Clear Sky Science · pl
Udoskonalanie jednorazowej, niesuperwizowanej adaptacji domeny dla międzykamerowej re-identyfikacji osób
Dlaczego mądrzejsze kamery mają znaczenie
Współczesne miasta opierają się na sieciach kamer bezpieczeństwa, które pomagają chronić ludzi, lecz kamery te nie „zgadzają się” automatycznie co do tożsamości obserwowanych osób. Ta sama osoba może wyglądać zupełnie inaczej w kolejnych ujęciach z powodu zmieniających się kątów, cieni czy tłumu. Artykuł podejmuje wyzwanie niezawodnego śledzenia tej samej osoby w wielu kamerach bez szerokiego nadzoru człowieka. Autorzy proponują nowy system, który oczyszcza i adaptuje obrazy z kamer przed ich porównaniem, poprawiając cyfrową czujność i efektywniej wykorzystując istniejące nagrania.
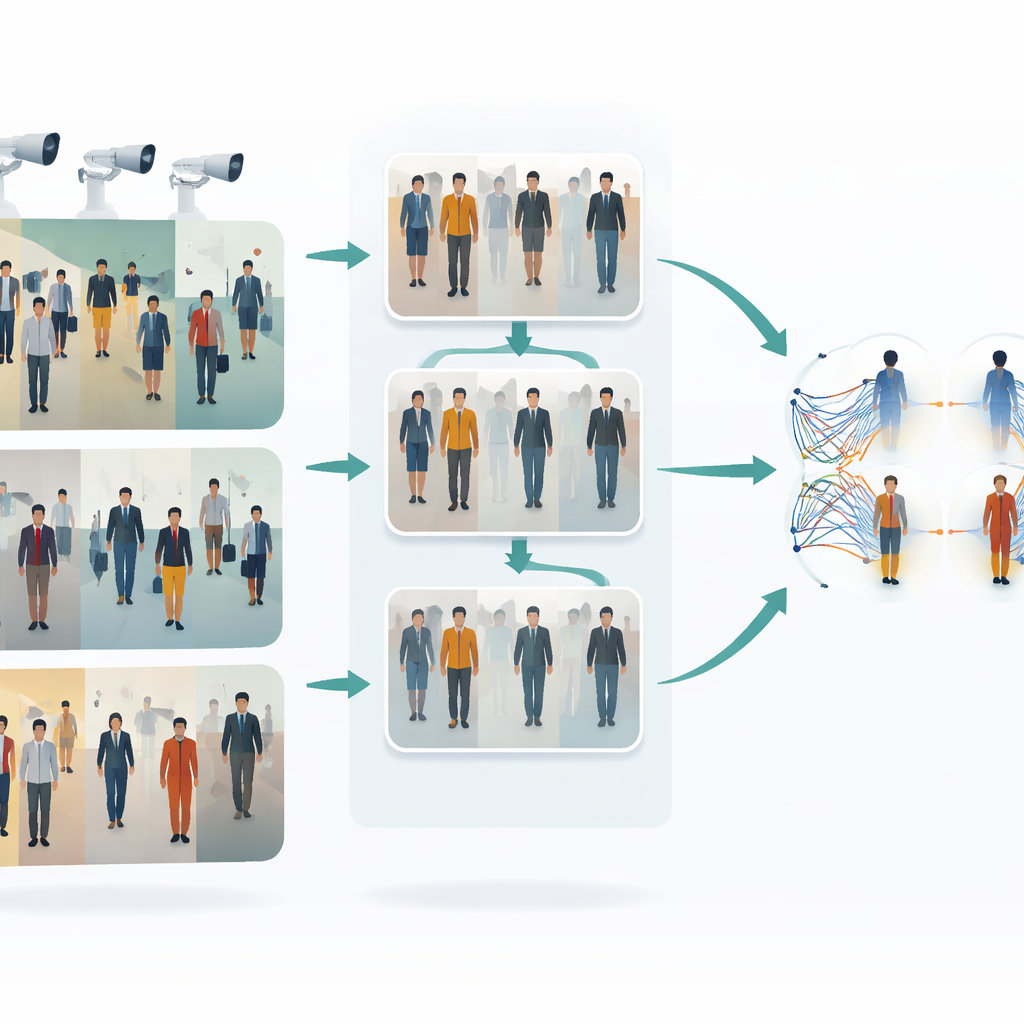
Wyzwanie śledzenia osób między kamerami
Kiedy osoba przechodzi przez dworzec, centrum handlowe czy sieć ulic, różne kamery rejestrują różne przebłyski jej wyglądu. Ubrania mogą wydawać się jaśniejsze lub ciemniejsze, twarze mogą być częściowo zasłonięte, a pozy ciała ciągle się zmieniają. Tradycyjne metody „single shot” próbują rozpoznać osobę na podstawie pojedynczego obrazu z każdej kamery w jednym szybkim przebiegu — to jest szybkie, ale często kruche: zawodzi przy zmianach oświetlenia, przy częściowym zasłonięciu lub gdy ustawienia kamer się różnią. Ręczne oznaczanie tysięcy obrazów do trenowania odpornego systemu jest kosztowne i czasochłonne, więc duże zainteresowanie budzą metody potrafiące uczyć się z nieoznakowanych danych, a jednocześnie radzić sobie z tak dużą zmiennością wizualną.
