto delle telecamere, su clustering intelligenti o su design Siamese tradizionali. Su molte misure di successo—come accuratezza, precisione e sensibilità—il nuovo sistema risulta costantemente al top, avvicinandosi o superando il 99% di accuratezza in alcune divisioni train–test. Esperimenti dettagliati mostrano inoltre che ogni componente è importante: rimuovere l'aumento tramite CycleGAN, la pulizia delle immagini o il design a doppio ramo peggiora le prestazioni, confermando che i miglioramenti derivano dal funzionamento congiunto dell'intera pipeline.
Cosa significa per la sorveglianza nel mondo reale
In termini pratici, questa ricerca mostra come rendere le reti di telecamere molto migliori nel tracciare le persone mentre si muovono in spazi complessi, anche quando le condizioni cambiano e nessuno ha tempo di etichettare i dati a mano. Armonizzando l'aspetto delle immagini, pulendole e poi confrontandole con una rete gemella progettata con cura, il sistema proposto può riconoscere gli individui in modo più affidabile attraverso molte viste di telecamere. Ciò potrebbe supportare spazi pubblici più sicuri e una sorveglianza più efficiente, evidenziando al contempo l'importanza di un uso ponderato e rispettoso della privacy di questi potenti strumenti di identificazione.
Citazione: Vidhyalakshmi, M.K., Neduncheliyan, S., Hemlathadhevi, A. et al. Enhancing single shot unsupervised domain adaptation for inter-camera person re-identification. Sci Rep 16, 11247 (2026). https://doi.org/10.1038/s41598-026-37168-9
Parole chiave: re-identificazione di persone, telecamere di sorveglianza, apprendimento non supervisionato, visione artificiale, reti neurali profonde