Nauczanie kamer wspólnego stylu
Pierwszy kluczowy pomysł w tej pracy to ujednolicenie wyglądu obrazów z różnych kamer zanim podejmie się ich porównanie. Autorzy używają typu translatora obraz–obraz nazwanego CycleGAN, aby przekształcić zdjęcia z jednej kamery tak, by wyglądały, jakby pochodziły z innej, bez potrzeby parowania przykładów. To tworzy wiele nowych, realistycznych wariantów każdej osoby, odzwierciedlając różne punkty widzenia, oświetlenie i tła. Poprzez mieszanie i wyrównywanie stylów między kamerami system zmniejsza wizualną „przepaść” między nimi. W rezultacie algorytm uczący widzi bogatszy, bardziej jednorodny zestaw treningowy, który lepiej reprezentuje to, co faktycznie dzieje się w wielokamerowej sieci nadzoru.
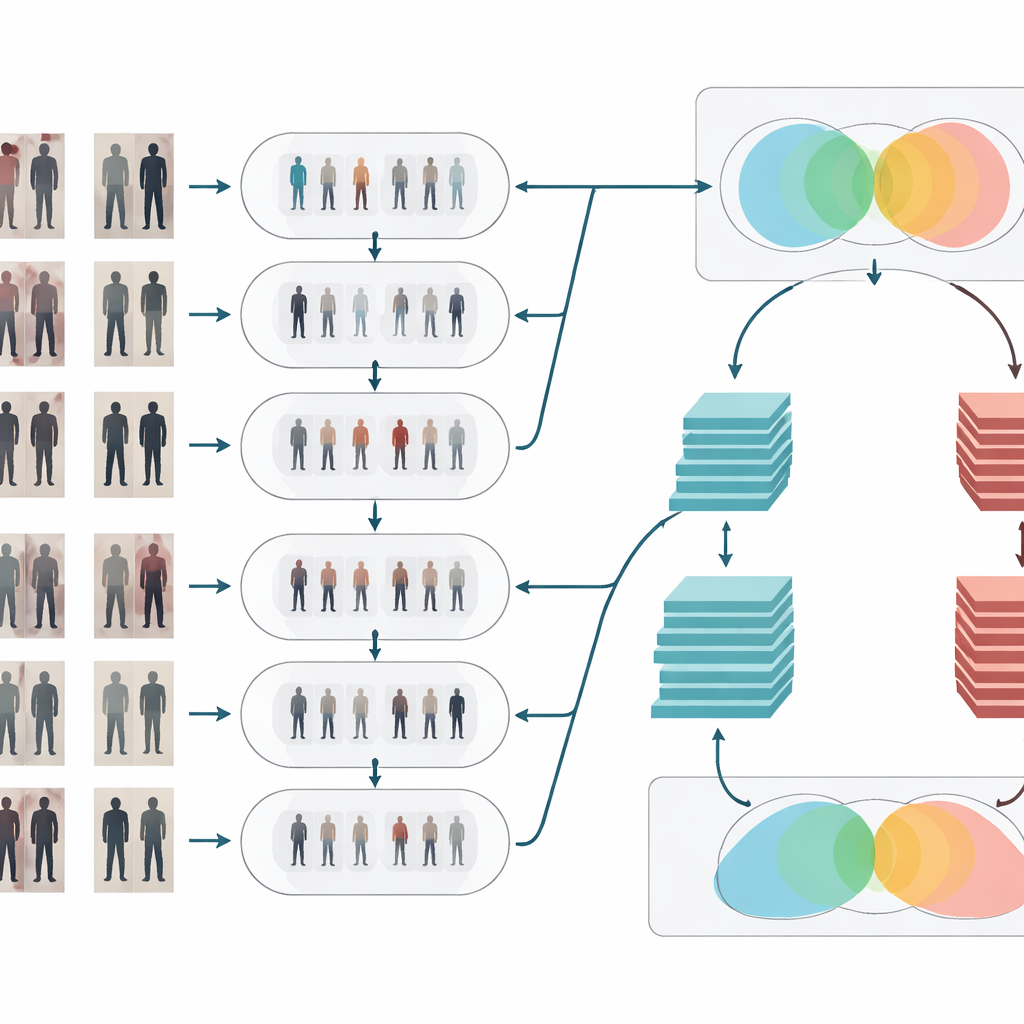
Oczyszczanie i uwydatnianie sygnału wizualnego
Po adaptacji stylu obrazy przechodzą przez dwa klasyczne etapy czyszczenia. Najpierw filtr medianowy usuwa drobne, plamiste zakłócenia — takie jak artefakty czujnika czy błędy kompresji — jednocześnie zachowując istotne krawędzie, jak kontury ciała i wzory ubrań. Następnie wyrównanie histogramu koryguje rozkład jasności tak, aby przyciemnione obszary zostały rozjaśnione, a zbyt jasne strefy przygaszone, co poprawia kontrast. Razem te operacje sprawiają, że kształty i tekstury osób wyróżniają się wyraźniej i bardziej spójnie między kamerami, co pomaga etapowi rozpoznawania skupić się na znaczących szczegółach wizualnych zamiast być zmylanym przez słabe oświetlenie czy zaszumione piksele.
Dwa mózgi myślące wspólnie
Aby zdecydować, czy dwa obrazy pokazują tę samą osobę, system wykorzystuje sieć syjamską — w gruncie rzeczy dwie identyczne sieci neuronowe dzielące wagi i przetwarzające każdy obraz równolegle. W pracy tej pomysł ten zostaje wzmocniony poprzez wyposażenie architektury syjamskiej w dwa „odgałęzienia” o różnej głębokości. Jedno odgałęzienie opiera się na stosunkowo płytkim modelu (ResNet-50), który wychwytuje średnio-poziomowe cechy, takie jak ogólne obszary ubioru i kształt sylwetki. Drugie korzysta z głębszego modelu (ResNet-152), który ujmuje drobniejsze detale, jak subtelne fałdy, faktury i małe dodatki. Ich mapy cech są starannie agregowane i łączone, tak że końcowa reprezentacja łączy szeroką strukturę z drobnoziarnistym wyglądem. Sieć oblicza następnie miarę podobieństwa, wskazując, czy dwa przebłyski z różnych kamer najprawdopodobniej należą do tej samej osoby.
Próba metody w praktyce
Autorzy ocenili swoją ramę na szeroko stosowanym zestawie benchmarkowym obrazów pieszych rejestrowanych przez wiele kamer. Porównali swoje podejście z kilkoma silnymi istniejącymi metodami, które koncentrują się albo na kontekście kamery, sprytnym grupowaniu (clusteringu), albo tradycyjnych projektach syjamskich. W wielu miarach sukcesu — takich jak dokładność, precyzja i czułość — nowy system konsekwentnie wychodzi na prowadzenie, zbliżając się do lub przewyższając 99% dokładności dla niektórych podziałów trening–test. Szczegółowe eksperymenty pokazują także, że każdy element ma znaczenie: usunięcie augmentacji CycleGAN, procedur czyszczenia obrazu lub projektu z dwoma odgałęzieniami obniża wydajność, co potwierdza, że zyski wynikają z działania całego potoku razem.
Co to oznacza dla nadzoru w świecie rzeczywistym
Mówiąc prościej, badanie to pokazuje, jak uczynić sieci kamer znacznie lepszymi w śledzeniu ludzi poruszających się po złożonych przestrzeniach, nawet gdy warunki się zmieniają, a nikt nie ma czasu na ręczne oznaczanie danych. Poprzez harmonizację wyglądu obrazów, ich oczyszczanie i porównywanie za pomocą starannie zaprojektowanej sieci bliźniaczej, proponowany system potrafi rozpoznawać osoby bardziej niezawodnie w wielu widokach kamer. Może to wspierać bezpieczniejsze przestrzenie publiczne i bardziej efektywny monitoring, jednocześnie podkreślając potrzebę przemyślanego, z poszanowaniem prywatności stosowania tak potężnych narzędzi identyfikacji.
Cytowanie: Vidhyalakshmi, M.K., Neduncheliyan, S., Hemlathadhevi, A. et al. Enhancing single shot unsupervised domain adaptation for inter-camera person re-identification. Sci Rep 16, 11247 (2026). https://doi.org/10.1038/s41598-026-37168-9
Słowa kluczowe: re-identyfikacja osób, kamery nadzoru, uczenie niesuperwizowane, widzenie komputerowe, głębokie sieci neuronowe